ai4privacy/pii-masking-200k
收藏Hugging Face2024-04-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ai4privacy/pii-masking-200k
下载链接
链接失效反馈官方服务:
资源简介:
Ai4Privacy PII200k数据集是一个用于训练模型以从文本中移除个人可识别信息(PII)的多语言数据集,特别是在AI助手和大型语言模型(LLMs)的上下文中。数据集包含约209k个示例,涵盖了54种PII类别,针对229个讨论主题/用例,分布在商业、教育、心理学和法律等领域,并采用了5种交互风格。数据集通过专有算法生成,并经过人工验证以确保高质量。数据集支持英语、法语、德语和意大利语,未来将支持更多语言。
The Ai4Privacy PII200k Dataset is a multilingual dataset designed for training models to remove personally identifiable information (PII) from text, specifically in the context of AI assistants and large language models (LLMs). The dataset contains approximately 209,000 examples, covering 54 PII categories, targeting 229 discussion topics/use cases across domains such as business, education, psychology, and law, and adopting 5 interaction styles. It was generated using proprietary algorithms and manually validated to ensure high data quality. The dataset supports English, French, German and Italian, with plans to support more languages in the future.
提供机构:
ai4privacy
原始信息汇总
数据集概述
基本信息
- 名称: Ai4Privacy PII200k Dataset
- 大小: 13.6m text tokens in ~209k examples with 649k PII tokens
- 语言: 英语、法语、德语、意大利语
- 数据来源: 原始数据,使用专有算法生成的合成数据
- 数据质量: 经过人机交互验证的高质量数据集
任务类别
- 文本分类
- 令牌分类
- 表格问答
- 问答
- 零样本分类
- 摘要
- 特征提取
- 文本生成
- 文本到文本生成
- 翻译
- 填充掩码
- 表格分类
- 表格到文本
- 文本检索
- 其他
应用领域
- 法律
- 商业
- 心理学
- 隐私
数据集结构
- 文件格式:
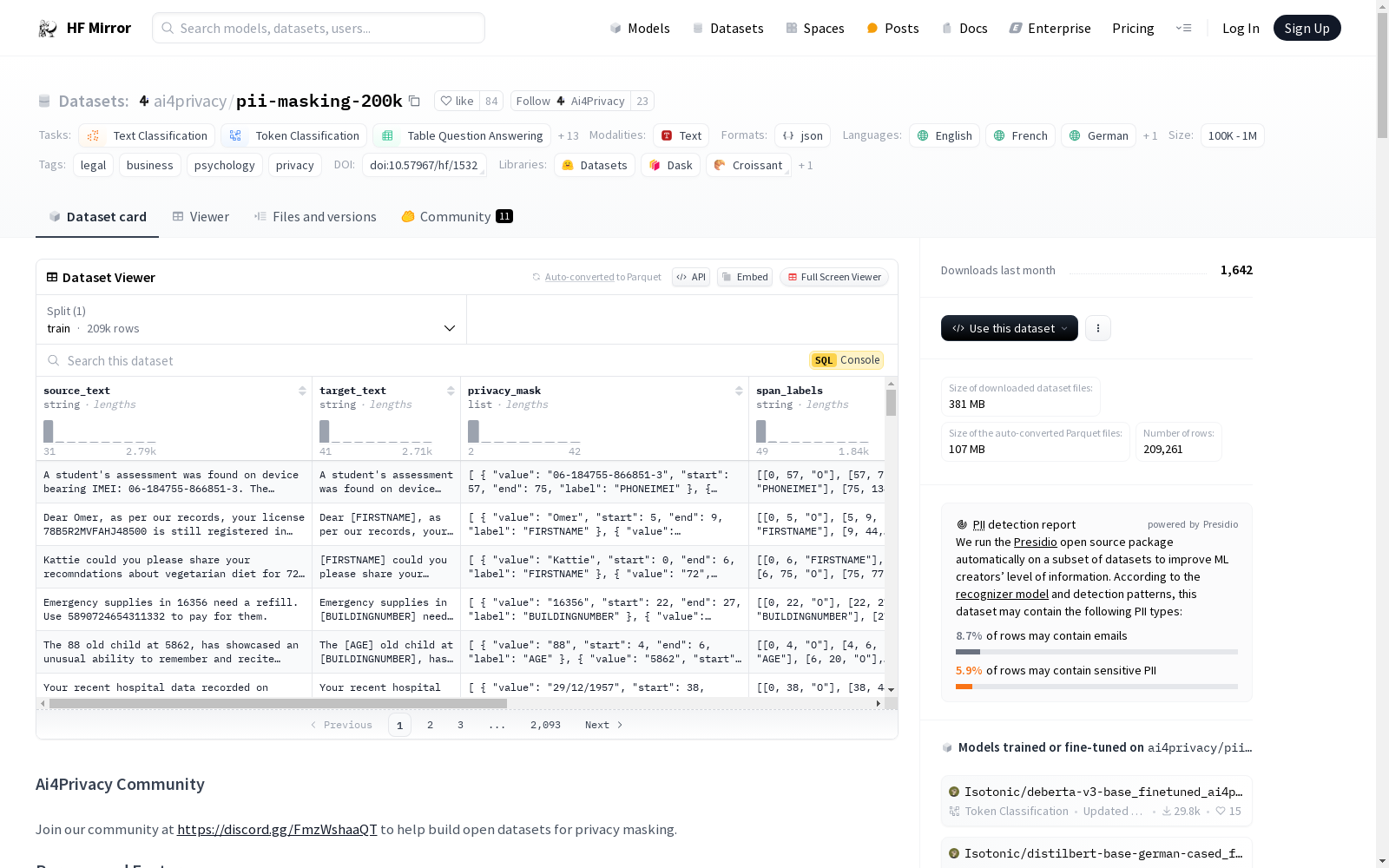
.jsonl - 数据内容:
- source_text: 包含PII的自然语言文本
- target_text: PII免费的自然文本
- privacy_mask: PII令牌实例与自然文本中字符串之间的映射
- span_labels: 开始、结束位置及PII令牌实例的数组
- mbert_bio_labels: 私人令牌开始位置的通用表示
- mbert_text_tokens: 使用Bert家族分词器分解的未屏蔽句子令牌
- 元数据: 包括ID、语言和数据集类型(训练、测试等)
兼容的机器学习任务
- 令牌分类: 使用多种模型,如ALBERT、BERT、BigBird等
- 文本生成: 映射未屏蔽文本到屏蔽文本或隐私掩码属性
数据集用途
