yin_yang_dataset
收藏github2019-06-14 更新2024-05-31 收录
下载链接:
https://github.com/VishnuKunchur/yin_yang_dataset
下载链接
链接失效反馈官方服务:
资源简介:
用于机器学习分类任务的数据集生成工具,通过调整参数如数据点数量、目标类别数和复杂度控制,生成特定形状和标签的数据集,以供分类算法使用。
A dataset generation tool for machine learning classification tasks, which allows for the generation of datasets with specific shapes and labels by adjusting parameters such as the number of data points, the number of target categories, and complexity controls, for use by classification algorithms.
创建时间:
2019-06-13
原始信息汇总
数据集概述
数据集生成
- 名称:
yin_yang_dataset - 功能: 生成用于机器学习分类任务的数据集。
- 生成方法: 使用
yin_yang_datagen函数生成数据集,该函数可以生成形状为(m, 2)的数据集,其中m为所需的数据点数量。
数据集特性
- 数据形状:
(m, 2),其中m为数据点数量。 - 标签形状:
(m,),对应每个数据点的分类标签。 - 分类方法: 支持2类和3类分类任务。
- 数据复杂度控制: 通过
size_ratio参数控制数据集的复杂度,该参数值介于0到1之间,影响数据集中“yin”和“yang”区域的相对大小。
参数说明
n: 数据点数量,默认值为1000。num_target_classes: 目标分类数,可选值为2或3,默认值为2。balanced: 是否平衡数据集,仅在二分类任务中有效,默认值为True。size_ratio: 控制数据集复杂度的比例,默认值为0.25。
使用示例
python from yin_yang import yin_yang_datagen data, labels = yin_yang_datagen(n = 1500, size_ratio = 0.18, num_target_classes = 2)
可视化示例
- 使用
plt.scatter函数展示数据集分布,通过颜色区分不同类别。
适用算法
- 非线性分类算法,如在高复杂度数据集中表现更优。
搜集汇总
数据集介绍
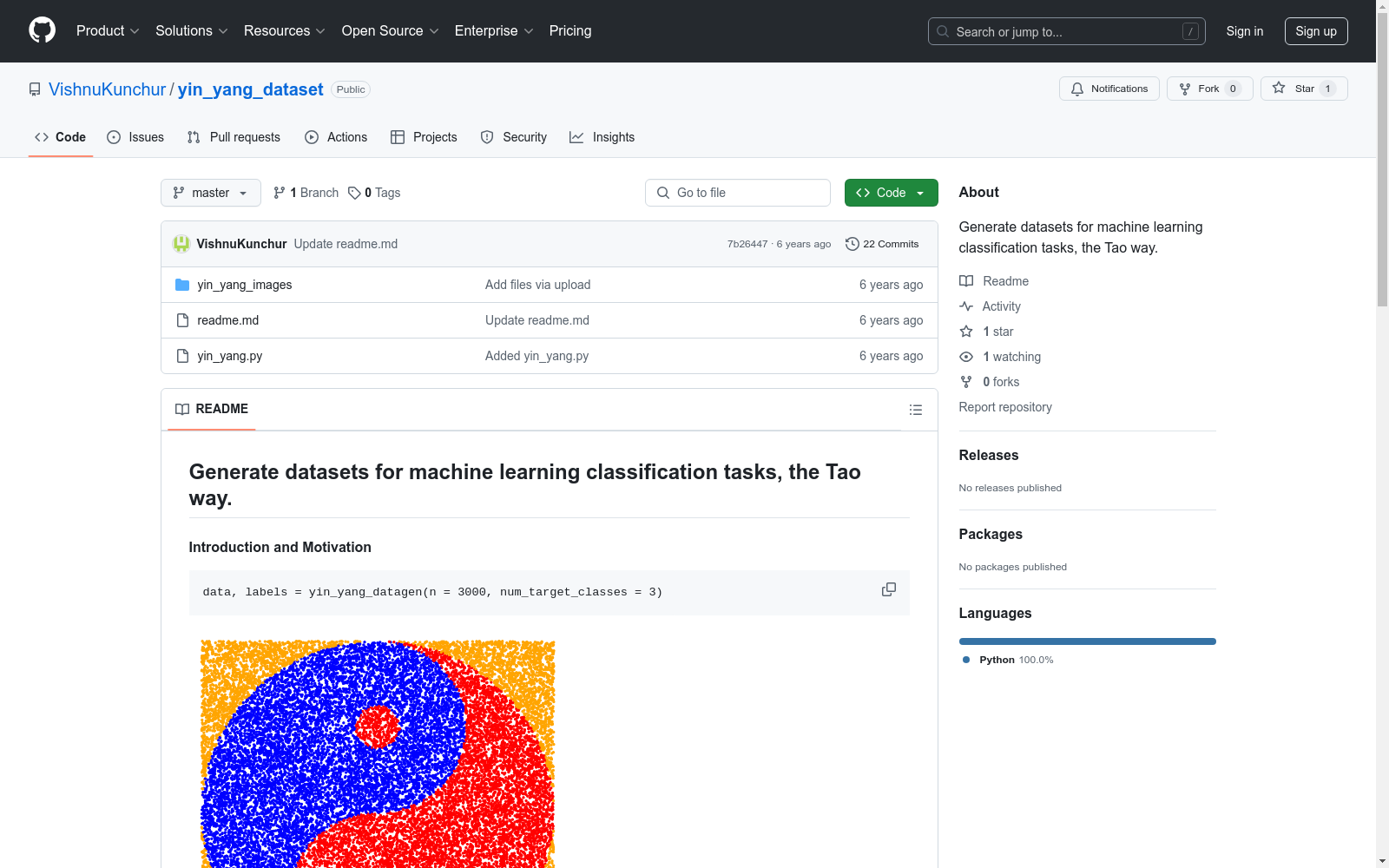
构建方式
