submissions_v2
收藏Hugging Face2026-04-24 更新2026-04-25 收录
下载链接:
https://huggingface.co/datasets/SpX-DAC/submissions_v2
下载链接
链接失效反馈官方服务:
资源简介:
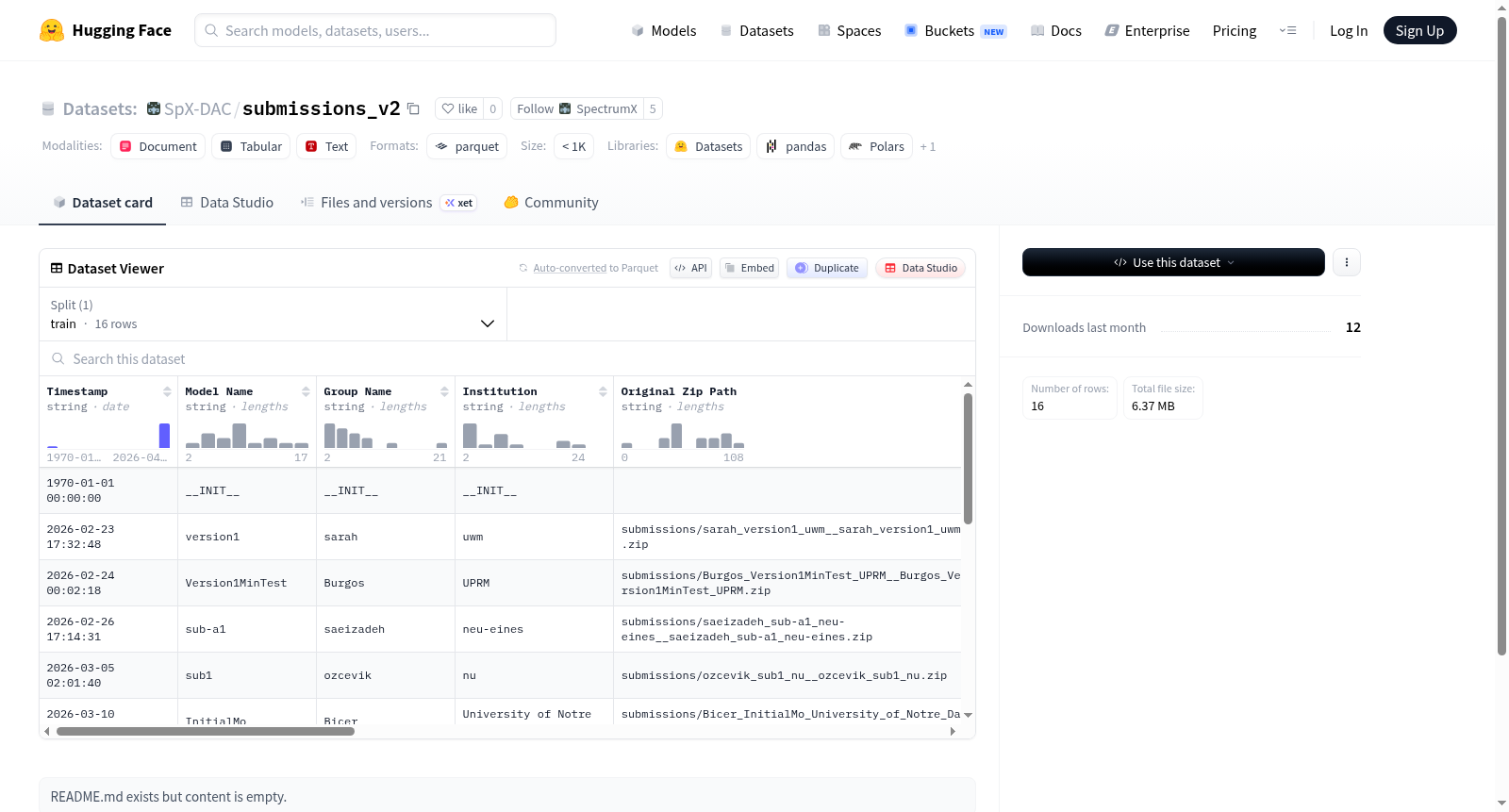
该数据集包含模型评估相关的结构化数据,涵盖时间戳、模型名称、组名、机构、原始压缩路径、压缩路径、评估数据集仓库、评估基准ID、评估显示名称、源基准ID、执行时间(秒)、准确率、真正例(TP)、假正例(FP)、假反例(FN)、真反例(TN)等字段。数据集仅包含训练集,共11个样本,总大小为3761字节,下载大小为8966字节。数据以浮点数和字符串类型为主,适用于模型性能分析、基准测试等任务。
创建时间:
2026-04-24
原始信息汇总
根据您提供的数据集详情页面地址和README文件内容,以下是对该数据集的总结:
数据集概述
- 数据集名称:
submissions_v2 - 所有者/组织: SpX-DAC
- 页面地址: https://huggingface.co/datasets/SpX-DAC/submissions_v2
数据集特征
该数据集包含16个特征,具体如下:
- 时间信息:
Timestamp(字符串) - 模型信息:
Model Name(字符串): 模型名称Group Name(字符串): 小组名称Institution(字符串): 所属机构
- 文件路径:
Original Zip Path(字符串): 原始压缩包路径Zip Path(字符串): 压缩包路径
- 评估信息:
Eval Dataset Repo(字符串): 评估数据集仓库Eval Benchmark ID(字符串): 评估基准IDEval Display Name(字符串): 评估显示名称Source Benchmark ID(字符串): 源基准IDExecution Time (s)(浮点数): 执行时间(秒)
- 性能指标:
Accuracy(浮点数): 准确率TP(浮点数): 真阳性FP(浮点数): 假阳性FN(浮点数): 假阴性TN(浮点数): 真阴性
数据规模
- 数据集大小: 3761 字节
- 下载大小: 8966 字节
- 数据划分: 仅包含一个
train划分 - 样本数量: 11 个样本
配置
- 默认配置:
default - 数据文件: 位于
data/train-*路径下。
搜集汇总
数据集介绍
构建方式
该数据集名为submissions_v2,旨在系统化记录模型评估任务的提交信息。其构建方式基于对模型评测流程中关键元数据的结构化采集,涵盖每次提交的时间戳、模型名称、所属团队与机构等基础属性。数据字段进一步细化了评估基准的来源标识(Eval Benchmark ID与Source Benchmark ID)以及评估结果的量化指标,如准确率、执行时间和混淆矩阵元素(TP、FP、FN、TN)。当前版本包含11条训练样本,数据以Parquet格式存储并压缩至约8.97KB大小,便于轻量级加载与快速实验迭代。
特点
该数据集的核心特点体现为对评估全链条信息的综合性覆盖。每条记录不仅记录了模型的Accuracy等性能指标,还同步追踪了原始提交文件路径(Original Zip Path与Zip Path),实现了模型输出与评估配置的可追溯性。此外,数据集融合了评估显示名称、评测基准仓库索引等多维标识,支持跨基准的横向对比研究。其简明的字段结构和高密度的元数据设计,使得研究者能够高效复现实验场景,并深入分析不同模型在统一评测框架下的行为模式差异。
