mental_health
收藏Hugging Face2025-06-18 更新2025-06-19 收录
下载链接:
https://huggingface.co/datasets/sahil007123/mental_health
下载链接
链接失效反馈官方服务:
资源简介:
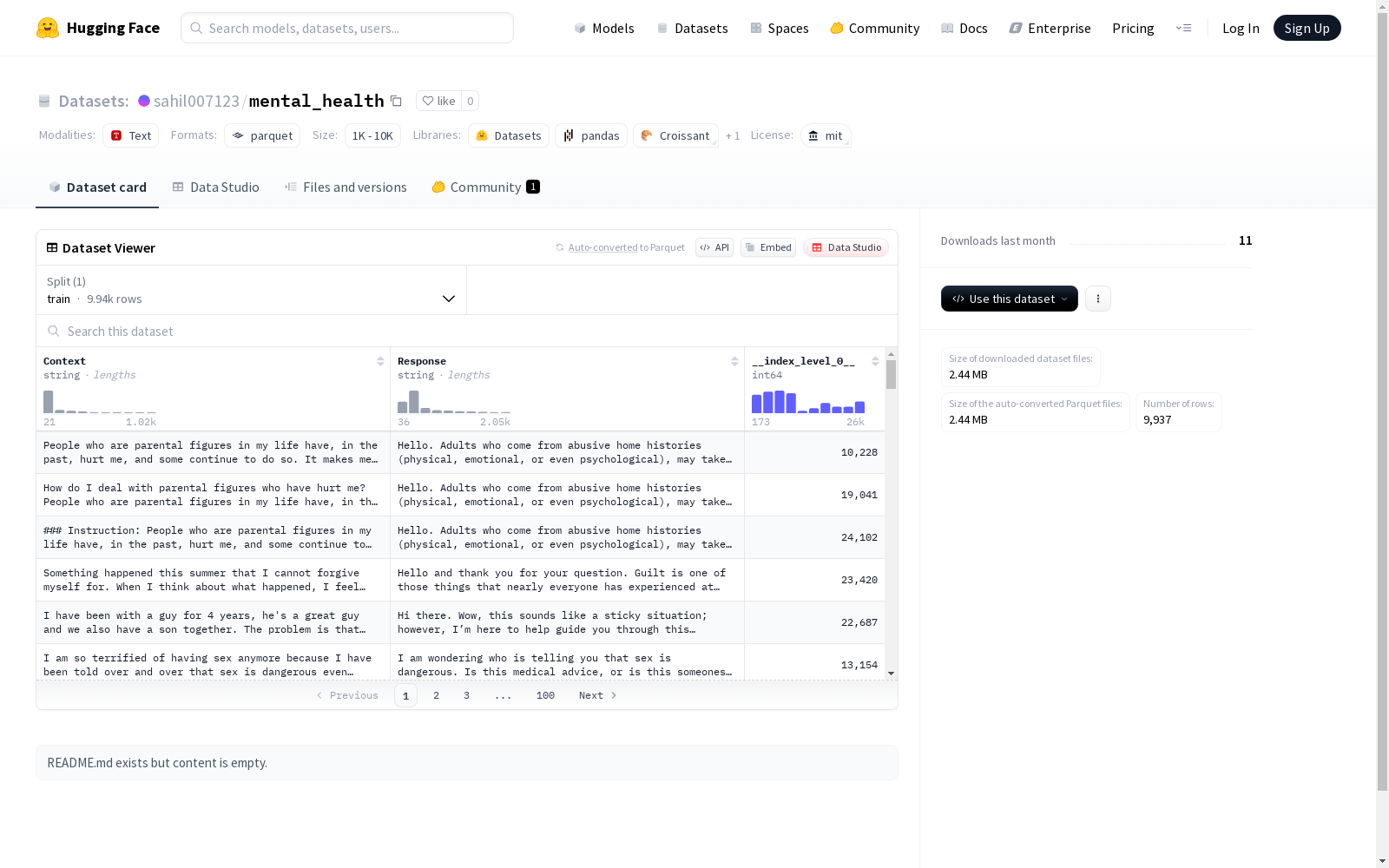
该数据集包含上下文和对应的响应对话,适用于训练对话模型。数据集分为训练集,共有9937个示例。
创建时间:
2025-06-18
原始信息汇总
数据集概述
基本信息
- 数据集名称: mental_health
- 许可证: MIT
- 下载大小: 2,440,125 字节
- 数据集大小: 6,868,407 字节
数据集结构
- 配置名称: default
- 数据文件:
- 训练集: data/train-*
- 特征:
- Context: 字符串类型
- Response: 字符串类型
- index_level_0: 整数类型 (int64)
- 数据分割:
- 训练集:
- 样本数量: 9,937
- 字节大小: 6,868,407 字节
- 训练集:
搜集汇总
数据集介绍
构建方式
mental_health数据集聚焦于心理健康领域,通过系统化的数据采集流程构建而成。该数据集收录了9937条对话样本,每条样本包含完整的语境(Context)和回应(Response)文本对,并采用标准化的数据清洗流程确保语料质量。数据以训练集(train)单一分割形式存储,原始文本经过匿名化处理并保留对话的连贯性特征,通过唯一索引(__index_level_0__)实现数据可追溯性。
特点
该数据集的核心价值体现在其专业领域覆盖度和结构化特征。所有对话样本均围绕心理健康主题展开,文本长度和复杂度呈现自然分布特征。数据字段设计简洁高效,上下文与回应的配对结构为对话系统研究提供理想素材。6.8MB的轻量级规模兼顾了深度学习模型的训练效率与数据多样性需求,原始文本保留真实对话的语言风格和情感表达。
使用方法
