KoDetox
收藏KoDetox: 韩国仇恨言论净化配对数据集
数据集概述
- 目的:用于韩语毒性语言缓解、指令调优和对齐调优(如DPO、PPO)
- 语言:韩语
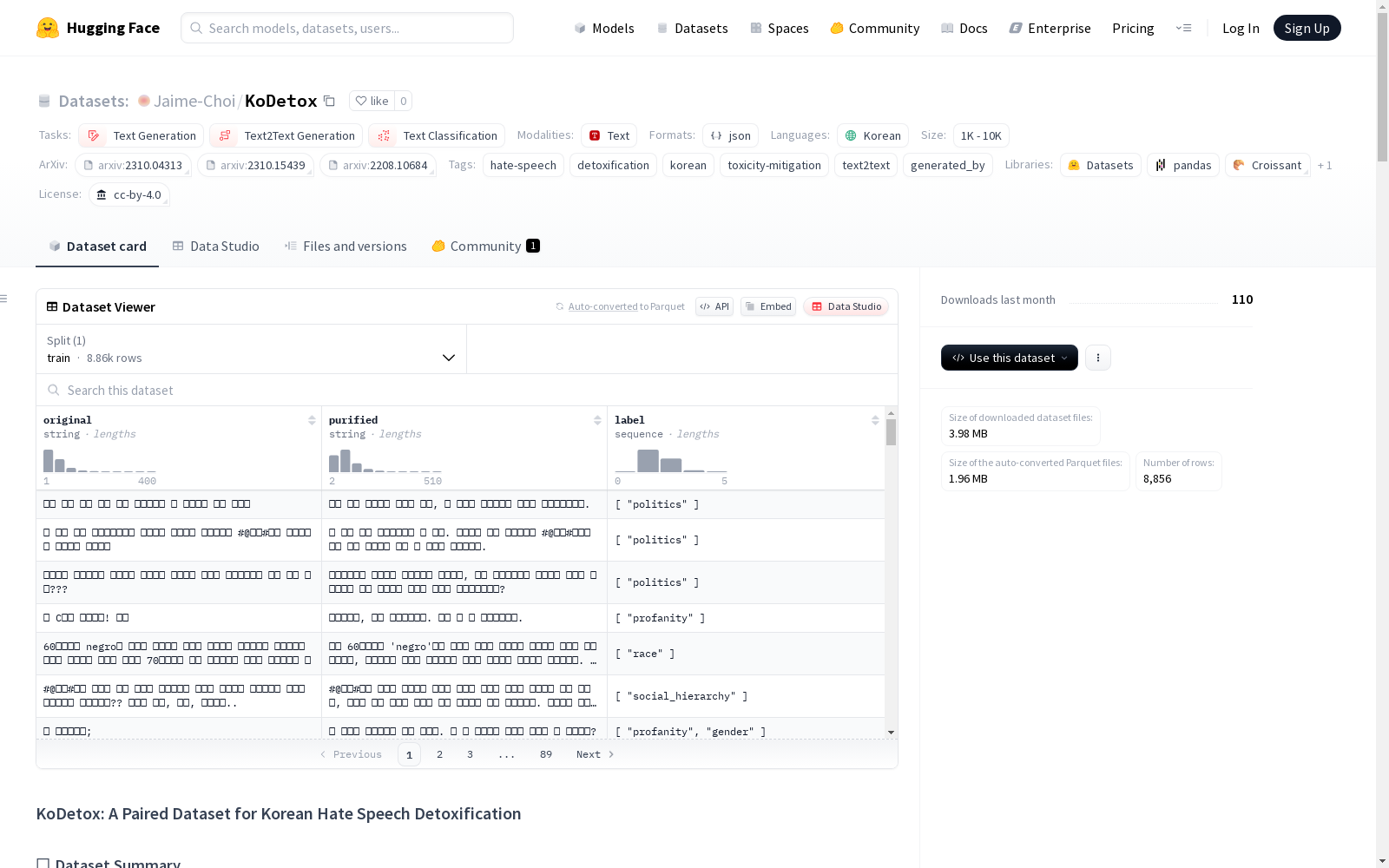
- 规模:8,856对毒性评论与净化版本
- 许可证:CC BY 4.0
- 生成模型:Qwen3-14B
数据结构
数据格式
- 每个样本为JSON对象,包含:
original:原始毒性评论purified:净化版本(保留核心含义,减少攻击性)label:9个细粒度仇恨言论类别的多标签
统计信息
- 总样本数:8,856
- 标签类别数:9
- 最频繁标签:politics(3,758次)
文本长度
| 评论类型 | 平均长度 | 最大长度 |
|---|---|---|
| Original | 56.0字符 | 400字符 |
| Purified | 87.6字符 | 510字符 |
标签分布
- 9个仇恨类别:
politics,profanity,gender,race,age,region,physical_disability,social_hierarchy,religion
生成过程
数据来源
- 从以下数据集收集原始韩语仇恨评论:
- K-MHaS
- KoMultiText
- K-HATERS
净化生成
- 使用Qwen3-14B模型生成净化版本
- 采用一致的指令模板进行批处理推理
后处理
- 直接解析模型输出,无人工干预
- 过滤确保基本格式正确性和净化质量
伦理考虑
- 包含潜在冒犯性语言
- 净化质量可能因样本而异
引用
bash @misc{KoDetox2025, title = {KoDetox: A Paired Dataset for Korean Hate Speech Detoxification}, author = {Haemin Choi, Soohwa Kwon, Jinwoo Son, Sungjun Kang}, year = {2025}, howpublished = {https://huggingface.co/datasets/Jaime-Choi/KoDetox}, note = {A Korean dataset of toxic and detoxified comment pairs for alignment and detoxification tasks.} }
贡献者
- Haemin Choi(成均馆大学数据科学学士)
- Soohwa Kwon(成均馆大学数据科学学士)
- Jinwoo Shon(成均馆大学心理学学士)
- Sungjun Kang(成均馆大学工商管理学士)
参考文献
bash @article{lee2022k, title={K-MHaS: A multi-label hate speech detection dataset in Korean online news comment}, author={Lee, Jean and Lim, Taejun and Lee, Heejun and Jo, Bogeun and Kim, Yangsok and Yoon, Heegeun and Han, Soyeon Caren}, journal={arXiv preprint arXiv:2208.10684}, year={2022} } @article{park2023k, title={K-haters: A hate speech detection corpus in korean with target-specific ratings}, author={Park, Chaewon and Kim, Soohwan and Park, Kyubyong and Park, Kunwoo}, journal={arXiv preprint arXiv:2310.15439}, year={2023} } @article{choi2023komultitext, title={KoMultiText: Large-Scale Korean Text Dataset for Classifying Biased Speech in Real-World Online Services}, author={Choi, Dasol and Song, Jooyoung and Lee, Eunsun and Seo, Jinwoo and Park, Heejune and Na, Dongbin}, journal={arXiv preprint arXiv:2310.04313}, year={2023} }