VCG-plus_112K
收藏魔搭社区2025-11-02 更新2025-03-22 收录
下载链接:
https://modelscope.cn/datasets/MBZUAI/VCG-plus_112K
下载链接
链接失效反馈官方服务:
资源简介:
# 👁️ VCG+ 112K Dataset
---
## 📝 Description
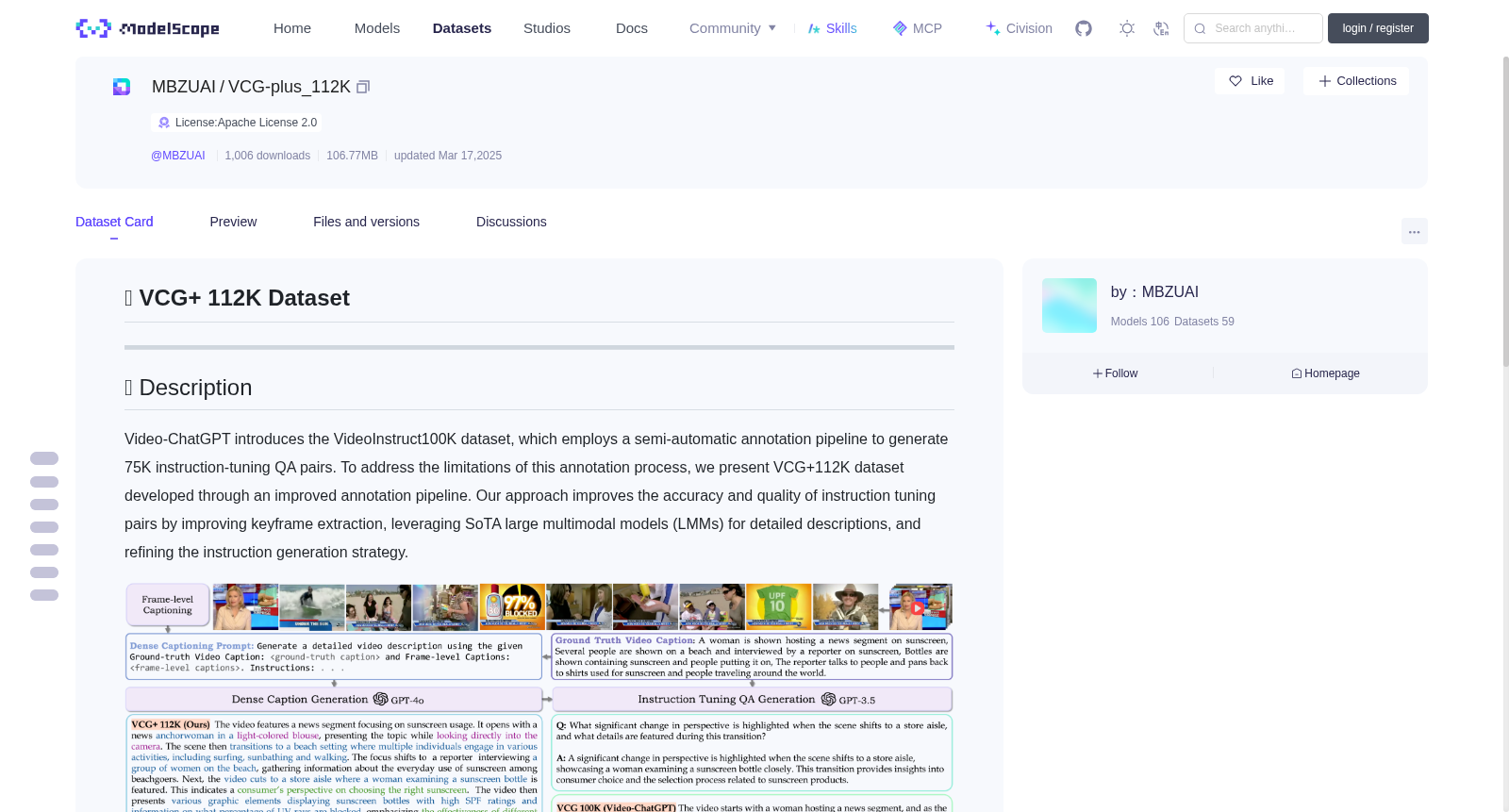
Video-ChatGPT introduces the VideoInstruct100K dataset, which employs a semi-automatic annotation pipeline to generate 75K instruction-tuning QA pairs. To address the limitations of this annotation process, we present VCG+112K dataset developed through an improved annotation pipeline. Our approach improves the accuracy and quality of instruction tuning pairs by improving keyframe extraction, leveraging SoTA large multimodal models (LMMs) for detailed descriptions, and refining the instruction generation strategy.
