hunarbatra/4DReasoner_v3_test
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/hunarbatra/4DReasoner_v3_test
下载链接
链接失效反馈官方服务:
资源简介:
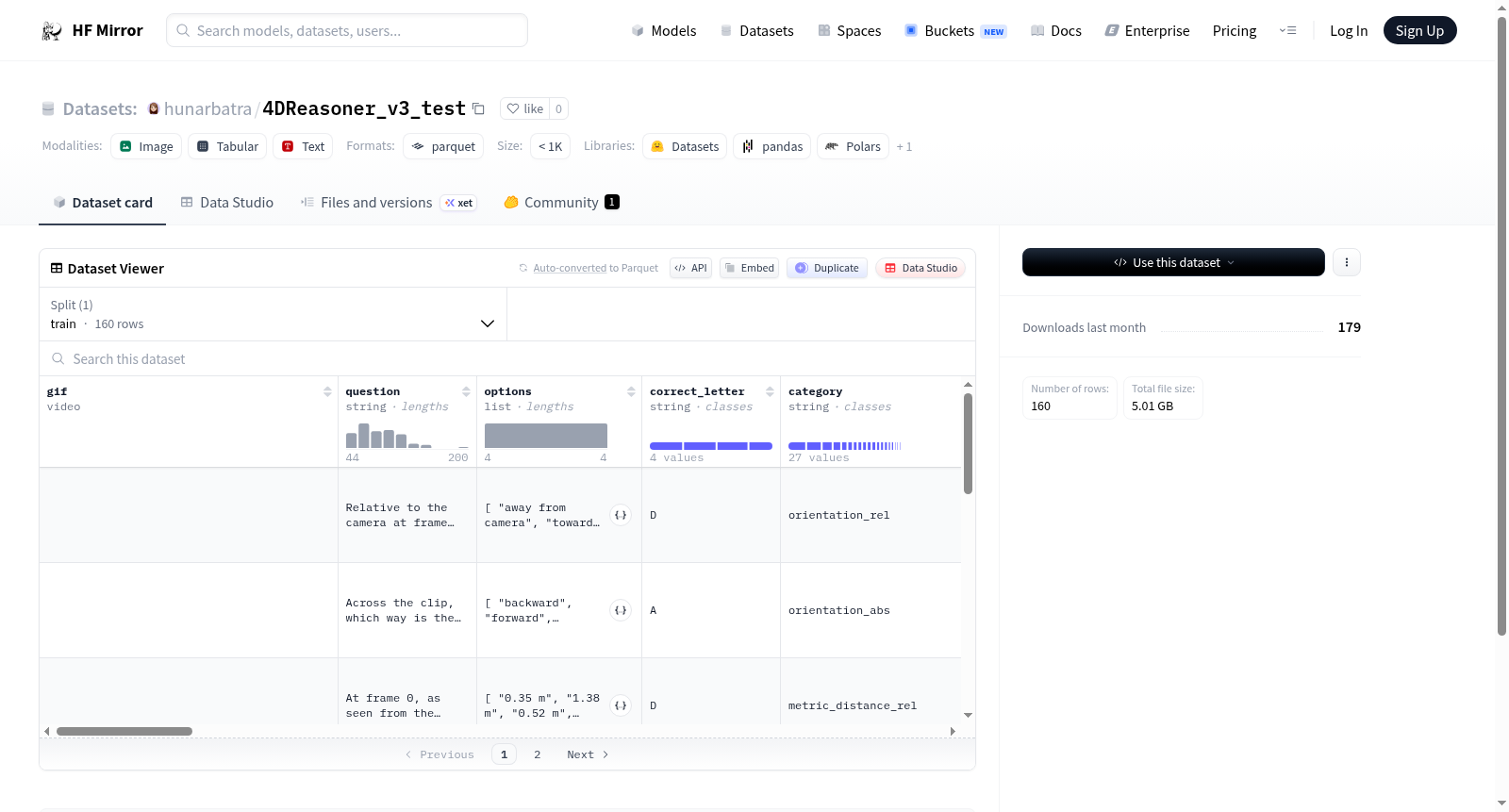
该数据集是一个视频问答数据集,包含视频、问题、选项、正确答案、类别、推理质量、推理数量、难度等多个维度的信息。数据集还提供了视频ID、字幕、引用事实ID、上下文事实ID、候选事实、4D事实、提取的4D数据、帧类型、视频复杂度、上下文模式、来源数据集等详细信息,适用于视频问答、推理任务或多模态学习等研究领域。
This dataset is a video question-answering dataset that includes multiple dimensions of information such as videos, questions, options, correct answers, categories, reasoning quality, reasoning quantity, and difficulty. The dataset also provides detailed information such as video ID, captions, cited fact ID, context fact IDs, candidate facts, 4D facts, extracted 4D data, frame type, video complexity, context mode, and source dataset, making it suitable for research areas such as video question-answering, reasoning tasks, or multimodal learning.