使用方法
用户可通过HuggingFace Datasets库便捷加载该数据集,指定配置名称为'default'后,系统会自动读取'train'分片下的数据文件。由于数据量较小(仅11条记录),适合直接转换为Pandas DataFrame进行探索性分析或作为评测记录管理的参考模板。使用时,可依据'Model Name'和'Group Name'字段进行分组统计,也可结合'Eval Benchmark ID'筛选特定评测任务的结果。该数据集尤其适用于构建自动化评估报告系统或作为元数据快照,支撑模型迭代过程中的版本对比与性能归因分析。
背景与挑战
背景概述
submissions_v2数据集诞生于模型评估与竞赛管理的数字化浪潮之中,旨在系统性地记录和追踪各类模型在基准测试中的性能表现。该数据集由相关研究机构或平台创建,其核心研究问题聚焦于如何标准化地存储不同模型在指定评测任务上的提交记录、执行效率及精度指标。通过整合时间戳、模型名称、所属机构及准确率等字段,该数据集为后续的模型对比分析、历史表现回溯以及学术评估提供了坚实基础。尽管规模尚小,但其结构化设计已展现出促进算法透明度与可复现性的潜力,对推动机器学习社区的良性竞争与协作具有重要价值。
当前挑战
该数据集所应对的首要领域挑战在于模型评测结果缺乏统一归档机制,导致跨时间、跨机构的性能比较困难重重。具体到构建过程,数据来源的异构性要求对模型名称、机构信息等进行规范化处理,以避免因命名差异引发的歧义。此外,执行时间与准确率等数值字段的精确采集面临硬件条件、软件环境等多变量干扰,如何确保这些指标的公正性与可比性成为关键。数据集的稀疏性也是显著挑战,当前仅11个样例不足以支撑有效的统计推断,未来亟需扩充样本规模并完善元数据,以增强其在模型评估研究中的代表性与适用性。
常用场景
经典使用场景
在自然语言处理与机器学习研究的浩渺星空中,submissions_v2数据集犹如一面明镜,映照出众多模型在不同评测基准上的真实表现。该数据集收录了来自不同研究机构与团队的模型提交记录,包含模型名称、所属组别、评测数据集、执行时间、准确率以及混淆矩阵的四项核心指标(TP、FP、FN、TN)。其经典使用场景在于为研究者提供一个统一的平台,用以追踪、比较和分析各类模型在标准化评测任务中的性能表现,从而揭示不同算法架构与训练策略的优劣。
实际应用
在实际应用层面,submissions_v2数据集扮演着技术筛选与验证的重要角色。工程师与算法科学家可基于该数据集中的多条记录,快速甄别出在特定任务上表现卓越的模型,从而为产品化部署提供决策依据。例如,在构建智能问答系统或文本分类服务时,开发团队可以查阅该数据集中各模型在对应评测基准上的准确率与执行效率,精准挑选出兼顾性能与速度的候选方案,缩短从实验到落地的周期。
衍生相关工作
围绕submissions_v2数据集,衍生出了一系列经典研究工作。其中最具代表性的包括模型性能预测与趋势分析,研究者利用该数据集的时间戳与指标信息,揭示了不同时期模型精度的演进规律。此外,还有工作基于此数据集开展公平性度量研究,通过分析不同机构提交模型的性能分布,探讨了资源差异对研究成果的影响。更有学者将其与元学习相结合,构建了依据历史提交记录指导新模型参数初始化的智能系统,推动了自动化机器学习的发展。
以上内容由遇见数据集搜集并总结生成


