ttxy/cn_ner
收藏Hugging Face2023-05-24 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ttxy/cn_ner
下载链接
链接失效反馈官方服务:
资源简介:
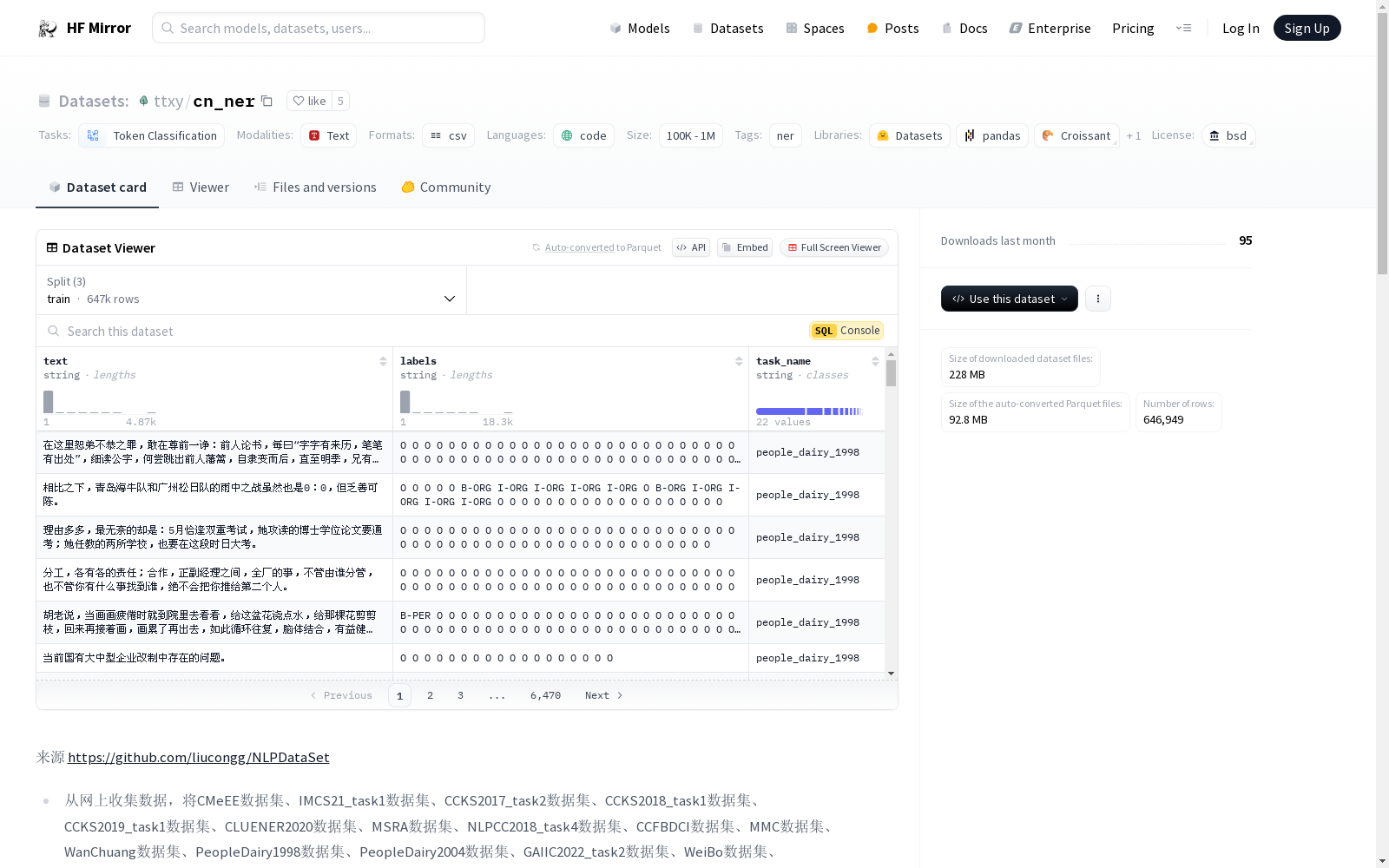
该数据集是一个中文命名实体识别(NER)数据集,通过整合和清洗22个不同的公开数据集构建而成。数据集的主要用途是用于token分类任务,特别是中文文本中的命名实体识别。数据集的构建过程包括简单的规则清洗和格式统一化,标签采用BIO格式。由于部分数据包含嵌套实体,因此在转换BIO标签时,长实体覆盖了短实体。README文件中还列出了每个原始数据集的详细信息,包括样本数量、类别和原始数据描述。
该数据集是一个中文命名实体识别(NER)数据集,通过整合和清洗22个不同的公开数据集构建而成。数据集的主要用途是用于token分类任务,特别是中文文本中的命名实体识别。数据集的构建过程包括简单的规则清洗和格式统一化,标签采用BIO格式。由于部分数据包含嵌套实体,因此在转换BIO标签时,长实体覆盖了短实体。README文件中还列出了每个原始数据集的详细信息,包括样本数量、类别和原始数据描述。
提供机构:
ttxy
原始信息汇总
数据集概述
数据集名称
- 中文ner数据集
数据集标签
- NER
许可证
- BSD
任务类别
- token-classification
数据集组成
该数据集由以下22个子数据集组成:
-
CMeEE数据集
- 样本个数:20000条
- 类别:sym、dep、dru、pro、equ、dis、mic、ite、bod
- 描述:中文医疗信息处理挑战榜CBLUE中医学实体识别数据集
-
IMCS21_task1数据集
- 样本个数:98452条
- 类别:Operation、Drug_Category、Medical_Examination、Symptom、Drug
- 描述:CCL2021第一届智能对话诊疗评测比赛命名实体识别数据集
-
CCKS2017_task2数据集
- 样本个数:2229条
- 类别:symp、dise、chec、body、cure
- 描述:CCKS2017面向电子病历的命名实体识别数据集
-
CCKS2018_task1数据集
- 样本个数:797条
- 类别:症状和体征、检查和检验、治疗、疾病和诊断、身体部位
- 描述:CCKS2018面向中文电子病历的命名实体识别数据集
-
CCKS2019_task1数据集
- 样本个数:1379条
- 类别:解剖部位、手术、疾病和诊断、药物、实验室检验、影像检查
- 描述:CCKS2019面向中文电子病历的命名实体识别数据集
-
CLUENER2020数据集
- 样本个数:12091条
- 类别:game、organization、government、movie、name、book、company、scene、position、address
- 描述:CLUENER2020数据集
-
MSRA数据集
- 样本个数:48442条
- 类别:LOC、ORG、PER
- 描述:MSRA微软亚洲研究院开源命名实体识别数据集
-
NLPCC2018_task4数据集
- 样本个数:21352条