- 训练模型以移除文本中的个人身份信息(PII),特别是在AI助手和LLMs的上下文中。
- 包含54种PII类别,针对229个讨论主题/用例,跨越商业、教育、心理学和法律领域。
搜集汇总
数据集介绍
构建方式
该数据集通过专有算法生成合成数据,确保不涉及隐私侵犯,并经过人工验证以保证高质量。数据集涵盖了54种个人身份信息(PII)类别,针对229个讨论主题和多种交互风格,涉及商业、教育、心理学和法律领域。数据集包含约209,000个样本,总计1360万文本标记和649,000个PII标记,支持英语、法语、德语和意大利语四种语言。
特点
该数据集的显著特点在于其多语言支持、丰富的PII类别和广泛的应用场景。数据集通过人工验证确保高质量,且在PII类别的标记分布上进行了平衡处理,尽管目前仍有部分类别(如FIRSTNAME)存在过度代表性。此外,数据集的合成生成方式避免了隐私问题,适用于多种机器学习任务,如文本分类和生成。
使用方法
使用该数据集时,用户可通过Python安装'datasets'库,并使用'load_dataset'函数加载数据集。数据集的每一行包含一个JSON对象,包含原始文本、去PII文本、隐私掩码信息和标记标签等。用户可根据需求选择不同的机器学习任务,如文本生成、分类等,并结合HuggingFace提供的模型进行微调,如T5、BERT等。
背景与挑战
背景概述
在人工智能与大数据技术迅猛发展的背景下,隐私保护成为了一个备受关注的议题。ai4privacy/pii-masking-200k数据集由Ai4Privacy社区创建,旨在训练模型以自动识别并移除文本中的个人身份信息(PII),特别是在AI助手和大型语言模型(LLMs)的应用场景中。该数据集包含了约209,000个样本,涵盖了54种PII类别,涉及229个讨论主题,分布在商业、教育、心理学和法律等多个领域。数据集支持四种语言(英语、法语、德语和意大利语),并通过人工验证确保了数据的高质量。其核心研究问题是如何在保护隐私的前提下,有效训练模型以识别和处理敏感信息,从而推动隐私保护技术的发展。
当前挑战
该数据集在构建过程中面临多项挑战。首先,如何在多语言环境中确保PII识别的准确性和一致性是一个重要问题。其次,数据集中某些PII类别(如‘FIRSTNAME’)的分布不均衡,导致模型在处理这些类别时可能存在偏差。此外,生成合成数据时需确保不侵犯隐私,同时保持数据的多样性和真实性。在应用层面,如何将PII掩码技术无缝集成到现有的AI系统中,以实现实时隐私保护,也是一个亟待解决的挑战。
常用场景
经典使用场景
ai4privacy/pii-masking-200k数据集的经典使用场景主要集中在隐私保护领域,特别是在训练模型以自动识别和移除文本中的个人身份信息(PII)。该数据集适用于多种自然语言处理任务,如文本分类、标记分类和文本生成等,尤其在构建能够自动屏蔽敏感信息的AI助手和大型语言模型(LLMs)中表现突出。通过该数据集,研究者和开发者可以训练模型在不同语言和场景下有效识别并处理PII,从而提升系统的隐私保护能力。
实际应用
在实际应用中,ai4privacy/pii-masking-200k数据集广泛应用于多个领域,如客户支持系统、电子邮件过滤、数据匿名化、社交媒体平台和在线表单等。通过集成PII屏蔽模型,这些系统能够自动检测并移除敏感信息,从而保护用户隐私,减少数据泄露的风险。此外,该数据集还支持协作文档编辑和内容生成等应用,确保在多用户协作和内容创作过程中,敏感信息得到有效保护。
衍生相关工作
基于ai4privacy/pii-masking-200k数据集,衍生了许多相关的经典工作,特别是在隐私保护和自然语言处理领域。例如,研究者利用该数据集开发了多种PII识别和屏蔽模型,这些模型被广泛应用于聊天机器人、客户支持系统和社交媒体平台等场景。此外,该数据集还推动了多语言隐私保护技术的研究,促进了跨语言隐私保护模型的开发和应用。这些衍生工作不仅提升了隐私保护技术的实用性,还为相关领域的研究提供了新的方向和灵感。
以上内容由遇见数据集搜集并总结生成