研究者可通过HuggingFace平台直接加载数据集进行端到端应用。典型使用场景包括心理对话系统开发、情感分析模型训练等NLP任务。数据以标准文本对格式组织,支持直接输入Transformer架构模型。建议使用者结合交叉验证技术评估模型性能,注意对话样本中存在的情感敏感内容需遵循伦理研究规范。
背景与挑战
背景概述
随着心理健康问题在全球范围内的日益凸显,mental_health数据集的构建为相关研究提供了宝贵资源。该数据集由匿名研究团队于近年发布,收录了近万条心理对话记录,重点关注个体在心理咨询场景中的语言表达模式。其核心价值在于通过真实的对话样本,为心理健康领域的自然语言处理研究提供了数据基础,对情感计算、危机干预等应用具有重要推动作用。数据集采用MIT开源协议,体现了研究社区对心理健康数据共享的开放态度。
当前挑战
该数据集面临双重挑战:在领域问题层面,心理健康对话具有高度敏感性和语境依赖性,如何准确捕捉并分类复杂的心理状态表达成为关键难题;在构建过程中,匿名化处理与数据保真度之间的平衡、专业术语的标准化标注、以及对话轮次间的逻辑连贯性维护等技术难点尤为突出。这些挑战既反映了心理健康领域的特殊性,也揭示了对话数据集构建的共性技术瓶颈。
常用场景
经典使用场景
在心理健康领域的研究中,mental_health数据集因其包含丰富的对话上下文和回应内容,常被用于训练和评估心理健康相关的自然语言处理模型。研究人员利用该数据集分析人们在心理健康话题中的语言表达模式,从而开发出能够理解和生成相关对话的智能系统。
实际应用
在实际应用中,mental_health数据集被广泛用于开发心理健康聊天机器人和虚拟助手。这些智能系统能够为用户提供即时的心理支持,帮助缓解焦虑和抑郁情绪,同时为心理健康专业人士提供辅助工具,提升诊断和治疗的效率。
衍生相关工作
基于mental_health数据集,许多经典研究工作得以展开,例如心理健康对话生成模型和情绪识别算法的开发。这些工作不仅推动了自然语言处理技术在心理健康领域的应用,还为后续研究提供了重要的参考和基础。
以上内容由遇见数据集搜集并总结生成