- 类别:language、origin、theme、custom_destination、style、phone_num、destination、contact_name、age、singer、song、instrument、toplist、scene、emotion
- 描述:任务型对话系统数据数据集
-
CCFBDCI数据集
- 样本个数:15723条
- 类别:LOC、GPE、ORG、PER
- 描述:中文命名实体识别算法鲁棒性评测数据集
-
MMC数据集
- 样本个数:3498条
- 类别:Level、Method、Disease、Drug、Frequency、Amount、Operation、Pathogenesis、Test_items、Anatomy、Symptom、Duration、Treatment、Test_Value、ADE、Class、Test、Reason
- 描述:瑞金医院MMC人工智能辅助构建知识图谱大赛数据集
-
WanChuang数据集
- 样本个数:1255条
- 类别:药物剂型、疾病分组、人群、药品分组、中药功效、症状、疾病、药物成分、药物性味、食物分组、食物、证候、药品
- 描述:"万创杯”中医药天池大数据竞赛—智慧中医药应用创新挑战赛数据集
-
PeopleDairy1998数据集
- 样本个数:27818条
- 类别:LOC、ORG、PER
- 描述:人民日报1998数据集
-
PeopleDairy2004数据集
- 样本个数:286268条
- 类别:LOC、ORG、PER、T
- 描述:人民日报2004数据集
-
GAIIC2022_task2数据集
- 样本个数:40000条
- 类别:该比赛共有52种类别
- 描述:商品标题实体识别数据集
-
WeiBo数据集
- 样本个数:1890条
- 类别:LOC.NAM、LOC.NOM、PER.NAM、ORG.NOM、ORG.NAM、GPE.NAM、PER.NOM
- 描述:社交媒体中文命名实体识别数据集
-
ECommerce数据集
- 样本个数:7998条
- 类别:MISC、XH、HPPX、HCCX
- 描述:面向电商的命名实体识别数据集
-
FinanceSina数据集
- 样本个数:1579条
- 类别:LOC、GPE、ORG、PER
- 描述:新浪财经爬取中文命名实体识别数据集
-
BoSon数据集
- 样本个数:2000条
- 类别:time、product_name、person_name、location、org_name、company_name
- 描述:玻森中文命名实体识别数据集
-
Resume数据集
- 样本个数:4761条
- 类别:NAME、EDU、LOC、ORG、PRO、TITLE、CONT、RACE
- 描述:中国股市上市公司高管的简历
-
Bank数据集
- 样本个数:10000条
- 类别:BANK、COMMENTS_ADJ、COMMENTS_N、PRODUCT
- 描述:银行借贷数据数据集
-
FNED数据集
- 样本个数:10500条
- 类别:LOC、GPE、ORG、EQU、TIME、FAC、PER
- 描述:高鲁棒性要求下的领域事件检测数据集
-
DLNER数据集
- 样本个数:28897条
- 类别:Location、Thing、Abstract、Organization、Metric、Time、Physical、Person、Term
- 描述:语篇级命名实体识别数据集
数据集处理
- 清洗及格式转换后的数据下载链接:百度云 / 提取码:4sea
