WelQrate
收藏arXiv2024-11-15 更新2024-11-19 收录
下载链接:
https://www.welqrate.org/
下载链接
链接失效反馈官方服务:
资源简介:
WelQrate数据集是由范德堡大学的研究团队精心策划的高质量小分子药物发现基准数据集,涵盖了9个数据集,跨越5种治疗目标类别。数据集的大小从约66K到300K不等,包含高度不平衡的活动标签,以反映低命中率的现实情况。创建过程中,通过多层次的筛选和领域专家的严格预处理,如PAINS过滤,确保数据的高质量。WelQrate数据集的应用领域主要集中在小分子药物发现,旨在通过提供高质量的数据集和标准化的评估框架,推动AI模型在实际药物发现中的应用,解决现有数据集质量不高的问题。
The WelQrate dataset is a high-quality small-molecule drug discovery benchmark dataset carefully curated by a research team from Vanderbilt University. It encompasses 9 datasets spanning 5 therapeutic target categories, with the size of each dataset ranging from approximately 66K to 300K. The dataset contains highly imbalanced activity labels to reflect the realistic scenario of low hit rates in drug discovery. During its creation, multi-level screening and strict preprocessing conducted by domain experts (such as PAINS filtering) were implemented to ensure its high data quality. The WelQrate dataset is primarily applied in the field of small-molecule drug discovery, aiming to promote the practical application of AI models in real-world drug discovery by providing high-quality datasets and a standardized evaluation framework, thereby addressing the problem of insufficient quality of existing datasets.
提供机构:
范德堡大学
创建时间:
2024-11-15
搜集汇总
数据集介绍
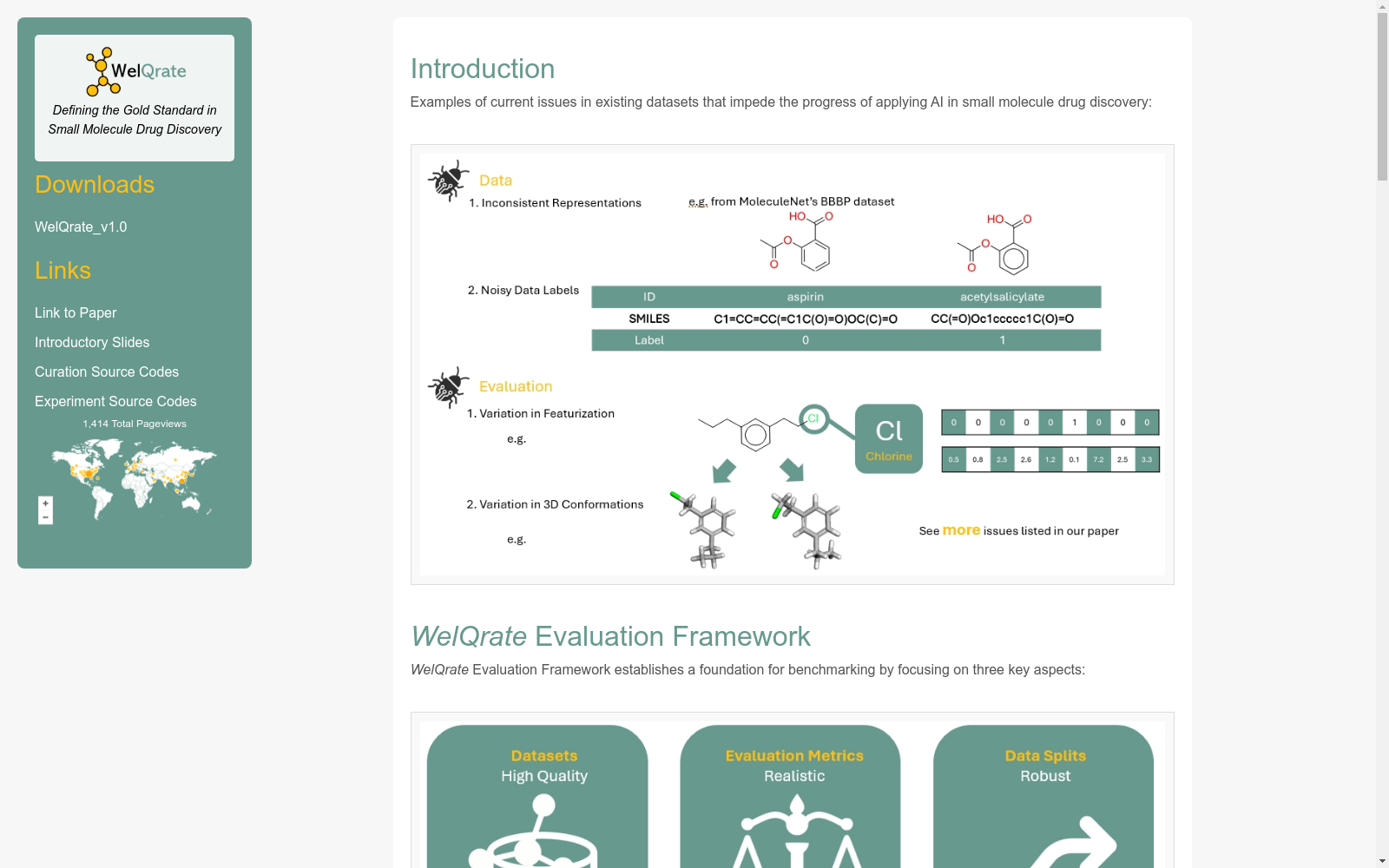
构建方式
WelQrate数据集的构建过程体现了对小分子药物发现领域中高质量数据需求的深刻理解。该数据集通过精心策划的9个数据集,涵盖了5类治疗靶点,采用了由药物发现专家设计的层次化筛选流程。这一流程不仅依赖于初级的高通量筛选,还整合了确认性筛选和反向筛选,并进行了严格的领域驱动预处理,如PanAssay干扰化合物(PAINS)过滤,以确保数据集的高质量。
特点
