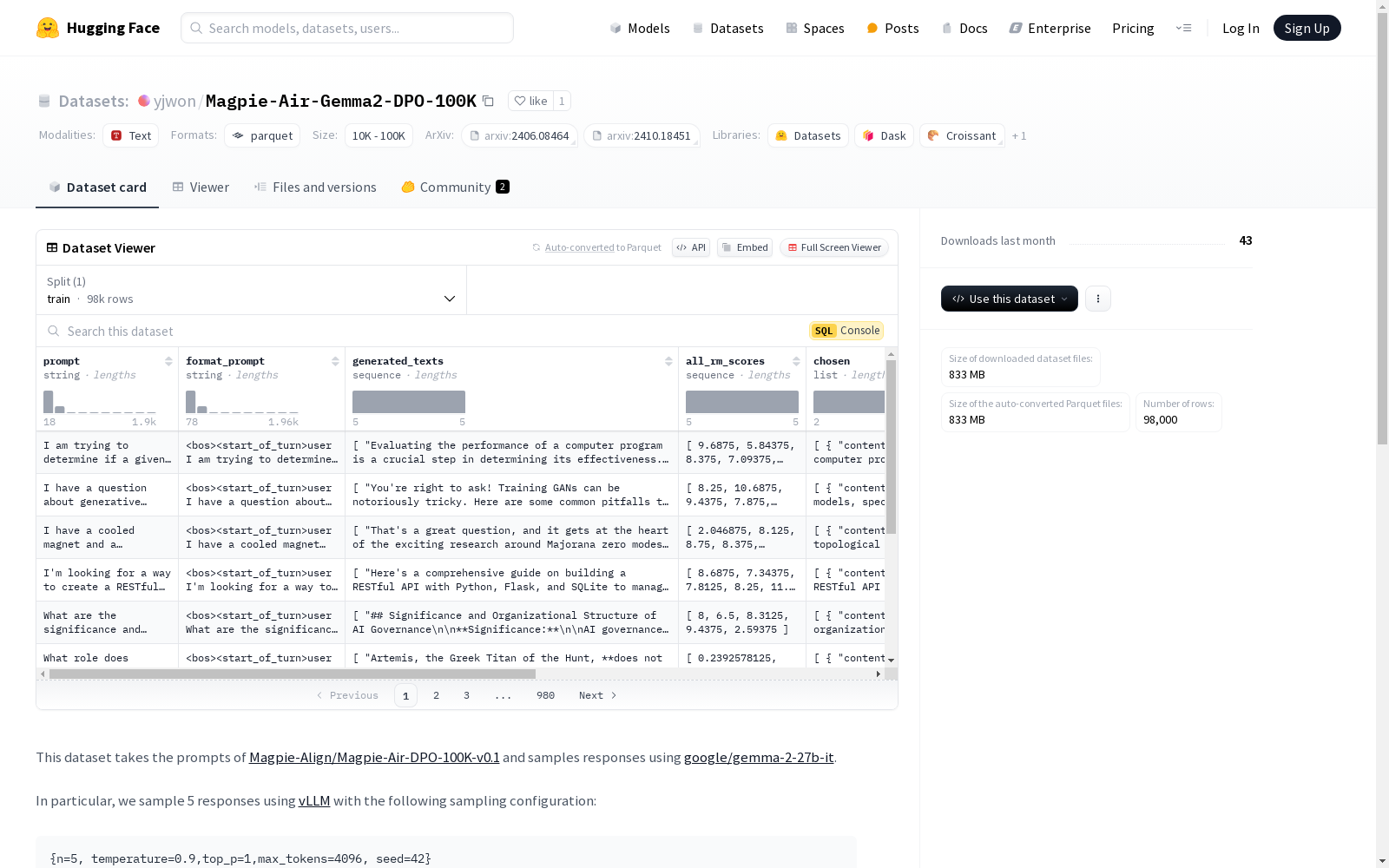
Magpie-Air-Gemma2-DPO-100K
收藏Magpie-Air-Gemma2-DPO-100K 数据集概述
数据集信息
-
特征:
prompt: 字符串类型format_prompt: 字符串类型generated_texts: 字符串序列all_rm_scores: 浮点数序列chosen: 列表类型,包含content和role,均为字符串类型rejected: 列表类型,包含content和role,均为字符串类型
-
分割:
train: 包含 98000 个样本,占用 1658751815 字节
-
下载大小: 833156062 字节
-
数据集大小: 1658751815 字节
配置
- 配置名称:
default - 数据文件:
train: 路径为data/train-*
数据生成过程
- 基于 Magpie-Align/Magpie-Air-DPO-100K-v0.1 的提示,使用 google/gemma-2-27b-it 生成响应。
- 使用 vLLM 进行采样,配置为
{n=5, temperature=0.9, top_p=1, max_tokens=4096, seed=42}。 - 使用 Skywork/Skywork-Reward-Gemma-2-27B-v0.2 奖励模型选择最佳和最差的样本作为
chosen和rejected响应。
引用
-
使用此数据集时,请引用以下文献:
@article{xu2024magpie, title={Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing}, author={Zhangchen Xu and Fengqing Jiang and Luyao Niu and Yuntian Deng and Radha Poovendran and Yejin Choi and Bill Yuchen Lin}, year={2024}, eprint={2406.08464}, archivePrefix={arXiv}, primaryClass={cs.CL} } @article{liu2024skywork, title={Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs}, author={Liu, Chris Yuhao and Zeng, Liang and Liu, Jiacai and Yan, Rui and He, Jujie and Wang, Chaojie and Yan, Shuicheng and Liu, Yang and Zhou, Yahui}, journal={arXiv preprint arXiv:2410.18451}, year={2024} } @article{gemma_2024, title={Gemma}, url={https://www.kaggle.com/m/3301}, DOI={10.34740/KAGGLE/M/3301}, publisher={Kaggle}, author={Gemma Team}, year={2024} }