<p align="center">
<img src="vcg-plus112k.png" alt="Contributions">
</p>
## 💻 Download
To get started, follow these steps:
```
git lfs install
git clone https://huggingface.co/MBZUAI/VCG-plus_112K
```
## 💻 Download Videos
The videos can be downloaded from [this link](https://huggingface.co/datasets/MBZUAI/video_annotation_pipeline/blob/main/activitynet_videos.tgz).
## 📚 Dataset Annotation Pipeline
We have released our semi-automatic dataset annotation pipeline as well, which is available at [Dataset Annotation Pipeline](https://huggingface.co/datasets/MBZUAI/video_annotation_pipeline).
## 📚 Additional Resources
- **Paper:** [ArXiv](https://arxiv.org/abs/2406.09418).
- **GitHub Repository:** For training and updates: [GitHub - GLaMM](https://github.com/mbzuai-oryx/VideoGPT-plus).
- **HuggingFace Collection:** For downloading the pretrained checkpoints, VCGBench-Diverse Benchmarks and Training data, visit [HuggingFace Collection - VideoGPT+](https://huggingface.co/collections/MBZUAI/videogpt-665c8643221dda4987a67d8d).
## 📜 Citations and Acknowledgments
```bibtex
@article{Maaz2024VideoGPT+,
title={VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding},
author={Maaz, Muhammad and Rasheed, Hanoona and Khan, Salman and Khan, Fahad Shahbaz},
journal={arxiv},
year={2024},
url={https://arxiv.org/abs/2406.09418}
}
# 👁️ VCG+ 112K 数据集
---
## 📝 数据集概况
Video-ChatGPT 推出了 VideoInstruct100K 数据集,该数据集采用半自动标注流程生成了75K条指令微调问答(QA)对。为解决该标注流程存在的局限性,我们提出了经优化标注流程构建的 VCG+112K 数据集。本方法通过优化关键帧提取流程、借助当前最优的大多模态模型(Large Multimodal Models, LMMs)生成详细描述,并优化指令生成策略,从而有效提升了指令微调样本对的准确性与质量。
<p align="center">
<img src="vcg-plus112k.png" alt="研究贡献">
</p>
## 💻 数据集下载
如需部署使用,请遵循以下步骤:
git lfs install
git clone https://huggingface.co/MBZUAI/VCG-plus_112K
## 💻 视频资源下载
数据集配套视频可通过[此链接](https://huggingface.co/datasets/MBZUAI/video_annotation_pipeline/blob/main/activitynet_videos.tgz)获取。
## 📚 数据集标注流程
我们同时开源了该半自动数据集标注流程,其仓库地址为[数据集标注流程](https://huggingface.co/datasets/MBZUAI/video_annotation_pipeline)。
## 📚 补充资源
- **论文**:[ArXiv](https://arxiv.org/abs/2406.09418)
- **GitHub 仓库**:用于模型训练与版本更新:[GitHub - GLaMM](https://github.com/mbzuai-oryx/VideoGPT-plus)
- **HuggingFace 合集**:如需下载预训练检查点(checkpoint)、VCGBench-Diverse 基准测试集与训练数据,请访问 [HuggingFace 合集 - VideoGPT+](https://huggingface.co/collections/MBZUAI/videogpt-665c8643221dda4987a67d8d)。
## 📜 引用与致谢
bibtex
@article{Maaz2024VideoGPT+,
title={VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding},
author={Maaz, Muhammad and Rasheed, Hanoona and Khan, Salman and Khan, Fahad Shahbaz},
journal={arxiv},
year={2024},
url={https://arxiv.org/abs/2406.09418}
}
提供机构:
maas
创建时间:
2025-03-17
搜集汇总
数据集介绍
背景与挑战
背景概述
VCG-plus_112K是一个包含112K指令调优QA对的数据集,通过改进的注释流程提高准确性和质量,适用于视频理解任务。
以上内容由遇见数据集搜集并总结生成