提供机构:
hunarbatra
搜集汇总
数据集介绍
构建方式
4DReasoner_v3_test数据集的构建立足于三维空间与时间维度的深度融合,旨在推动时空推理领域的研究进展。该数据集通过从多源视频库中精选素材,并辅以精细化的四维事实标注,将动态视觉内容转化为结构化的推理任务。构建过程中,每一视频片段均被赋予高层次语义描述(caption)与细粒度时空事实(4D_facts),同时提取出关键帧路径与时间戳信息,确保时空一致性与推理链条的完整性。数据集的标注体系涵盖定性与定量两种推理维度(reasoning_qual与reasoning_quant),并引入链式思维提示(cot_gen_prompt)以模拟人类逐步推理的过程,最终形成包含问题、选项、正确答案及复杂上下文事实的多层次结构。
特点
该数据集最显著的特点在于其多维度的时空推理能力和丰富的上下文事实嵌入。与常规视频问答数据集不同,4DReasoner_v3_test不仅关注静态视觉内容,更强调物体在四维空间中的运动轨迹与变化关系,通过候选事实(candidate_facts)与引用事实ID(cited_fact_id)构建起事实间的逻辑网络。数据集的难度分级(difficulty)与视频复杂度评分(video_complexity)为模型评估提供了细粒度基准,而帧类型(frame_type)与采样帧率(frame_sample_fps)的多样性则模拟了真实世界中不规则的视觉采样场景。此外,ShareGPT格式的链式思维标注(sharegpt_cot_qual与sharegpt_cot_quant)为训练可解释性推理模型提供了天然的监督信号。
使用方法
研究者可直接通过HuggingFace Datasets库加载该数据集,利用内置的train分割进行模型训练与评估。数据集以标准特征列形式组织,其中gif字段存储动态视频数据,question与options字段构成多选问答对,correct_letter标注标准答案。进阶使用者可借助4D_facts与extracted_4d_data字段实施时空推理训练,或利用sharegpt_cot_qual与sharegpt_cot_quant中的链式思维对话结构进行启发式学习。对于需要上下文增强的场景,candidate_facts与context_fact_ids提供了丰富的事实背景,而frame_paths与timestamps则支持基于关键帧的模态对齐实验。推荐将数据组织为训练-验证集,并依据difficulty与video_complexity字段进行分层采样以优化模型泛化能力。
背景与挑战
背景概述
4DReasoner_v3_test数据集诞生于对视频理解与时空推理能力深入探索的背景下,由相关研究机构精心构建,旨在解决视频问答领域中复杂的动态与静态要素交互推理问题。该数据集聚焦于四维(4D:三维空间加时间维度)空间内的推理任务,要求模型不仅理解视频中的对象、动作与事件,还需捕捉它们随时间演变的因果关系及逻辑序列。通过融入多模态信息(如视频片段、自然语言问答、推理链等),该数据集为评估和提升AI系统在动态场景中的因果与时空推理能力提供了标准化的测试平台,对推动视频理解、机器人自主决策及人机交互等领域的进步具有重要影响。
当前挑战
该数据集面临的挑战主要体现在两个层面。在领域问题上,4D推理超越了传统的视频分类或动作识别,要求模型处理对象在三维空间中的运动轨迹、遮挡关系以及事件间的复杂因果链,这对现有模型的长时记忆与符号推理能力构成了严峻考验。在构建过程中,挑战在于如何从原始视频中精准提取并标注出4D空间-时间事实(如对象随时间的位置、速度、相互作用等),同时保证多视角帧采样的均匀性与标注的语义一致性,尤其是对于包含细微动作或长时依赖的复杂场景,确保推理链的可靠性与多样性极为困难。
常用场景
经典使用场景
在视频理解与推理的前沿探索中,4DReasoner_v3_test数据集以其独特的四维时空标注结构,成为评估和训练视觉语言模型在动态场景中执行复杂推理能力的标杆。该数据集包含丰富的视频片段、多选问题、时空事实链以及推理质量标注,广泛应用于多模态大语言模型的细粒度时空推理能力测试。研究者借助该数据集,可系统性地考察模型对视频中物体运动轨迹、时序因果逻辑以及空间关系变化的捕捉与理解,从而推动从静态图像理解向动态视频推理的范式跃迁。
实际应用
在实际应用层面,4DReasoner_v3_test所驱动的技术可直接赋能自动驾驶场景中的动态目标预测与行为意图理解,使系统能够基于连续帧的时空信息预判行人或车辆的移动趋势。此外,在智能监控、工业质检和体育赛事分析等领域,基于该数据集训练的模型能够精准解析复杂视频中的阶段性动作与异常事件,提升自动化决策的可靠性。其框架也为人机交互中的视频内容智能检索与摘要生成提供了坚实的评测基石。
衍生相关工作
围绕4DReasoner_v3_test,衍生出多项关键性研究工作,例如基于思维链推理的视频问答模型(VideoCOT),通过显式建模4D事实来提升推理的透明度和准确性。另有工作提出时空注意力增强架构,专门针对数据集中的时序因果链进行优化,在长视频推理任务上取得了突破性进展。此外,该数据集催生了关于多模态推理评估准则的讨论,促进了如GPT-4V、Gemini等顶尖模型在动态场景下的系统性对比评测,确立了时空推理能力作为通用视觉智能核心维度的学术共识。
以上内容由遇见数据集搜集并总结生成


