g8a9/europarl_en-it
收藏Hugging Face2022-09-07 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/g8a9/europarl_en-it
下载链接
链接失效反馈官方服务:
资源简介:
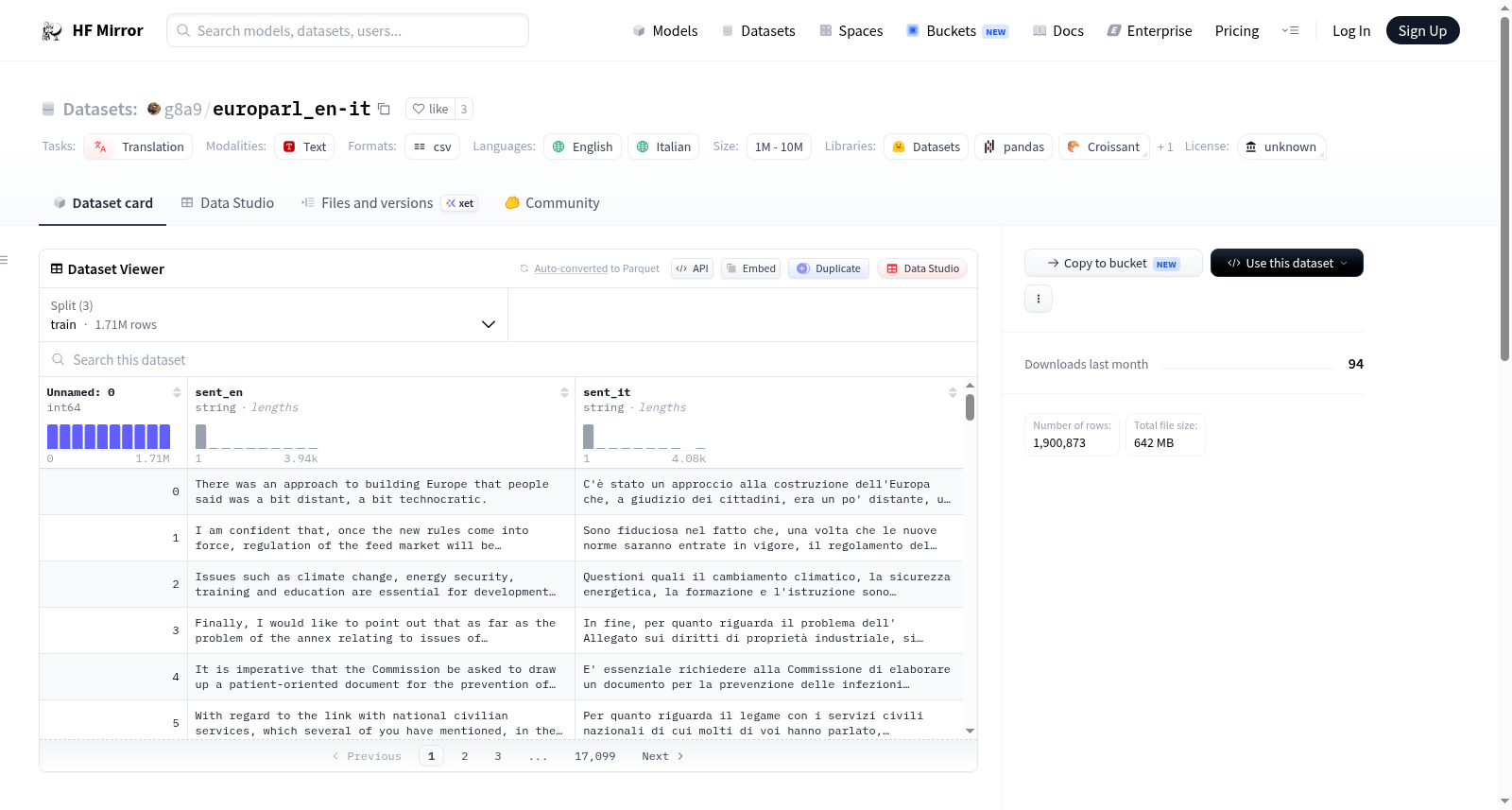
该数据集仅包含Europarl v7的英语-意大利语分割部分。创建该数据集的目的是为了提供给M2L 2022夏季学校的学生使用。数据集包含英语转录和意大利语翻译两个字段,并提供了自定义的训练/验证/测试分割。
提供机构:
g8a9
原始信息汇总
数据集概述:Europarl v7 (en-it split)
数据集描述
- 名称:Europarl v7 (en-it split)
- 语言:
- 源语言:英语(en)
- 目标语言:意大利语(it)
- 类型:
- 单语
- 翻译
- 用途:为M2L 2022 Summer School学生提供。
数据集结构
数据字段
- sent_en:英语文本
- sent_it:意大利语翻译
数据分割
- 训练集:1717204对
- 验证集:190911对
- 测试集:1000对
引用信息
若使用此数据集,请引用:
Koehn, P. (2005). Europarl: A parallel corpus for statistical machine translation. In Proceedings of machine translation summit x: papers (pp. 79-86).
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是Europarl v7的英语-意大利语平行语料分块,包含约190万行欧洲议会演讲的翻译对,专门用于机器翻译任务。数据集提供了自定义的训练、验证和测试划分,每行数据包含英语原文(sent_en)和对应的意大利语翻译(sent_it),适合用于训练和评估翻译模型。
以上内容由遇见数据集搜集并总结生成