WelQrate数据集的显著特点在于其高质量和多样性。通过多层次的筛选和严格的预处理,数据集确保了活性分子的高纯度和准确性。此外,数据集提供了多种标准和附加的数据格式,包括SMILES和InChI,以及2D和3D图,为模型评估提供了公平的基准。
使用方法
WelQrate数据集的使用方法灵活多样,适用于各种小分子药物发现任务。用户可以利用数据集进行虚拟筛选模型的训练和评估,通过标准化的评估框架,包括高质量数据集、特征化、3D构象生成、评估指标和数据分割,来确保模型的可靠性和现实性。数据集的详细筛选流程和实验脚本均公开可用,便于研究人员进行复现和进一步研究。
背景与挑战
背景概述
WelQrate数据集由Yunchao (Lance) Liu等研究人员于2024年创建,旨在为小分子药物发现领域提供一个黄金标准的基准测试平台。该数据集的核心研究问题是如何在没有健全模型评估框架的情况下,确保人工智能社区的努力能够充分发挥潜力,从而加速创新向实际药物发现的转化。WelQrate数据集的贡献包括精心策划的9个数据集,涵盖5类治疗靶点,通过药物发现专家设计的层次化筛选流程,确保数据的高质量。此外,WelQrate还提出了一个标准化的模型评估框架,考虑了高质量数据集、特征化、3D构象生成、评估指标和数据分割,为药物发现专家进行实际虚拟筛选提供了可靠的基准测试。该数据集的公开发布和维护在WelQrate.org上,旨在推动小分子药物发现领域的标准化评估实践。
当前挑战
WelQrate数据集在构建过程中面临多项挑战。首先,解决领域问题(如图像分类)的挑战在于如何确保数据集的高质量和真实性,以反映实际药物发现场景。构建过程中遇到的挑战包括处理高假阳性率、确保化学表示的一致性和定义立体化学、以及过滤实验噪声。此外,数据集的构建还需要严格的层次化筛选和领域专家验证,以确保数据的可靠性和有效性。这些挑战不仅涉及数据质量的提升,还包括如何设计有效的评估框架和指标,以准确衡量模型性能,从而推动AI创新在药物发现中的实际应用。
常用场景
经典使用场景
WelQrate数据集在药物发现领域中被广泛用于小分子药物的虚拟筛选。通过提供高质量的数据集和标准化的评估框架,WelQrate使得研究人员能够对不同的分子表示学习模型进行可靠的基准测试。其经典使用场景包括评估模型在预测小分子对治疗靶点的活性方面的性能,以及探索不同模型、数据质量和特征化方法对结果的影响。
衍生相关工作
WelQrate数据集的发布催生了大量相关研究工作,特别是在分子表示学习和虚拟筛选领域。例如,基于WelQrate的基准测试,研究人员开发了新的分子特征化方法和深度学习模型,以提高药物发现的准确性和效率。此外,WelQrate还促进了跨学科合作,推动了计算机科学与药物化学的融合。
数据集最近研究
最新研究方向
在药物发现领域,WelQrate数据集的最新研究方向主要集中在建立和优化小分子药物发现的标准化基准。研究者们致力于通过严格的层次化数据收集和处理流程,确保数据集的高质量,从而为虚拟筛选提供可靠的模型评估框架。此外,研究还探索了不同模型、数据质量和特征化方法对模型性能的影响,强调了数据质量和特征化在提升模型性能中的关键作用。通过这些研究,WelQrate数据集正逐渐成为小分子药物发现领域的新黄金标准,推动了AI创新在实际药物发现解决方案中的应用。
相关研究论文
- 1WelQrate: Defining the Gold Standard in Small Molecule Drug Discovery Benchmarking范德堡大学 · 2024年
以上内容由遇见数据集搜集并总结生成


