BAREC-Shared-Task-2026-sent
收藏Hugging Face2026-05-17 更新2026-05-18 收录
下载链接:
https://huggingface.co/datasets/CAMeL-Lab/BAREC-Shared-Task-2026-sent
下载链接
链接失效反馈官方服务:
资源简介:
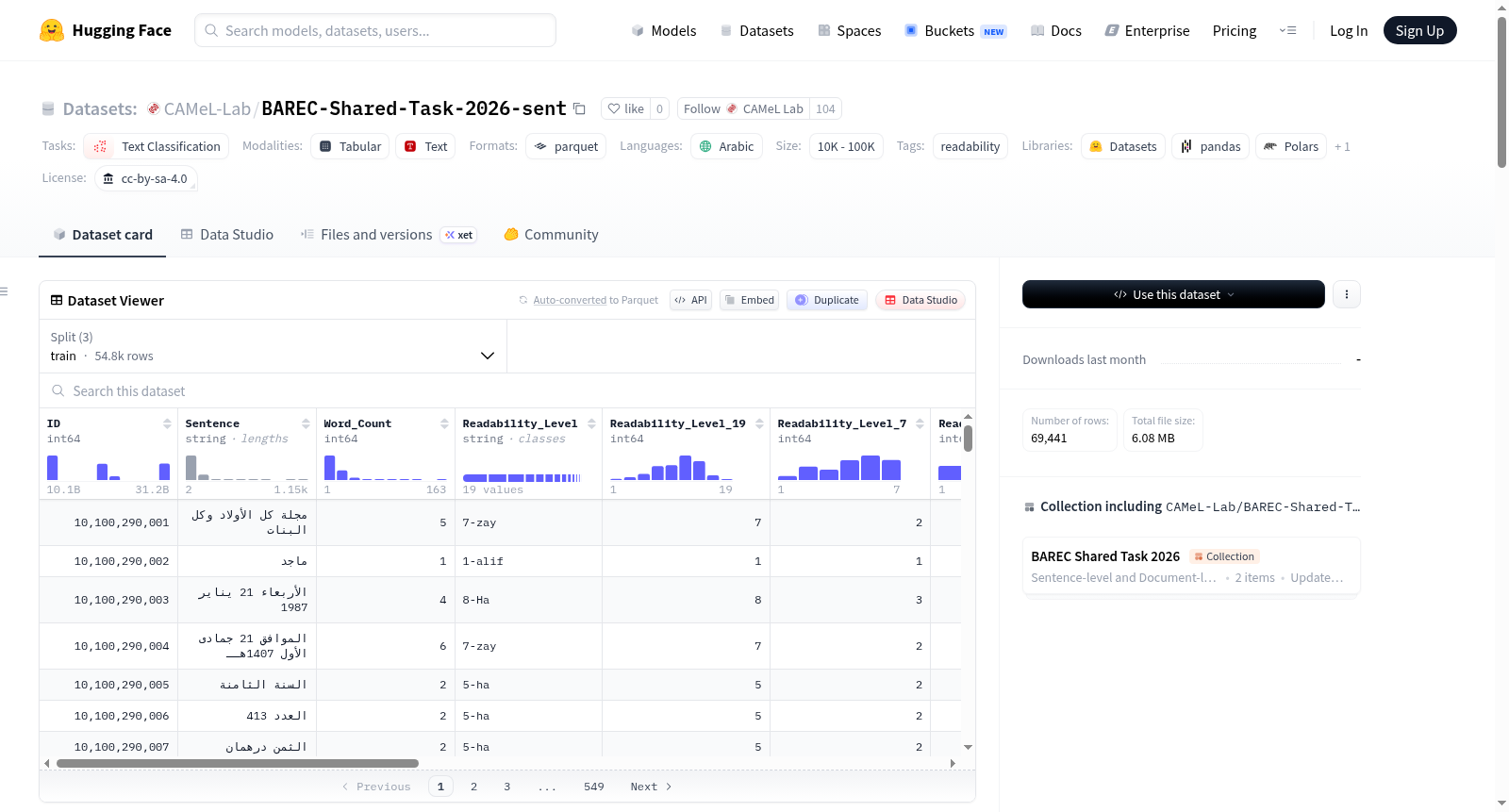
BAREC-ST-2026数据集是为第二届阿拉伯语可读性评估共享任务(BAREC Shared Task 2026)构建的大规模、平衡的阿拉伯语可读性评估语料库。该数据集旨在支持细粒度的阿拉伯语可读性评估研究,包含超过100万个单词,并以句子级别进行了人工标注。其核心标注体系包含19个可读性级别(从1-alif到19-qaf),并提供了向下映射的7级、5级和3级分类方案。文档级别的可读性得分由其内部最难句子的19级标签决定,从而同时提供了句子级别和文档级别的可读性信息。数据集语言为现代标准阿拉伯语(MSA)。每个数据样本包含丰富的元数据字段,如唯一的句子ID、句子文本、单词数量、各级别的可读性标签(数值和类别形式)、标注者ID、源文档文件名、文档来源、书籍信息、作者、领域(艺术与人文、STEM、社会科学)以及文本类别(基础、高级、专业)。数据集已划分为训练集(80%)、开发集(10%)和测试集(10%),划分在文档级别进行,并确保了在不同可读性级别、领域和文本类别上的平衡性。该数据集主要适用于多类别(特别是序数)文本分类任务,可用于训练和评估阿拉伯语可读性自动评估模型。
The BAREC-ST-2026 dataset is a large-scale, balanced Arabic readability assessment corpus constructed for the Second Arabic Readability Assessment Shared Task (BAREC Shared Task 2026). It aims to support fine-grained Arabic readability assessment research, containing over 1 million words and manually annotated at the sentence level. Its core annotation system includes 19 readability levels (from 1-alif to 19-qaf), with downward-mapped 7-level, 5-level, and 3-level classification schemes. Document-level readability scores are determined by the 19-level label of the hardest sentence within the document, providing both sentence-level and document-level readability information. The dataset language is Modern Standard Arabic (MSA). Each data sample includes rich metadata fields, such as unique sentence ID, sentence text, word count, readability labels at various levels (in numerical and categorical forms), annotator ID, source document filename, document source, book information, author, domain (Arts & Humanities, STEM, Social Sciences), and text category (Basic, Advanced, Professional). The dataset is divided into training (80%), development (10%), and test (10%) sets at the document level, ensuring balance across different readability levels, domains, and text categories. It is primarily suitable for multi-category (especially ordinal) text classification tasks and can be used to train and evaluate automatic Arabic readability assessment models.
