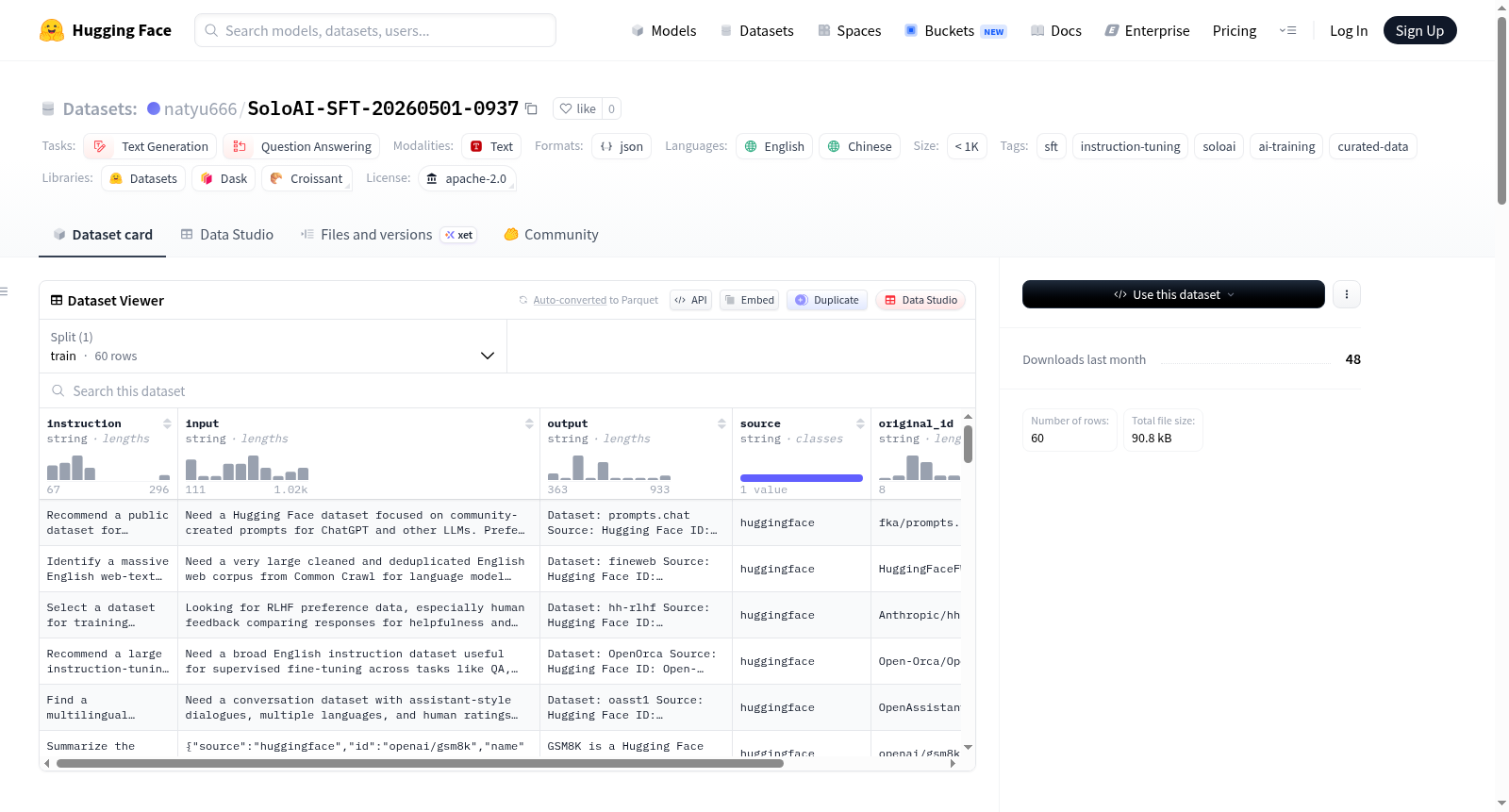
natyu666/SoloAI-SFT-20260501-0937
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/natyu666/SoloAI-SFT-20260501-0937
下载链接
链接失效反馈官方服务:
资源简介:
SoloAI SFT数据集是一个用于指令微调(Instruction Tuning)和对话型AI助手训练的数据集,包含30条数据,格式为Instruction-Input-Output。数据集支持英文和中文,适用于LLM指令微调、Prompt Engineering研究和多语言支持。数据源来自HuggingFace Datasets Hub,经过AI清洗和质量过滤后发布。
The SoloAI SFT Dataset is designed for instruction tuning and training conversational AI assistants, containing 30 entries in Instruction-Input-Output format. It supports both English and Chinese, making it suitable for LLM instruction tuning, prompt engineering research, and multilingual applications. The dataset is sourced from HuggingFace Datasets Hub, processed and quality-filtered by AI before release.
