llm-handbook-rag-eval
收藏Hugging Face2025-12-02 更新2025-12-03 收录
下载链接:
https://huggingface.co/datasets/swtb/llm-handbook-rag-eval
下载链接
链接失效反馈官方服务:
资源简介:
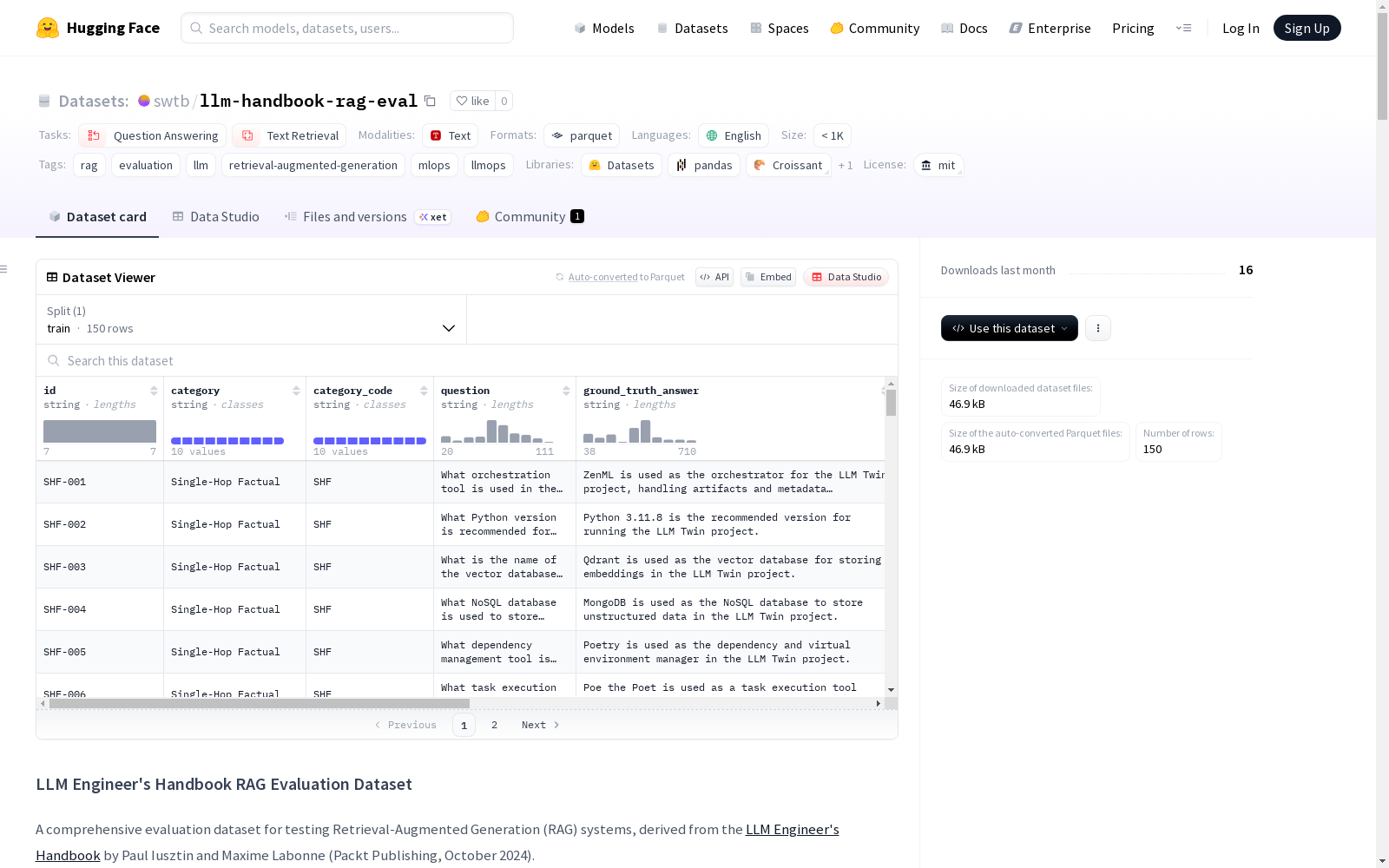
LLM Engineer's Handbook RAG Evaluation Dataset 是一个用于测试检索增强生成(RAG)系统性能的全面评估数据集,源自 Paul Iusztin 和 Maxime Labonne 编著的《LLM Engineer's Handbook》。该数据集包含150个问题-答案对,旨在从多个维度评估RAG系统的性能。问题按类型、难度和测试的具体失败模式进行分类,从而可以进行RAG管道优势和弱点的细致分析。数据集覆盖了LLM工程生命的整个周期:数据收集、特征管道、微调(SFT/DPO)、RAG实施、推理优化、部署以及MLOps/LLMOps实践。
创建时间:
2025-12-01
原始信息汇总
LLM Engineers Handbook RAG Evaluation Dataset 概述
数据集基本信息
- 数据集名称:LLM Engineers Handbook RAG Evaluation Dataset
- 数据集来源:基于 Paul Iusztin 和 Maxime Labonne 所著的《LLM Engineers Handbook》(Packt Publishing,2024年10月版)构建。
- 语言:英语
- 许可证:MIT
- 数据量:包含150个问答对。
- 大小类别:n<1K
- 任务类别:问答、文本检索
- 标签:rag, evaluation, llm, retrieval-augmented-generation, mlops, llmops
数据集结构与内容
数据模式
数据集包含以下字段:
id:唯一标识符。category:完整类别名称。category_code:3字母类别代码。question:评估问题。ground_truth_answer:预期正确答案。source_chapters:包含答案的章节编号列表。source_pages:用于引用的页码列表。difficulty:难度等级(easy, medium, hard)。required_chunks:回答问题所需的最小文本块数量。must_contain:正确答案中应出现的关键词列表。failure_mode_tested:此问题测试的RAG系统方面。
问题类别
数据集包含10种问题类型,每种15个问题:
- SHF:单跳事实型 - 从单一文本段直接检索事实。
- MHR:多跳推理型 - 需要综合2-4个文本块。
- PRO:流程/操作指南型 - 分步实施问题。
- CON:概念理解型 - 定义和解释。
- CMP:比较与对比型 - 方法间的权衡分析。
- NUM:数值与定量型 - 精确数字提取。
- NEG:否定/不可回答型 - 语料库中没有答案的问题。
- AMB:模糊与未明确指定型 - 需要澄清才能回答。
- SYN:综合与总结型 - 多概念整合。
- TMP:时间与条件型 - 依赖于上下文的“何时使用”问题。
难度分布
- 简单:31个问题(21%)
- 中等:60个问题(40%)
