knkarthick/samsum
收藏Hugging Face2022-10-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/knkarthick/samsum
下载链接
链接失效反馈官方服务:
资源简介:
SAMSum数据集包含约16k的类似即时通讯的对话及其摘要。对话由精通英语的语言学家创建,反映了他们日常生活中即时通讯对话的主题比例。对话的风格和语体多样,可能包含俚语、表情符号和拼写错误。每个对话都附有摘要,摘要要求简洁、提取重要信息、包含对话者姓名并以第三人称书写。数据集由三星波兰研发研究所准备,用于研究目的,采用非商业许可CC BY-NC-ND 4.0。
SAMSum dataset contains approximately 16k instant-messaging-like conversations and their corresponding summaries. The conversations were created by English-proficient linguists, and reflect the topic distribution of instant messaging conversations in their daily lives. The conversations feature diverse styles and linguistic registers, and may contain slang, emojis, and spelling mistakes. Each conversation is paired with a summary, which is required to be concise, extract key information, include the names of the speakers, and be written in the third person. This dataset was prepared by the Samsung R&D Institute Poland for research purposes, and is licensed under the non-commercial CC BY-NC-ND 4.0.
提供机构:
knkarthick
原始信息汇总
数据集概述
数据集名称
- 名称: SAMSum Corpus
- 别名: SAMSum
数据集属性
- 语言: 英语
- 多语言性: 单语种
- 许可证: CC BY-NC-ND 4.0(非商业用途)
- 大小: 10K<n<100K
- 源数据集: 原创数据
- 任务类别: 摘要生成
- 标签: 对话摘要
数据集内容
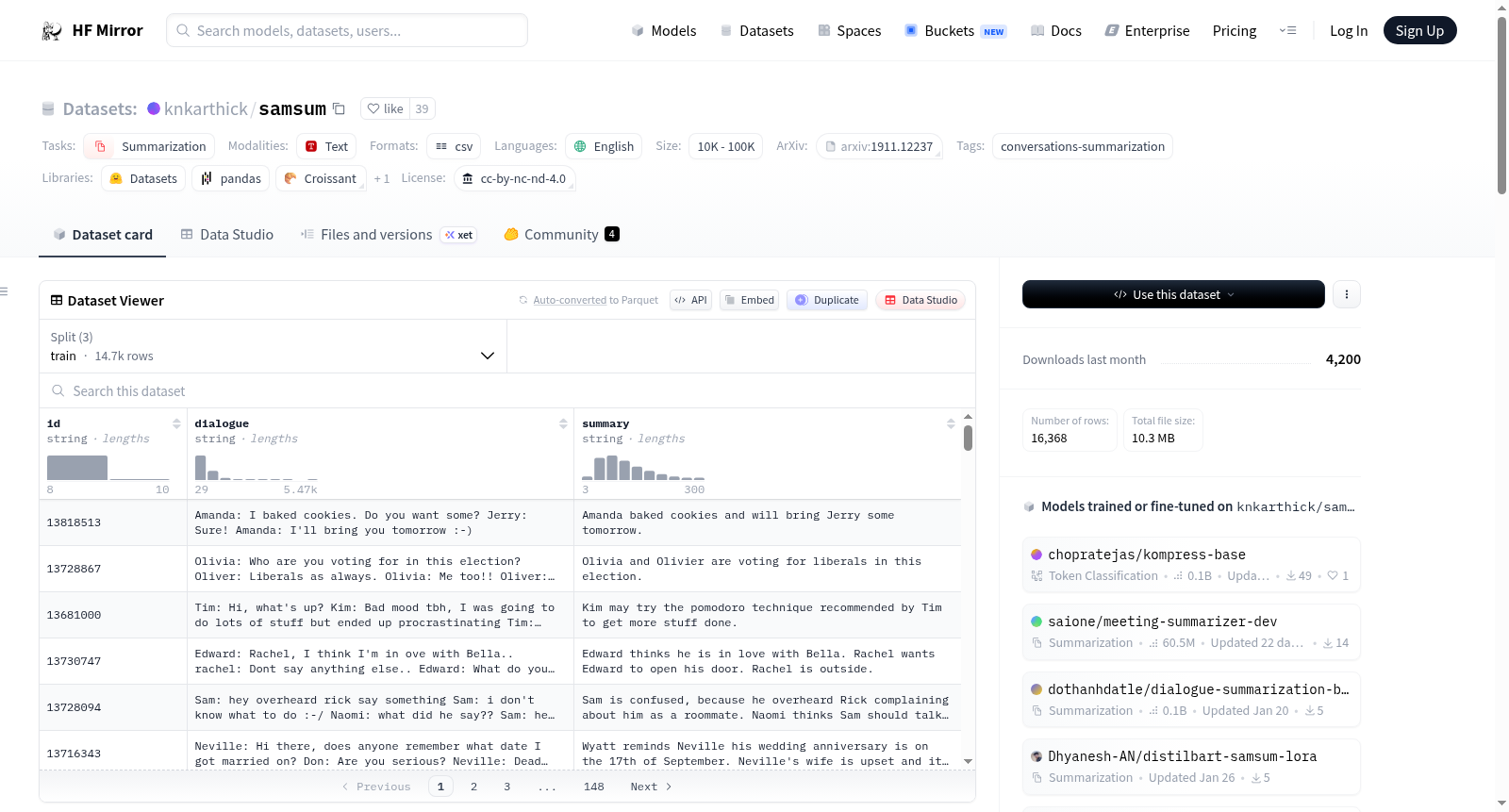
- 描述: SAMSum 数据集包含约16,000个类似即时通讯的对话及其摘要。这些对话由精通英语的语言学家创建和编写,旨在反映日常即时通讯对话的主题比例。对话风格多样,包括非正式、半正式或正式,可能包含俚语、表情符号和拼写错误。每个对话均附有人工编写的摘要,概述对话内容。