提供机构:
natyu666
搜集汇总
数据集介绍
构建方式
SoloAI-SFT-20260501-0937数据集由SoloAI自动化数据管道精心构建而成,其数据源精选自HuggingFace Datasets Hub上高质量的开源数据资源。经过AI驱动的智能清洗与转换流程,原始数据被系统性地重组为标准的Instruction-Input-Output三字段结构,每条样本均包含明确的任务指令、相关上下文输入及期望输出。最后,经由严格的质量过滤机制,最终筛选出30条高质量数据,形成这一适用于指令调优的精细数据集。
特点
本数据集虽规模精简,但特点鲜明:其数据格式高度规范,以指令-输入-输出的三元组形式呈现,便于直接用于大型语言模型的监督微调。数据集支持英文与中文双语内容,兼顾多语言场景下的指令调优需求。此外,每条样本经过自动化管道的精炼与质量把关,确保了数据的纯净度与实用性,在保持样本代表性的同时,降低了噪声干扰,适合用于Prompt工程研究与对话型AI助手的定向训练。
使用方法
该数据集主要面向LLM指令微调与Prompt工程研究场景。使用时,可直接读取JSON格式数据,将instruction字段作为模型的任务描述,input字段作为上下文输入,output字段作为监督目标,构建标准的微调样本。研究者可基于此数据集开展对话型AI的训练实验,或分析指令设计对模型输出的影响。对于需要大规模或定制化数据的用户,数据集标注了商业合作通道,可联系定制服务以扩展数据规模或适配特定行业领域。
背景与挑战
背景概述
随着大语言模型(LLM)在对话系统与指令执行中的广泛应用,高质量的监督微调(SFT)数据成为提升模型指令遵循能力与多语言适应性的关键资源。SoloAI-SFT-20260501-0937 数据集由 SoloAI 自动化数据管道于 2026 年 5 月 1 日生成,旨在提供精炼的 Instruction-Input-Output 格式数据,支撑 LLM 指令微调、提示工程研究及多语言(中英文)对话模型训练。该数据集从 HuggingFace Datasets Hub 中筛选高质量社区资源,经自动化清洗与过滤后发布,虽然初始规模仅 30 条,但代表了一种面向特定需求的高效数据构建范式,为研究者在有限预算下探索指令调优策略提供了轻量级起点。
当前挑战
该数据集所面临的挑战体现在多个层面。在领域问题层面,大语言模型在指令微调中常遭遇训练数据噪声多、指令多样性不足以及跨语言泛化能力弱等问题,数据集虽聚焦多语言与指令格式,但 30 条的极小规模难以覆盖真实场景中的复杂指令分布,导致模型可能过度拟合有限样本。在构建过程中,从海量 HuggingFace 数据集中自动提取并清洗为统一 SFT 格式,面临字段对齐、质量过滤标准不一以及标签噪声引入等技术难点;此外,细粒度上下文依赖(如 instruction 与 input 的边界模糊)和输出期望的多样性把控,进一步增加了数据管道的准确性挑战。
常用场景
经典使用场景
在大型语言模型的研发与优化历程中,指令微调(Instruction Tuning)已成为提升模型遵循人类意图能力的关键技术。该数据集以经典的 Instruction-Input-Output 三元组格式构建,为研究者提供了精炼且高质量的微调样本,尤其适用于训练对话型AI助手。通过引入包含中英文的双语任务指令与对应的期望输出,它能够高效赋能模型在多语言场景下理解复杂指令并生成准确回复,是构建更安全、更可控语言模型不可或缺的基础资源。
衍生相关工作
依托该数据集所坚守的结构化微调范式,学术界与工业界已衍生出一系列创新工作。研究者基于此类数据格式开发了更高效的微调策略,如低秩适配(LoRA)与参数高效微调方法,将其核心样本扩展至更大规模的多任务学习框架。同时,该数据集的清洗与构建流程本身也启发了一套自动化数据管道的设计理念,促进了SFT数据标准化与质量评估指标体系的建立,催生了多个聚焦于指令数据增强与蒸馏的开源项目,持续推动着语言模型对齐技术的发展边界。
数据集最近研究
最新研究方向
SoloAI-SFT-20260501-0937 数据集聚焦于指令微调(SFT)与提示工程的前沿交叉领域,涵盖中英双语场景下的高质量对话数据生成。当前研究方向包括利用自动化数据管道从 Hugging Face 等社区筛选优质提示数据,构建 Instruction-Input-Output 格式的微调样本,以提升大型语言模型(LLM)在复杂指令遵循与多轮交互中的表现。该数据集与 ChatGPT、Claude 等主流模型的热点应用紧密关联,其精心设计的标签体系(如 prompt-engineering、conversational-ai)为研究社区提供了标准化的实验基准。通过开放许可(Apache-2.0)和较小的规模(30条),它特别适用于快速原型验证与提示策略优化,推动了少样本学习与个性化助手调优的实践探索。
以上内容由遇见数据集搜集并总结生成