- 困难:59个问题(39%)
主题覆盖范围
数据集覆盖了原书的全部11个章节,主题包括LLM Twin概念、工具链、数据工程管道、RAG特征管道、监督微调、偏好对齐、LLM评估、推理优化、RAG推理管道、部署以及MLOps/LLMOps。
数据集用途
直接用途
- RAG系统评估:对检索和生成质量进行基准测试。
- 回归测试:跟踪RAG系统在迭代中的性能。
- 故障模式分析:识别特定弱点(检索、推理、弃答)。
- CI/CD集成:在ML管道中进行自动化评估。
使用限制
- 仅适用于评估,不适合用于训练RAG系统。
- 问题特定于《LLM Engineers Handbook》语料库。
数据集创建
创建缘由
旨在提供针对LLM工程知识的领域特定评估,支持对特定RAG故障模式的诊断,并包含“不可回答”问题以测试幻觉预防。
数据来源与标注
- 所有问答对均源自《LLM Engineers Handbook》文本,并带有页面级引用。
- 问题类别和难度级别为人工标注。
must_contain关键词从标准答案中提取,用于自动化验证。
已知局限性与建议
局限性
- 领域特定:仅评估来自单一书籍的LLM工程知识。
- 仅限英语。
- 有时效性:提及的部分工具/版本可能过时。
- 单一来源:不测试跨多文档的检索。
使用建议
- 建议与通用RAG基准测试结合使用以进行全面评估。
- 若针对更新的书籍版本进行评估,需更新标准答案。
- 应用于不同技术语料库时,需考虑领域迁移。
评估指标与标准
推荐指标
- 正确性:与标准答案的语义相似度。
- 忠实性:答案基于检索到的上下文。
- 关键词覆盖率:所需关键词是否出现。
- 弃答准确性:对不可回答问题正确拒绝回答。
- 上下文精确率:检索到的文本块是否相关。
- 上下文召回率:是否检索到所有需要的信息。
通过标准建议
- 正确性阈值:建议为0.7。
- NEG类别:若模型弃答(如回答“我不知道”、“未指定”)则通过。
- AMB类别:若模型要求澄清则通过。
引用
若使用此数据集,请引用源书籍: bibtex @book{iusztin2024llmengineers, title={LLM Engineers Handbook}, author={Iusztin, Paul and Labonne, Maxime}, year={2024}, publisher={Packt Publishing}, isbn={978-1836200079} }
搜集汇总
数据集介绍
构建方式
在检索增强生成系统评估领域,构建高质量的数据集对于精准诊断模型性能至关重要。本数据集源自《LLM工程师手册》这一专业著作,通过系统化抽取与标注流程构建而成。其构建过程首先从书籍全文中提取核心知识点,并依据不同认知需求设计问题类型,涵盖从简单事实检索到复杂多跳推理等十种范畴。每个问题均附有标准答案、来源章节与页码引用,并标注了难度等级与必需检索块数量。为确保评估的严谨性,数据集中还特别纳入了无答案问题与模糊问题,用以检验系统的幻觉抑制与澄清请求能力。
特点
该数据集在RAG评估领域展现出鲜明的结构化与细粒度特征。其核心特点在于对问题进行了多维度的精细分类,不仅依据认知复杂度划分为十大类别,还按照难度梯度设置了易、中、硬三个等级,从而支持对系统性能的深度剖面分析。数据集内嵌了丰富的元数据,如必备关键词列表与所测试的特定失效模式,为自动化评估提供了可量化的验证锚点。此外,其问题设计全面覆盖了LLM工程生命周期的各个环节,从数据工程到部署运维,确保了评估内容与专业实践的高度相关性,为领域特定的RAG系统提供了极具针对性的评测基准。