- 结构: 数据集包含16,369个对话,均匀分布在四个组中,根据对话中的话语数量划分。大多数对话涉及两个对话者。
- 数据字段:
- 对话: 对话文本
- 摘要: 对话的人工编写摘要
- ID: 示例的唯一文件ID
- 数据分割:
- 训练集: 14,732
- 验证集: 818
- 测试集: 819
数据集创建
- 来源语言生产者: 语言学家
- 注释者: 语言专家
- 注释过程: 每个对话由一名语言专家创建,随后由语言专家进行摘要注释,确保摘要简短、提取重要信息、包含对话者姓名并以第三人称编写。
许可证信息
- 许可证: CC BY-NC-ND 4.0(非商业用途)
引用信息
@inproceedings{gliwa-etal-2019-samsum, title = "{SAMS}um Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization", author = "Gliwa, Bogdan and Mochol, Iwona and Biesek, Maciej and Wawer, Aleksander", booktitle = "Proceedings of the 2nd Workshop on New Frontiers in Summarization", month = nov, year = "2019", address = "Hong Kong, China", publisher = "Association for Computational Linguistics", url = "https://www.aclweb.org/anthology/D19-5409", doi = "10.18653/v1/D19-5409", pages = "70--79" }
搜集汇总
数据集介绍
构建方式
在对话摘要研究领域,现有数据集常因对话风格、长度或语境不匹配而受限。SAMSum数据集的构建旨在弥补这一空白,其核心方法是由精通英语的语言学家人工创作模拟日常即时通讯风格的对话。这些对话涵盖了从非正式到正式的多样语体,并可能包含俚语、表情符号及拼写错误,以真实反映现实交流的复杂性。随后,语言专家为每段对话标注了简洁的第三人称摘要,确保摘要能准确提取关键信息并提及对话者姓名,最终形成了包含约1.6万对话-摘要对的高质量语料库。
使用方法
该数据集主要应用于抽象式对话摘要任务的研究与模型评估。使用者可依据标准划分的训练、验证和测试集进行模型训练与性能验证,其中训练集包含14732个样本,验证集和测试集各约800余样本。每个数据实例包含对话文本、人工撰写的摘要及唯一标识符,便于直接用于序列到序列的摘要生成。研究人员可基于此评估模型在提取关键信息、保持语义连贯及适应多样对话风格方面的能力,推动自然语言处理技术在现实通讯场景中的应用发展。
背景与挑战
背景概述