- 注意:部分嵌套实体的数据,使用长实体覆盖了短实体,有嵌套实体需求的同学,请自行使用原始数据。
搜集汇总
数据集介绍
构建方式
该数据集通过整合22个不同来源的中文命名实体识别(NER)数据集构建而成,涵盖了医疗、金融、社交媒体、电商等多个领域。数据集的构建过程包括从多个公开数据集中收集原始数据,并进行简单的规则清洗和格式统一化处理,最终将所有数据转换为BIO标签格式。由于部分数据包含嵌套实体,处理时采用了长实体覆盖短实体的策略。
特点
该数据集具有广泛的应用领域和多样化的实体类别,涵盖了从医疗到金融、从社交媒体到电商等多个场景。数据集的标签采用BIO格式,便于模型训练和评估。此外,数据集的多样性和规模使其成为中文NER任务的理想选择,尤其适用于需要处理复杂嵌套实体的场景。
使用方法
用户可以通过下载清洗及格式转换后的数据集进行模型训练和评估。数据集提供了详细的类别信息和样本数量,便于用户根据具体需求选择合适的子集。对于需要处理嵌套实体的用户,建议直接使用原始数据进行进一步处理。数据集的下载链接和提取码已在README中提供,用户可据此获取所需数据。
背景与挑战
背景概述
中文命名实体识别(NER)在自然语言处理领域中占据重要地位,旨在从文本中提取出特定类别的实体。ttxy/cn_ner数据集由南京理工大学(NJUST-TB)的研究团队整理,汇集了来自22个不同来源的数据集,涵盖医疗、金融、社交媒体等多个领域。该数据集的构建旨在为中文NER研究提供一个全面且多样化的资源,支持实体识别任务的训练与评估。通过整合多个领域的数据,该数据集不仅丰富了中文NER的语料库,还为跨领域的实体识别研究提供了宝贵的资源。
当前挑战
构建ttxy/cn_ner数据集面临的主要挑战包括数据来源的多样性和数据清洗的复杂性。首先,不同数据集的标签体系和格式各异,导致在统一化过程中需要进行大量的规则清洗和格式转换。其次,部分数据集包含嵌套实体,这在转换为BIO标签时会导致长实体覆盖短实体的问题,影响实体识别的准确性。此外,数据集的多样性虽然丰富了研究内容,但也增加了模型在不同领域间迁移学习的难度。
常用场景
经典使用场景
ttxy/cn_ner数据集在自然语言处理领域中,主要用于中文命名实体识别(NER)任务。该数据集整合了多个领域的NER数据,涵盖医疗、金融、电商、社交媒体等多个场景,为研究者提供了丰富的语料资源。通过该数据集,研究者可以训练和评估中文NER模型,识别文本中的实体类别,如人名、地名、组织名等,广泛应用于信息抽取、知识图谱构建等任务。
解决学术问题
ttxy/cn_ner数据集解决了中文命名实体识别领域中数据多样性和覆盖面不足的问题。通过整合多个领域的数据集,该数据集为研究者提供了丰富的语料资源,有助于提升模型的泛化能力和鲁棒性。此外,该数据集还解决了部分数据集标注不一致、格式不统一的问题,通过统一的BIO标签格式,简化了数据处理流程,推动了中文NER研究的进展。
衍生相关工作
ttxy/cn_ner数据集的发布催生了一系列相关研究工作。研究者基于该数据集开发了多种中文NER模型,如基于BERT的预训练模型、基于LSTM的序列标注模型等,显著提升了中文NER的性能。此外,该数据集还推动了嵌套实体识别、跨领域NER等前沿研究方向的发展。相关研究成果已在多个学术会议上发表,并应用于实际系统中,进一步推动了中文自然语言处理技术的进步。
以上内容由遇见数据集搜集并总结生成