本数据集通过`yin_yang_datagen`函数生成,其核心思想来源于对数据科学领域中分类算法优化过程的探究。该函数根据指定的参数生成形状为`(m, 2)`的二维数据点集合,其中`m`为数据点的数量,并伴有相应的目标值。这些数据点及目标值旨在供分类算法使用,通过调整参数,可以控制数据集的大小、类别数量、是否平衡以及复杂度。
特点
`yin_yang_dataset`独具匠心,其数据分布形式呈现出阴阳相生的哲学思想,特别适合用于评估和比较线性与非线性分类算法的性能。数据集的复杂度通过`size_ratio`参数进行调节,从而影响小岛的大小,进而影响分类任务的难易程度。此外,数据集支持二分类和三分类任务,可通过`num_target_classes`参数进行设定,满足不同的分类需求。
使用方法
使用该数据集时,首先需通过`yin_yang_datagen`函数生成数据点和标签。随后,可以利用数据可视化工具如`matplotlib`对数据进行可视化分析,观察数据分布特性。在模型训练阶段,用户可以将生成的数据点和标签输入到分类模型中,通过调整模型参数来优化模型性能。
背景与挑战
背景概述
yin_yang_dataset是一个专注于生成机器学习分类任务数据集的工具,其设计理念来源于道家哲学。该数据集由数据科学的学习者和实践者创建,旨在深入理解复杂算法的内部工作机制,尤其是优化方法在适应训练数据集过程中的表现。yin_yang_dataset能够在二维空间中生成数据点及其对应的标签,供分类算法使用。该数据集自创建以来,便成为研究者在探索非线性算法性能及适应性的重要资源。
当前挑战
该数据集在构建过程中所面临的挑战主要包括:如何通过调整样本空间和关联标签来优化算法选择,以及如何在保证数据集复杂性的同时,维持其可分性。具体而言,数据集的设计需要解决线性分类器无法捕捉数据内在非线性特征的问题。此外,通过调整`size_ratio`参数来控制数据集中'阴阳'小岛的大小,进而影响数据集的复杂度,也是该数据集构建中的一大挑战。
常用场景
经典使用场景
在探究机器学习分类算法的内在工作机制时,`yin_yang_dataset`数据集提供了独特的视角。该数据集通过生成形状为`(m, 2)`的二维数据点及其对应的标签,被广泛用于评估和比较线性与非线性分类器的性能。其基本使用场景包括通过调整`size_ratio`参数,控制数据集中小岛的大小,进而调整数据复杂性,为不同算法提供一个直观的可视化评价平台。
解决学术问题
该数据集解决了学术研究中如何直观评估分类算法性能的问题。在传统数据集上,算法的性能评估可能受到数据分布特性的限制,而`yin_yang_dataset`通过其独特的生成方式,使得研究者在视觉上即可判断算法是否能够捕捉到数据中的非线性特征。这对于理解算法优化过程及选择最佳拟合算法具有重要意义。
衍生相关工作
基于`yin_yang_dataset`,研究者们衍生出了一系列相关工作,包括对非线性算法在处理此类数据时的性能评估,以及对数据生成参数如何影响分类器选择的研究。这些工作进一步拓宽了机器学习领域对于算法性能评估的理解,并为分类算法的设计提供了新的思路。
以上内容由遇见数据集搜集并总结生成