在自然语言处理领域,对话摘要任务旨在从非结构化的对话文本中提取核心信息,生成简洁的概要。SAMSum Corpus由三星波兰研发院于2019年创建,其核心研究问题聚焦于解决即时通讯风格对话的抽象摘要生成。该数据集包含约1.6万条由语言学家精心构建的模拟日常聊天对话及对应的人工标注摘要,涵盖了从非正式到正式的多重语域,并融入俚语、表情符号等真实元素。SAMSum的推出填补了当时对话摘要数据集中缺乏典型即时通讯风格语料的空白,为相关模型训练与评估提供了重要基准,显著推动了对话摘要技术向更贴近实际应用场景的方向发展。
当前挑战
SAMSum Corpus所针对的对话摘要领域面临多重挑战:其一,即时通讯对话常具有高度非结构化、口语化及多轮交互特性,要求模型能有效捕捉对话中的关键信息与上下文逻辑关联;其二,摘要需在保留核心意图的同时,以第三人称进行凝练重组,这对模型的语义理解与生成能力提出了较高要求。在数据集构建过程中,挑战主要源于现有语料与目标风格的差异:早期可用数据如IRC聊天记录过于技术化,电影对话缺乏上下文,会议转录则篇幅冗长,均难以反映日常通讯的典型特征。因此,研究团队不得不通过语言学家人工构建对话,并依据严格准则进行摘要标注,以确保数据质量与任务代表性。
常用场景
经典使用场景
在自然语言处理领域,对话摘要任务旨在从非结构化对话中提取关键信息,生成简洁的概括。SAMSum数据集作为专门针对即时通讯风格对话的摘要资源,其经典使用场景在于训练和评估抽象式摘要模型。该数据集通过模拟真实世界中的聊天对话,涵盖了从日常琐事到正式讨论的多样化主题,为研究者提供了贴近实际应用的数据基础,使得模型能够学习如何捕捉对话中的核心意图和细节,从而生成流畅、准确的摘要。
解决学术问题
SAMSum数据集解决了对话摘要研究中长期存在的数据稀缺问题,特别是针对非正式、多轮次对话的抽象式摘要。传统数据集往往基于会议记录或电影台词,缺乏即时通讯的典型特征,如口语化表达、表情符号和拼写错误。该数据集通过专家构建的对话和摘要,为学术研究提供了高质量基准,促进了模型在理解上下文、处理噪声和生成连贯摘要方面的进展,对推动自然语言生成和对话系统的发展具有深远意义。
实际应用
在实际应用中,SAMSum数据集支持了智能助手和客服系统的开发,这些系统需要快速理解用户对话并生成摘要以提升效率。例如,在客户服务场景中,模型可以自动总结用户与客服的聊天记录,帮助后续处理人员快速掌握问题核心;在个人助理应用中,它能够从日常聊天中提取重要事项,如约会安排或任务提醒。这些应用不仅提高了人机交互的智能化水平,还优化了信息处理流程,展现了对话摘要技术在现实世界中的广泛价值。
数据集最近研究
最新研究方向
在对话摘要领域,SAMSum数据集作为专家构建的即时通讯风格对话语料库,已成为推动抽象式摘要技术发展的关键资源。当前研究聚焦于利用预训练语言模型,如BART和T5,通过微调策略提升模型在复杂多轮对话中的信息压缩与连贯性生成能力。前沿探索涉及跨领域迁移学习,旨在将模型泛化至客服对话、会议记录等实际场景,同时结合强化学习优化摘要的忠实度与可读性。随着多模态交互的兴起,该数据集亦被扩展用于研究图文混合对话的摘要生成,呼应了人机交互智能化趋势。这些进展不仅深化了自然语言处理的理论基础,更为智能助理、内容审核等应用提供了技术支撑,彰显其在信息高效处理中的核心价值。
以上内容由遇见数据集搜集并总结生成


