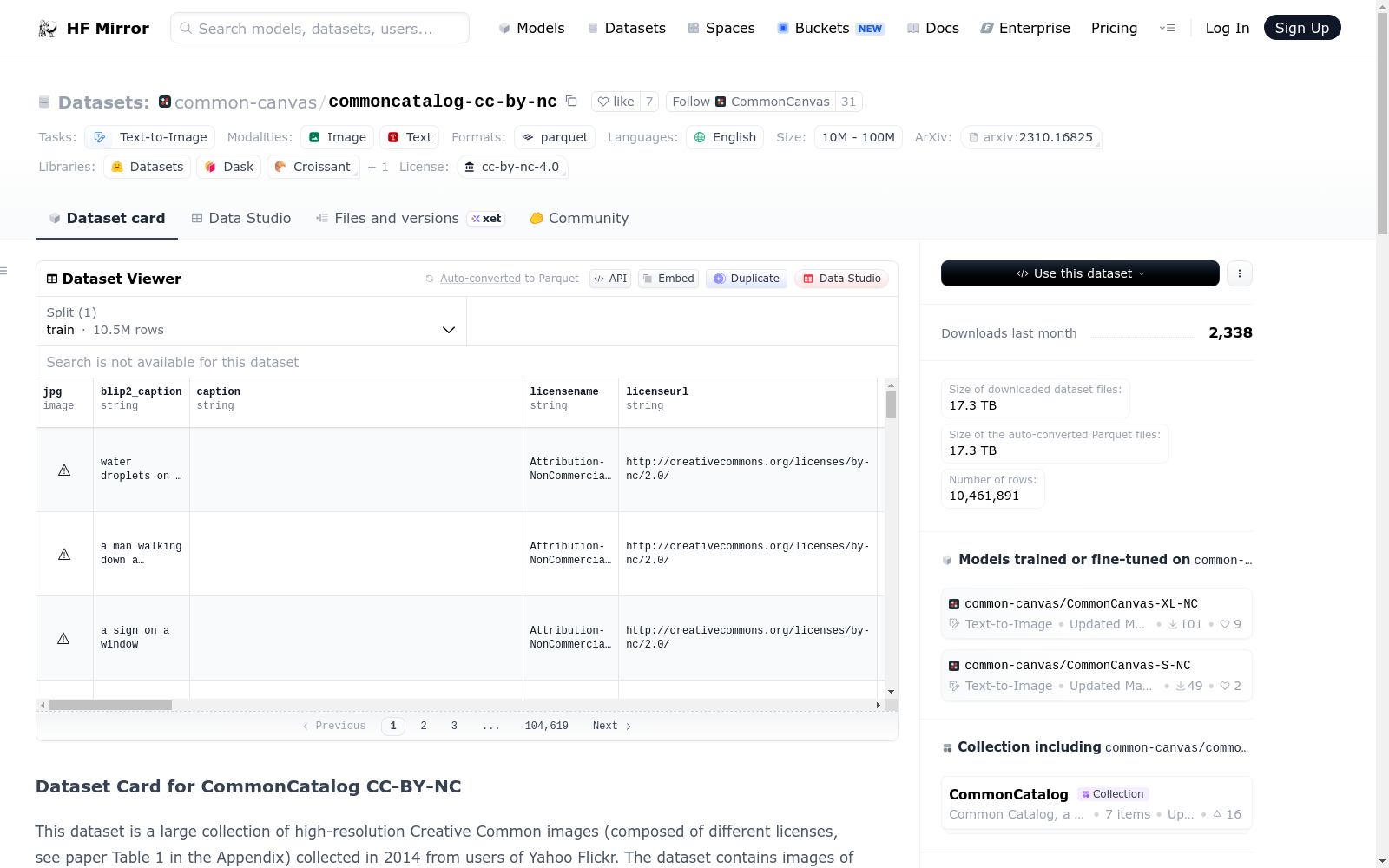
common-canvas/commoncatalog-cc-by-nc
收藏数据集卡片 for CommonCatalog CC-BY-NC
数据集详情
数据集描述
该数据集是从Yahoo Flickr用户收集的2014年创作共用高分辨率图像的大型集合(包含不同的许可证,详见附录中的论文表1)。数据集包含高达4k分辨率的图像,使其成为最高分辨率的带标题图像数据集之一。
- 由以下人员策划: Aaron Gokaslan
- 语言(NLP): 英语
- 许可证: 见相关的yaml标签/数据集名称。
数据集来源
- 存储库: https://github.com/mosaicml/diffusion
- 论文: https://arxiv.org/abs/2310.16825
- 演示: 见CommonCanvas Gradios
用途
我们使用CommonCatalog来训练一系列称为CommonCanvas的潜在扩散模型。目标是生成一个与Stable Diffusion 2竞争的模型,但使用易于访问且来源已知的数据集来实现这一目标。这样做使得复制模型变得更加容易,并提供了一个更清晰的机制来应用训练数据归属技术。
直接用途
- 训练文本到图像模型
- 训练图像到文本模型
超出范围的用途
- 商业用途
- 制作对个人有冒犯性或伤害性的内容,包括对其生活条件、文化背景、宗教信仰等的负面描述。
- 故意创建或传播歧视性内容或强化有害刻板印象。
- 未经许可虚假代表个人。
- 生成可能被个人无意中看到的性内容。
- 制作或传播虚假或误导性信息。
- 创建描绘极端暴力或流血的内容。
- 分发违反版权或许可材料使用条款的内容。
数据集结构
数据集分为10个子集,每个子集包含约4GB的parquets文件。每个子文件夹包含不同分辨率和相应宽高比的图像。数据集还根据图像是否授权商业使用(C)和非商业使用(NC)进行划分。
数据集创建
策划理由
创建一个标准化、易于访问的数据集,并发布合成标题,以便其他人可以在一个通用数据集上进行开源图像生成训练。
源数据
Yahoo Flickr Creative Commons 100M数据集和合成生成的标题数据。
数据收集和处理
所有合成标题均使用BLIP2生成。详见论文。
源数据生产者
Flickr用户
偏差、风险和限制
详见Yahoo Flickr Creative Commons 100M数据集。该信息收集于2014年左右,已知偏向于互联网连接的西方国家。一些地区,如全球南部,缺乏代表性。
引用
BibTeX:
@article{gokaslan2023commoncanvas, title={CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images}, author={Gokaslan, Aaron and Cooper, A Feder and Collins, Jasmine and Seguin, Landan and Jacobson, Austin and Patel, Mihir and Frankle, Jonathan and Stephenson, Cory and Kuleshov, Volodymyr}, journal={arXiv preprint arXiv:2310.16825}, year={2023} }
数据集卡片作者
数据集卡片联系人