napsternxg/openrecipes-20170107-061401-recipeitems
收藏Hugging Face2023-03-10 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/napsternxg/openrecipes-20170107-061401-recipeitems
下载链接
链接失效反馈官方服务:
资源简介:
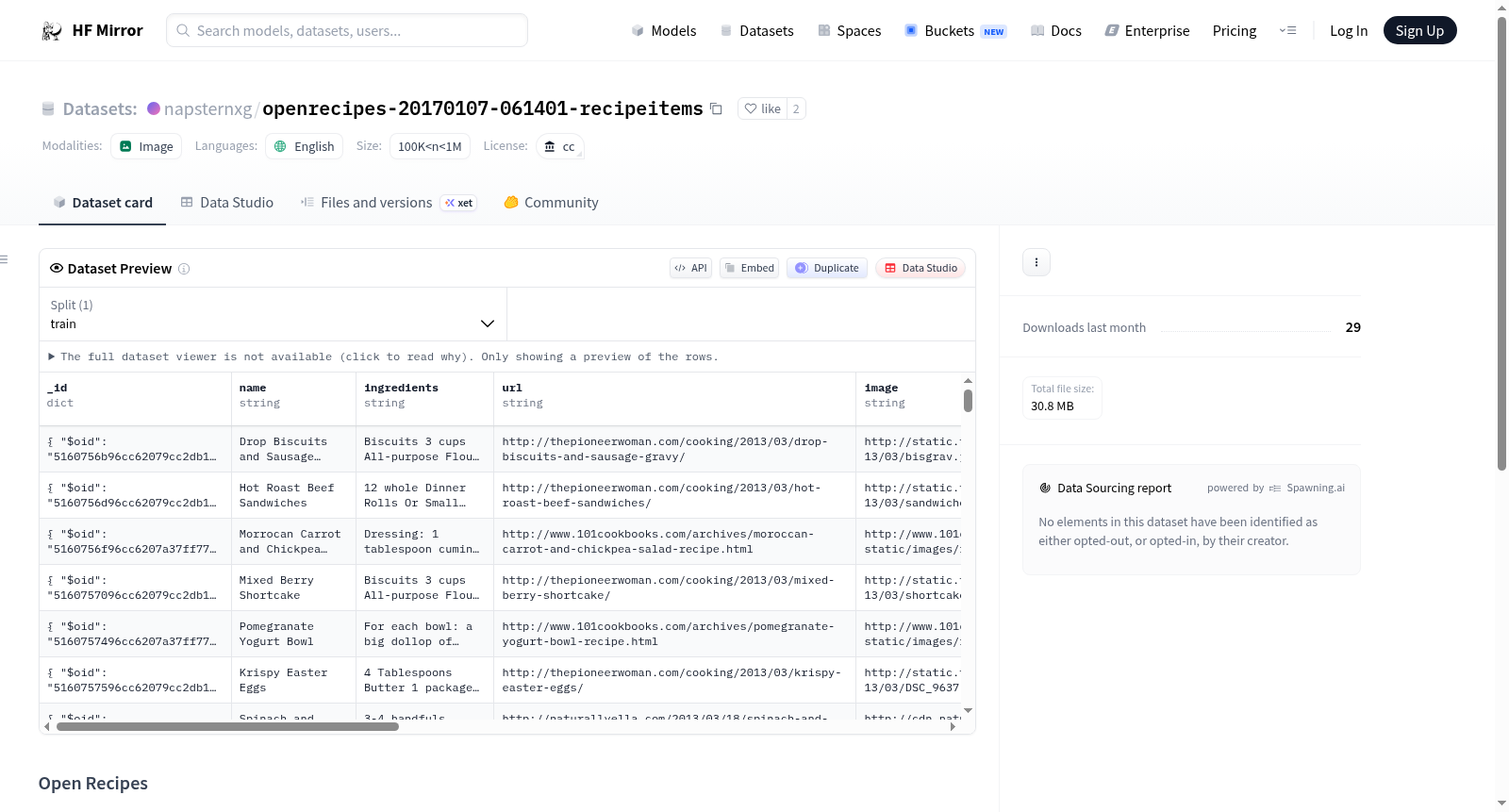
Open Recipes是一个开放的食谱书签数据库,数据来源于GitHub上的一个项目。用户可以通过提供的命令行指令收集数据。该数据集遵循Creative Commons Attribution 3.0 Unported License许可证。
Open Recipes是一个开放的食谱书签数据库,数据来源于GitHub上的一个项目。用户可以通过提供的命令行指令收集数据。该数据集遵循Creative Commons Attribution 3.0 Unported License许可证。
提供机构:
napsternxg
原始信息汇总
数据集概述
数据集名称
- 名称: Open Recipes
数据集描述
- 描述: Open Recipes是一个开放的数据库,包含食谱书签。
数据集来源
- 来源: 数据来源于https://github.com/fictivekin/openrecipes。
数据集获取方式
- 获取方式: 通过以下命令获取数据集: bash curl -O https://s3.amazonaws.com/openrecipes/20170107-061401-recipeitems.json.gz
数据集语言
- 语言: 英语(en)
数据集大小
- 大小: 100K<n<1M
数据集许可证
- 许可证: 该数据集根据Creative Commons Attribution 3.0 Unported License授权。
搜集汇总
数据集介绍
构建方式
在烹饪文化与数据科学的交汇处,Open Recipes数据集应运而生,它源自Fictive Kin LLC发起的开放食谱项目,旨在构建一个可自由访问的食谱书签库。该数据集通过curl命令从Amazon S3云存储服务直接获取压缩的JSON文件(20170107-061401-recipeitems.json.gz),原始数据来源于GitHub上的openrecipes仓库,确保了来源的透明性与可追溯性。构建过程简洁高效,采用单次批量下载的方式完成数据采集,保留了食谱条目的原始结构与元数据。
特点
该数据集涵盖超过10万条英文食谱记录,规模介于100K至1M之间,属于中等体量的专业语料库。其核心特点在于开放性——采用Creative Commons Attribution 3.0 Unported License许可协议,允许用户自由使用、分享与改编,仅需注明原始创作者。数据以JSON格式存储,每条记录包含食谱的书签信息,结构清晰且易于解析。这种设计既保证了数据的通用性,又降低了使用门槛,特别适合自然语言处理、推荐系统及烹饪知识图谱等研究领域。
使用方法