提供机构:
CAMeL Lab
创建时间:
2026-05-17
原始信息汇总
BAREC Shared Task 2026 数据集概述
基本信息
- 数据集名称:BAREC-ST-2026(Balanced Arabic Readability Evaluation Corpus)
- 许可证:CC-BY-SA-4.0
- 任务类别:文本分类(text-classification)
- 语言:阿拉伯语(现代标准阿拉伯语)
- 数据规模:10K < n < 100K 条样本,包含超过 100万词
- 标注层级:19 个可读性级别,同时支持映射到 7、5、3 级方案
任务与评价
支持任务
- 多类可读性分类:支持 19 级(默认)、7 级、5 级、3 级四种分类粒度
- 标注粒度:句子级标注,文档级可读性由该文档中最难句子的可读性级别决定
评价指标
- 准确率(Acc^19, Acc^7, Acc^5, Acc^3):预测与真实标签完全匹配的比例
- 邻近准确率(±1 Acc^19):预测与真实标签相差不超过一级的比例
- 平均距离(Dist):预测与真实标签之间的平均绝对误差(MAE)
- 二次加权Kappa(QWK):衡量预测与真实标签一致性的指标,对较大偏差施加更高惩罚
数据集结构
数据字段
| 字段 | 说明 |
|---|---|
| ID | 唯一句子标识符 |
| Sentence | 句子文本 |
| Word_Count | 句子中的词数 |
| Readability_Level | 19级可读性级别(1-alif 到 19-qaf) |
| Readability_Level_19 | 19级可读性(数值 1-19) |
| Readability_Level_7 | 7级可读性(数值 1-7) |
| Readability_Level_5 | 5级可读性(数值 1-5) |
| Readability_Level_3 | 3级可读性(数值 1-3) |
| Annotator | 标注者ID(A1-A5 或 IAA) |
| Document | 源文档文件名 |
| Source | 文档来源 |
| Book | 书名 |
| Author | 作者 |
| Domain | 领域(Arts & Humanities、STEM、Social Sciences) |
| Text_Class | 读者群体(Foundational、Advanced、Specialized) |
数据划分
- 训练集(Train):80%
- 开发集(Dev):10%
- 测试集(Test):10%
- 划分基于文档级别,并确保在可读性级别、领域、文本类别上保持平衡
数据示例
{ID: 10100010008, Sentence: عيد سعيد, Word_Count: 2, Readability_Level: 2-ba, Readability_Level_19: 2, Readability_Level_7: 1, Readability_Level_5: 1, Readability_Level_3: 1, Annotator: A4, Document: BAREC_Majed_0229_1983_001.txt, Source: Majed, Book: Edition: 229, Author: #, Domain: Arts & Humanities, Text_Class: Foundational}
相关资源
- 共享任务网站:https://barec.camel-lab.com/sharedtask2026
- 评价脚本:https://github.com/CAMeL-Lab/barec-shared-task-2025
搜集汇总
数据集介绍
构建方式