使用方法
在具体应用层面,该数据集主要服务于RAG系统的性能评测与迭代优化。使用者可通过标准数据加载接口便捷地获取全部150个问题对,并依据类别、难度等属性进行灵活筛选,以针对特定能力维度展开评估。典型的评估流程涉及将问题输入待测RAG系统,随后从语义正确性、关键词覆盖度、上下文忠实性以及对于不可答问题的弃权准确性等多个维度分析系统输出。数据集鼓励将此类评估集成至持续集成与持续交付管道中,以实现模型性能的自动化回归测试与监控,从而系统化地识别并修复RAG流水线中的薄弱环节。
背景与挑战
背景概述
随着检索增强生成(RAG)技术在大型语言模型应用中的普及,对其性能进行系统化评估的需求日益凸显。在此背景下,LLM Engineer's Handbook RAG Evaluation Dataset应运而生,由AI Engineering社区于2024年基于Paul Iusztin与Maxime Labonne合著的《LLM Engineer's Handbook》精心构建。该数据集旨在针对LLM工程领域的专业知识,提供一套细粒度的评估基准,核心研究问题聚焦于如何精准诊断RAG系统在检索、生成及推理等多个维度的性能瓶颈。其诞生不仅填补了领域特定RAG评估工具的空白,更为LLM工程生命周期的全流程优化提供了实证基础,对推动RAG技术的标准化评测与迭代具有显著影响力。
当前挑战
该数据集致力于解决RAG系统评估中的核心挑战,即如何超越传统通用知识基准,实现对领域特定、多模态推理及抗幻觉能力的精细化测评。具体而言,其构建面临多重挑战:在问题设计上,需涵盖从单跳事实检索到多跳复杂推理的连续谱系,并精准定义未回答与模糊性问题以检验系统边界;在标注过程中,必须确保答案与原文的严格对齐,同时提取关键语义单元以支持自动化验证;此外,数据集局限于单一英文技术文献,可能无法充分评估跨文档、多源信息的检索能力,且内容随时间推移存在过时风险,这要求使用者结合动态知识进行补充评估。
常用场景
经典使用场景
在检索增强生成(RAG)系统评估领域,该数据集为研究者提供了精细化的基准测试工具。其经典应用场景在于系统性地评估RAG管道的检索准确性与生成质量,涵盖从简单事实查询到复杂多跳推理的十类问题。通过难度分级与特定失败模式标注,研究者能够深入分析系统在不同认知负荷下的表现,例如检验模型在应对模糊查询或无法回答问题时是否具备恰当的拒绝或澄清能力。
解决学术问题
该数据集有效应对了RAG评估中缺乏细粒度、领域针对性基准的学术挑战。它通过结构化的问题类别与详尽的元数据,助力研究者精确诊断系统弱点,如检索失效、幻觉生成或上下文整合不足。其意义在于推动了RAG评估从粗放的整体评分转向模块化、可解释的性能分析,为理解模型在专业领域知识上的推理边界提供了实证基础,促进了评估方法的科学化与标准化。
衍生相关工作
围绕该数据集,衍生了一系列专注于RAG评估方法学的研究与工具。例如,基于其多跳推理与合成类问题,研究者开发了更精细的上下文召回与忠实度度量指标。同时,其对于不可回答问题的标注,启发了针对模型幻觉预防与安全拒绝机制的新评估框架。这些工作共同扩展了RAG系统的评估维度,并催生了更鲁棒、可解释的评估基准与自动化测试套件。
以上内容由遇见数据集搜集并总结生成