研究人员可通过Hugging Face Datasets库直接加载该数据集,使用load_dataset('napsternxg/openrecipes-20170107-061401-recipeitems')命令即可获取完整数据。数据以字典形式提供,每条记录对应一个食谱书签,用户可按需提取字段进行分析。对于本地处理,可先解压原始JSON文件,再使用Python的json模块逐行读取。推荐将数据划分为训练集与测试集,用于食谱文本生成、类别分类或成分关系抽取等下游任务。处理时需注意遵守CC BY 3.0许可协议,在成果中标注原始数据来源。
背景与挑战
背景概述
在计算美食学与数据驱动烹饪研究领域,结构化食谱数据的匮乏长期制约着算法推荐、营养分析与文化传播等方向的发展。Open Recipes数据集应运而生,由Fictive Kin LLC于2013年前后创建,旨在收集来自互联网的食谱书签,形成一个开放、可扩展的食谱数据库。该数据集源自GitHub上的openrecipes项目,核心研究问题在于如何整合分散的网络食谱资源,构建一个规模达数十万条、涵盖多元烹饪风格的标准化语料库。其影响力体现在为自然语言处理、推荐系统及食品科学提供了基础训练数据,推动了食谱检索、成分替代分析等应用的进步。数据集采用Creative Commons Attribution 3.0许可,鼓励学术与商业复用,成为该领域早期开放数据的里程碑之一。
当前挑战
Open Recipes所面临的挑战首先体现在领域问题层面:食谱数据本身具有高度非结构化特征,包括成分名称的异名同物、计量单位的多样性、烹饪步骤的序列逻辑以及文化差异导致的术语模糊,这些均对精准分类与信息抽取构成障碍。其次,构建过程中遭遇诸多困难:数据来源分散于各类网站,爬取与解析需应对网站结构频繁变动及反爬机制;原始JSON格式中字段规范不统一,如部分条目缺失关键属性或包含噪声文本;此外,数据时效性难以保证,部分链接随时间失效,导致数据集完整性与可用性下降。这些挑战要求后续研究者在数据清洗、标准化与持续维护上投入大量精力。
常用场景
经典使用场景
Open Recipes数据集作为大规模、开放获取的食谱书签集合,在计算美食学与自然语言处理领域扮演着基石角色。该数据集收录了逾十万条结构化食谱记录,涵盖食材清单、烹饪步骤及元数据信息,为研究者提供了丰富的多模态语料。其经典应用场景包括食谱文本的语义解析、食材与菜系之间的关联挖掘,以及基于内容的推荐系统开发。通过将非结构化的烹饪知识转化为可计算的形式,该数据集极大促进了食谱分类、营养信息抽取及跨文化饮食模式比较等方向的研究进展。
衍生相关工作
围绕Open Recipes数据集,学术界衍生了一系列具有里程碑意义的经典工作。例如,研究者利用其构建了首个大规模食材-菜系关联图谱,并提出了基于注意力机制的食谱生成模型。在推荐系统方向,基于该数据集的协同过滤与知识图谱嵌入方法显著提升了菜谱推荐的准确性与可解释性。此外,将食谱图像与文本信息融合的多模态学习框架,以及面向饮食偏好的情感分析模型,均以此数据集为实验基准,持续推动着食品计算领域的范式革新。
数据集最近研究
最新研究方向
在烹饪科学与计算美食学的交叉领域,Open Recipes数据集正成为推动食品信息学发展的关键资源。该数据集收录了数十万条结构化食谱书签,涵盖食材、烹饪步骤与营养信息,为自然语言处理与知识图谱构建提供了丰富的语料基础。前沿研究聚焦于利用该数据集训练食谱推荐系统、实现跨文化菜系的自动分类与风味预测,并探索基于深度学习的食材替换与个性化膳食规划。随着“智能厨房”与“数字营养”等热点概念的兴起,Open Recipes在促进烹饪知识数字化、支持饮食健康管理以及推动食品领域人工智能应用方面展现出深远影响,成为连接传统食谱与现代数据科学的桥梁。
以上内容由遇见数据集搜集并总结生成