BAREC数据集(Balanced Arabic Readability Evaluation Corpus)是针对阿拉伯语文本可读性评估的大型语料库,专为BAREC 2026共享任务构建。该数据集以句子为单位进行精细标注,涵盖超过100万词,横跨19个可读性层级。注释过程由五位专业注释员完成,每个句子均被赋予多层级标签,并额外映射至7级、5级和3级粗粒度体系。文档级可读性得分则依据其内最难句子的层级进行推导,从而兼顾句子与文档两个维度的信息。数据按照文档级别划分为训练集(80%)、开发集(10%)和测试集(10%),并在可读性层级、领域和读者群体类别上保持均衡分布。
使用方法
BAREC数据集主要适用于多类别可读性分类任务,尤其聚焦于序数分类场景。用户可通过加载HuggingFace上的数据集接口,获取包含句子文本、多层级标签及元数据的数据实例。评估时推荐采用准确率(包括19级、7级、5级和3级)、相邻准确率、平均绝对距离与二次加权卡帕系数等指标全面衡量模型性能。研究人员可利用所提供的多层次标签灵活选择粒度,或将不同层级间的映射关系应用于迁移学习。官方提供的评估脚本简化了模型验证流程,同时鼓励研究者在原文基础上探索跨层面融合策略或引入外部语言特征以提升预测精度。
背景与挑战
背景概述
BAREC(Balanced Arabic Readability Evaluation Corpus)是由CAMeL-Lab研究团队于2025年创建的大规模阿拉伯语可读性评估数据集,相关论文发表于ACL 2025 Findings。该数据集聚焦于细粒度阿拉伯语可读性评估这一核心研究问题,包含超过100万词,覆盖19个可读性等级,并提供至7级、5级和3级的映射方案。数据集以句子为标注单元,文档级可读性依据句子中最难等级确定。BAREC的发布填补了阿拉伯语可读性评估领域大规模、细粒度标注数据的空白,为多类可读性分类任务提供了标准化基准,并推动了第二届BAREC共享任务(BAREC Shared Task 2026)的开展,对阿拉伯语自然语言处理领域具有重要影响。
当前挑战
BAREC数据集所解决的领域问题在于阿拉伯语可读性评估缺乏细粒度、平衡且大规模的数据资源,现有研究多依赖粗粒度等级或小规模语料,难以支撑精确的自动化评估模型。构建过程中面临的挑战包括:1)19级可读性标注体系的定义与一致维护,需设计详尽的标注指南以供五名标注员遵循;2)跨领域(人文艺术、STEM、社会科学)和读者群体(基础、进阶、专业)数据的平衡采样,以确保数据集代表性;3)句子级与文档级可读性关系的合理建模,以及多粒度等级映射方案的校准,最终保障了评估指标(如QWK、Adjacent Accuracy)的信度与效度。
常用场景
经典使用场景
BAREC数据集作为阿拉伯语可读性评估领域的大规模平衡语料库,其最经典的使用场景在于进行细粒度的文本可读性分类任务。该数据集涵盖超过一百万词,并按照19个细致等级标注句子级可读性,同时提供7级、5级和3级的粗粒度映射,为研究者提供了一个多层次、多粒度的评估基准。在自然语言处理中,研究人员常利用该数据集训练和评估机器学习模型,以准确预测阿拉伯语文本的阅读难度,从而推动非英语语言可读性研究的发展。
解决学术问题
该数据集解决了阿拉伯语可读性评估中长期缺乏大规模、高质量标注语料的关键学术问题。通过提供经过严格标注的句子级数据,BAREC使研究者能够系统性地探索文本复杂度与读者认知能力之间的关联,并开发可推广的自动评估模型。其多级标注方案有助于剖析可读性评估中的模糊边界问题,而平衡的分区设计则避免了数据偏倚。BAREC的诞生填补了阿拉伯语自然语言处理在文本难度定量分析领域的空白,推动了计算语言学和语言教育研究的交叉融合。
实际应用
在实际应用中,BAREC数据集被广泛用于开发面向阿拉伯语学习者的自适应阅读系统,基于文本的可读性等级,这些系统能够为不同水平的用户推荐合适的阅读材料。同时,阿拉伯语出版机构和教育平台可以利用基于该数据集训练的模型,自动化地评估教材、新闻文章或文学作品的难度等级,优化内容分发策略。此外,政府或非盈利组织在进行大规模文本筛查时,也可借助可读性评估工具筛选出面向公众的通知或教育文档,确保信息传递的准确性与适龄性。
数据集最近研究
最新研究方向
BAREC-ST-2026的推出标志着阿拉伯语可读性评估研究迈入精细化与标准化新阶段。该数据集以超过百万词、19级细粒度标注为特色,为低资源语言的文本复杂度自动分类提供了高质量基准。其多层级标签映射设计(19/7/5/3级)不仅支持从粗到细的模型评估,还催生了基于序数回归的多尺度评价体系,如邻近准确率与加权二次卡帕系数。这一资源将推动阿拉伯语教育文本适配、跨领域可读性建模以及多语言可读性基准的构建,在神经语言模型时代为文本难度自动感知注入数据驱动力,具有重要的学术与实践价值。
以上内容由遇见数据集搜集并总结生成


