imputed-jst
收藏Hugging Face2025-08-12 更新2025-08-13 收录
下载链接:
https://huggingface.co/datasets/arushisinha98/imputed-jst
下载链接
链接失效反馈官方服务:
资源简介:
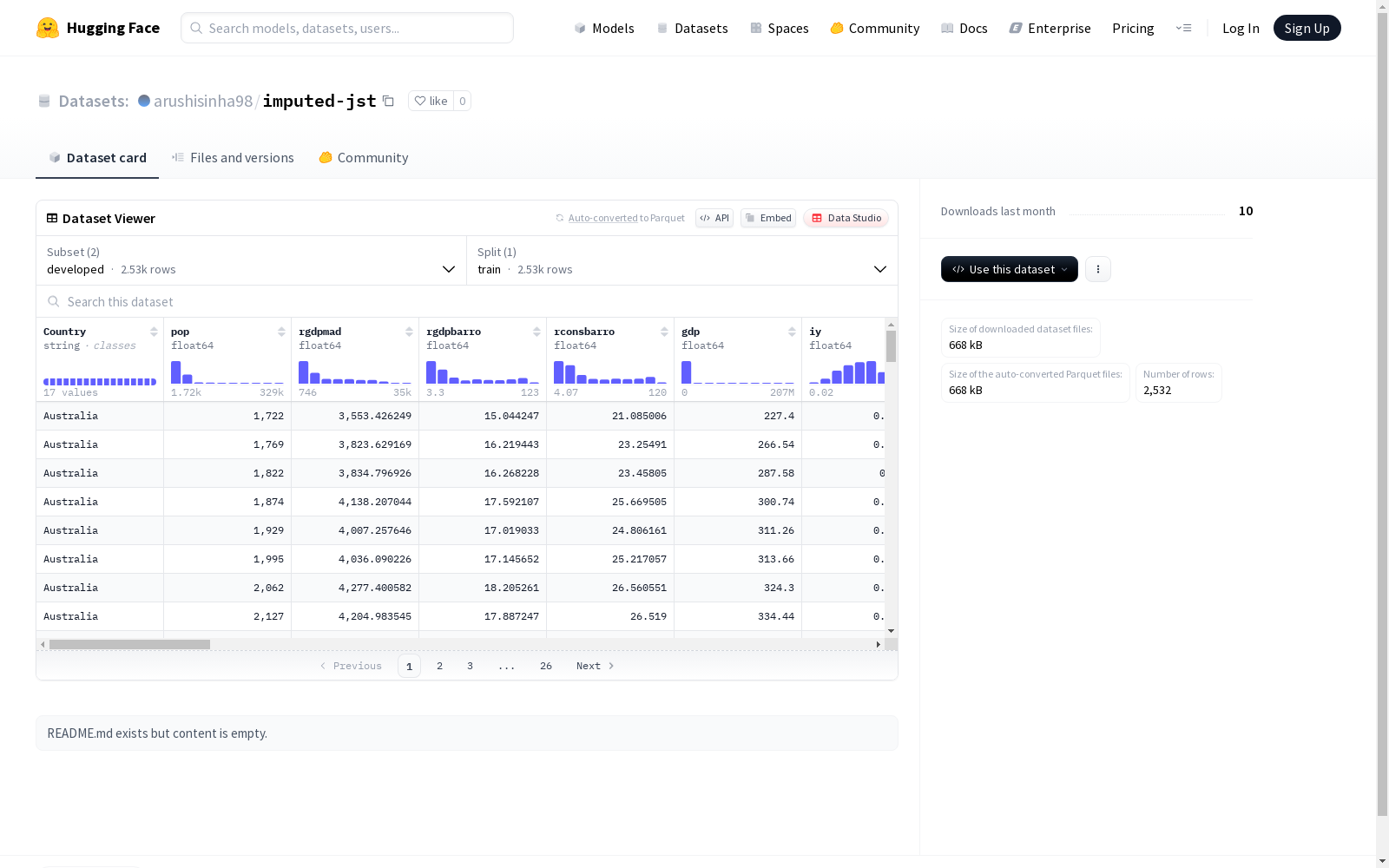
该数据集包含两种配置:'developed'和'emerging'。'developed'配置中包含各种经济特征,如国家、人口、GDP等,以及训练集的详细信息。而'emerging'配置没有数据,如字节数和示例数均为零所示。基于提供的特征和数据划分,该数据集似乎专注于不同国家的经济指标。
创建时间:
2025-08-12
原始信息汇总
数据集概述
基本信息
- 数据集名称:imputed-jst
- 数据集地址:https://huggingface.co/datasets/arushisinha98/imputed-jst
数据集配置
配置1:developed
- 特征:
- Country (string)
- pop (float64)
- rgdpmad (float64)
- rgdpbarro (float64)
- rconsbarro (float64)
- gdp (float64)
- iy (float64)
- cpi (float64)
- ca (float64)
- imports (float64)
- exports (float64)
- narrowm (float64)
- money (float64)
- stir (float64)
- ltrate (float64)
- wage (float64)
- debtgdp (float64)
- revenue (float64)
- expenditure (float64)
- xrusd (float64)
- tloans (float64)
- tmort (float64)
- lev (float64)
- ltd (float64)
- noncore (float64)
- eq_tr (float64)
- bond_tr (float64)
- bill_rate (float64)
- eq_capgain (float64)
- eq_dp (float64)
- bond_rate (float64)
- eq_div_rtn (float64)
- safe_tr (float64)
- Date (timestamp[ns])
- 数据分割:
- train: 2532个样本,698382字节
- 下载大小:666788字节
- 数据集大小:698382字节
配置2:emerging
- 特征:
- Country (null)
- Date (null)
- 数据分割:
- train: 0个样本,0字节
- 下载大小:722字节
- 数据集大小:0字节
数据文件路径
- developed配置:
developed/train-* - emerging配置:
emerging/train-*
搜集汇总
数据集介绍
构建方式
