jackf857/qwen3-8b-base-new-dpo-hh-harmless-4xh200-batch-64-q_t-0.45-eta-0.1-s_star-0.6-margin-log
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/jackf857/qwen3-8b-base-new-dpo-hh-harmless-4xh200-batch-64-q_t-0.45-eta-0.1-s_star-0.6-margin-log
下载链接
链接失效反馈官方服务:
资源简介:
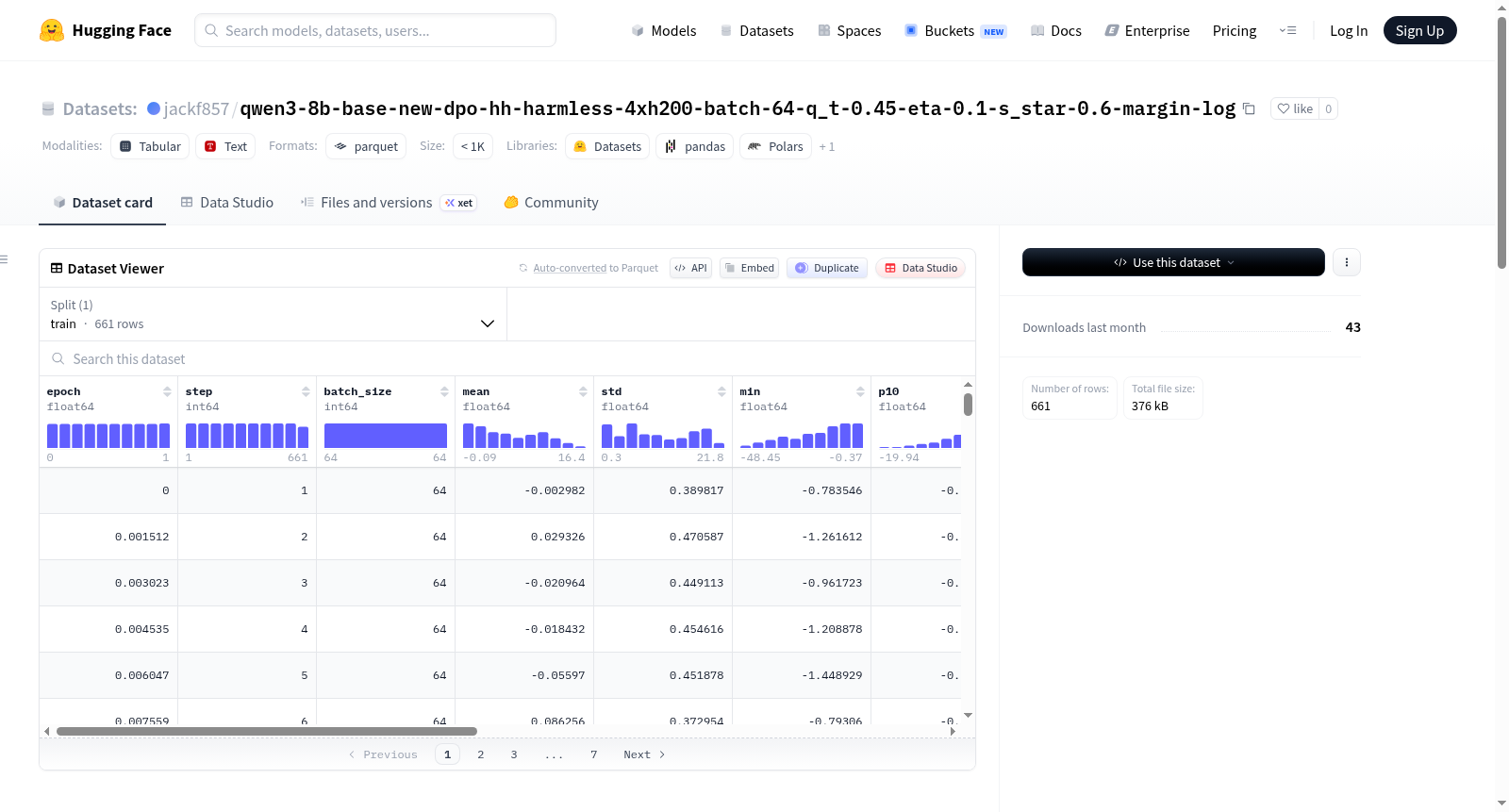
该数据集是从一个名为New-DPO的训练运行中导出的每步边际摘要统计。它包含了训练过程中的多个特征,如epoch(训练轮数)、step(步骤)、batch_size(批次大小)、mean(平均值)、std(标准差)、min(最小值)、p10(第10百分位数)、median(中位数)、p90(第90百分位数)、max(最大值)、pos_frac(正分数)、sample(每个示例的边际值)以及npy(保存的完整数组路径)。数据集来源于特定的模型训练运行,使用了Anthropic/hh-rlhf数据集作为混合器,并涉及特定的训练参数如beta、f_divergence_type等。
This dataset contains per-step margin summary statistics exported from a New-DPO training run. It includes various features from the training process such as epoch, step, batch_size, mean, std, min, p10, median, p90, max, pos_frac, sample (per-example margins), and npy (optional path to the saved full margin array). The dataset originates from a specific model training run, using the Anthropic/hh-rlhf dataset as a mixer, and involves specific training parameters like beta, f_divergence_type, etc.