在宏观经济研究领域,imputed-jst数据集通过系统整合多国经济指标构建而成。该数据集采用时间序列结构,收录了发达国家(developed)和新兴市场(emerging)两大经济群体的关键数据,涵盖GDP、贸易收支、货币供应量等30余个核心经济变量。数据采集过程严格遵循国际统计标准,通过时间戳(timestamp)确保时序一致性,并采用插值技术处理缺失值,为纵向比较研究提供可靠基础。
特点
imputed-jst数据集以其多维度的经济指标著称,特别聚焦金融与贸易领域深度特征。数据集不仅包含传统宏观经济指标如rgdpmad(人均实际GDP)和cpi(消费者物价指数),还创新性地纳入了金融市场变量如股票回报率(eq_tr)、债券收益率(bond_rate)等。发达国家子集包含2532条完整样本,各字段以float64格式存储,确保计算精度;而新兴市场子集则预留了标准化数据结构,为后续研究扩展提供可能。
使用方法
研究者可通过HuggingFace平台直接加载developed配置,利用pandas等工具处理timestamp[ns]格式的时间序列。该数据集特别适合面板数据分析,Country字段支持跨国比较研究,而pop(人口)、wage(工资)等变量可与社会发展指标交叉验证。对于机器学习应用,建议先将rgdpbarro(巴罗式实际GDP)等连续变量标准化,再结合eq_div_rtn(股息收益率)等金融指标构建预测模型。
背景与挑战
背景概述
imputed-jst数据集作为宏观经济研究领域的重要资源,由国际知名研究机构Jordà-Schularick-Taylor团队构建,旨在解决长期历史经济数据分析中的缺失值问题。该数据集汇集了多国宏观经济指标,涵盖GDP、贸易收支、货币供应量等关键变量,为研究经济周期、金融稳定性等核心问题提供了标准化数据支持。其创新性在于采用先进的插补技术处理历史数据缺口,使得跨时期、跨国家的经济比较研究成为可能,对宏观经济计量学发展产生了深远影响。
当前挑战
该数据集面临两大核心挑战:在领域问题层面,宏观经济指标的复杂关联性使得单一插补方法难以保持变量间的理论关系,如何平衡统计合理性与经济逻辑一致性成为关键难题;在构建过程中,历史数据的碎片化特征与各国统计口径差异导致数据清洗与标准化工作异常艰巨,特别是早期数据的可靠性与完整性不足,需要开发专门的质量控制流程。此外,动态经济环境下新变量的持续纳入也对数据结构的扩展性提出了更高要求。
常用场景
经典使用场景
在宏观经济研究领域,imputed-jst数据集因其全面的经济指标和时间序列数据而成为经典工具。研究者通常利用该数据集分析发达国家的经济增长模式、货币政策效应以及财政政策的长期影响。数据集中的rgdpmad、rgdpbarro等指标为跨国经济比较提供了可靠基础,而时间戳数据则支持动态经济模型的构建与验证。
实际应用
中央银行与国际金融机构将该数据集应用于压力测试和金融稳定评估。进出口数据(imports/exports)与汇率指标(xrusd)的组合,使贸易弹性分析成为可能。商业银行则利用贷款总额(tloans)和抵押贷款(tmort)数据构建信贷周期预警模型,这些应用显著提升了金融监管的前瞻性。
衍生相关工作
基于该数据集衍生的经典研究包括Jordà-Schularick-Taylor关于信贷扩张与金融危机的开创性工作,其提出的'三难困境'理论深刻影响了宏观审慎政策制定。后续学者进一步利用eq_tr(股票回报)和bond_tr(债券回报)数据,发展了跨资产波动溢出效应的计量分析方法。
以上内容由遇见数据集搜集并总结生成