提供机构:
jackf857
搜集汇总
数据集介绍
构建方式
本数据集源自对Qwen3-8B基座模型进行New-DPO策略微调的训练过程,具体基于HH-RLHF数据集中“harmless”子集构建。训练过程中,以每步有效批次内的样本边际偏好得分(margin)为核心,系统采集并汇总了661条训练数据。每个样本记录了包括均值、标准差、分位数、正样本比例等在内的十项统计量,并可选地通过`npy`字段保存完整的边际向量矩阵,从而为偏好对齐训练的监控与事后分析提供了完备的数值基础。
特点
该数据集的核心特点在于其结构化地呈现了New-DPO训练过程中各关键超参数对边际分布的影响。数据不仅包含了经典的均值、极值与分位数统计,还引入了`pos_frac`与`sample`字段,分别反映正样本占比及逐样本边际分布。配合`epoch`与`step`标签,可精确追溯训练进程。其设计兼顾了简洁性与深度,既适合快速概览训练状态,也支持对边际分布的细粒度研究。
使用方法
用户可通过HuggingFace Datasets库直接加载该数据集,指定`split='train'`即可获取全部661条记录。借助`pandas`等数据科学工具可快速进行统计分析与可视化,例如绘制边际均值随训练步数的演化曲线或探索超参数`q_target`、`eta`等对分布形态的调控效应。`npy`字段提供了访问完整边际向量的路径,便于进行更深层次的分布对比与模型行为诊断。
背景与挑战
背景概述
基于人类反馈的强化学习(RLHF)技术在大语言模型对齐领域取得了显著成效,其中直接偏好优化(DPO)及其变体New-DPO通过消除显式奖励模型,简化了传统RLHF流程,提升了训练效率与稳定性。该数据集由研究人员jackf857于2025年基于Qwen3-8B模型构建,核心研究问题在于探索New-DPO训练过程中边际(margin)统计量的动态变化,并试图通过调节超参数如q_target、eta和s_star来优化无害性对齐效果。数据集来源于Anthropic的hh-rlhf无害性子集,记录了661个训练步的边际分布特征,为理解不同超参数配置下模型偏好学习的收敛行为提供了实证基础,对推动DPO变体的细粒度超参数调优与机制分析具有重要参考价值。
当前挑战
该数据集所解决的领域问题在于:传统DPO方法对生成的成对数据间边际分布信息利用不足,难以在无害性对齐中有效平衡模型的有用性与安全性。New-DPO通过引入f-散度与动态边际约束,旨在弥合这一缺口,但超参数敏感度高,特定配置下边际演化规律仍不清晰。构建过程中面临的挑战包括:对训练步级边际全数组进行存储与序列化,数据体积随训练步数线性增长,且需同步采集多个统计量(如均值、分位数、正样本比例)以支撑后续分析;此外,不同超参数组合下的训练日志管理、与W&B实验追踪系统的集成,以及确保边际计算与原始奖励信号的一致性,均增加了数据生产的复杂性。
常用场景
经典使用场景
在偏好对齐与强化学习从人类反馈(RLHF)的研究领域中,该数据集作为New-DPO训练过程中逐步边际统计量的记录集合,其经典应用场景在于监测与评估语言模型在优化阶段的偏好分布演变。研究人员通过解析每批次样本的边际均值、标准差、分位数及正样本比例等指标,得以深入洞察模型从初始状态向人类偏好趋近的动态轨迹。该数据集尤其适用于复现和改进New-DPO算法,通过精确的边际信息校准训练策略,例如调整目标策略偏移量q_t、散度约束系数eta及最优响应基准s_star等核心超参数,从而在无害性偏好数据集Anthropic/hh-rlhf上实现更加稳健的对齐效果。
解决学术问题
该数据集聚焦于解决直接偏好优化(DPO)及其变体在训练过程中普遍存在的边际信息缺失与超参数调优困难问题。传统方法通常仅记录最终模型性能,而忽略了对优化路径中逐步骤边缘行为的细致刻画,导致研究者难以诊断训练震荡、模式坍塌或过度优化等现象。通过提供每步训练的边际完整统计量(包含均值、标准差、十分位数及正样本分布),该数据集使得学术界能够系统地分析不同超参数组合如何影响偏好边界的收敛速度与稳定性,揭示了f散度类型、alpha散度系数、s_star阈值与eta松弛因子之间的复杂交互作用。这些见解对于深化理解偏好对齐过程中的信息几何与概率约束机制具有重要理论意义,为设计更高效、更可靠的下一代偏好优化算法奠定了数据基础。
衍生相关工作
该数据集的发布催生了一系列相关联的研究工作。一方面,研究者利用其逐步骤边际信息构建了多维偏好学习速率调度框架,探索了基于边际标准差和p90/p10比值的自适应学习率调整策略,形成了New-DPO+算法族。另一方面,数据集中所记录的pos_frac时序变化激发了关于正样本比例滞后的理论分析,衍生出基于平衡自举采样的新式偏好数据集扩增方法。此外,该数据集还与TRL库中的DPOTrainer整合,作为标准评估基准被广泛应用于Llama、Gemma等主流开源模型的偏好对齐实验中。最新的延续性工作包括将边际统计与流形学习结合,提出了偏好嵌入空间的几何正则化方案,显著提升了跨分布偏好泛化能力。
以上内容由遇见数据集搜集并总结生成


