gaodrew/roman_empire_qa_27k
收藏Hugging Face2023-10-10 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/gaodrew/roman_empire_qa_27k
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
---
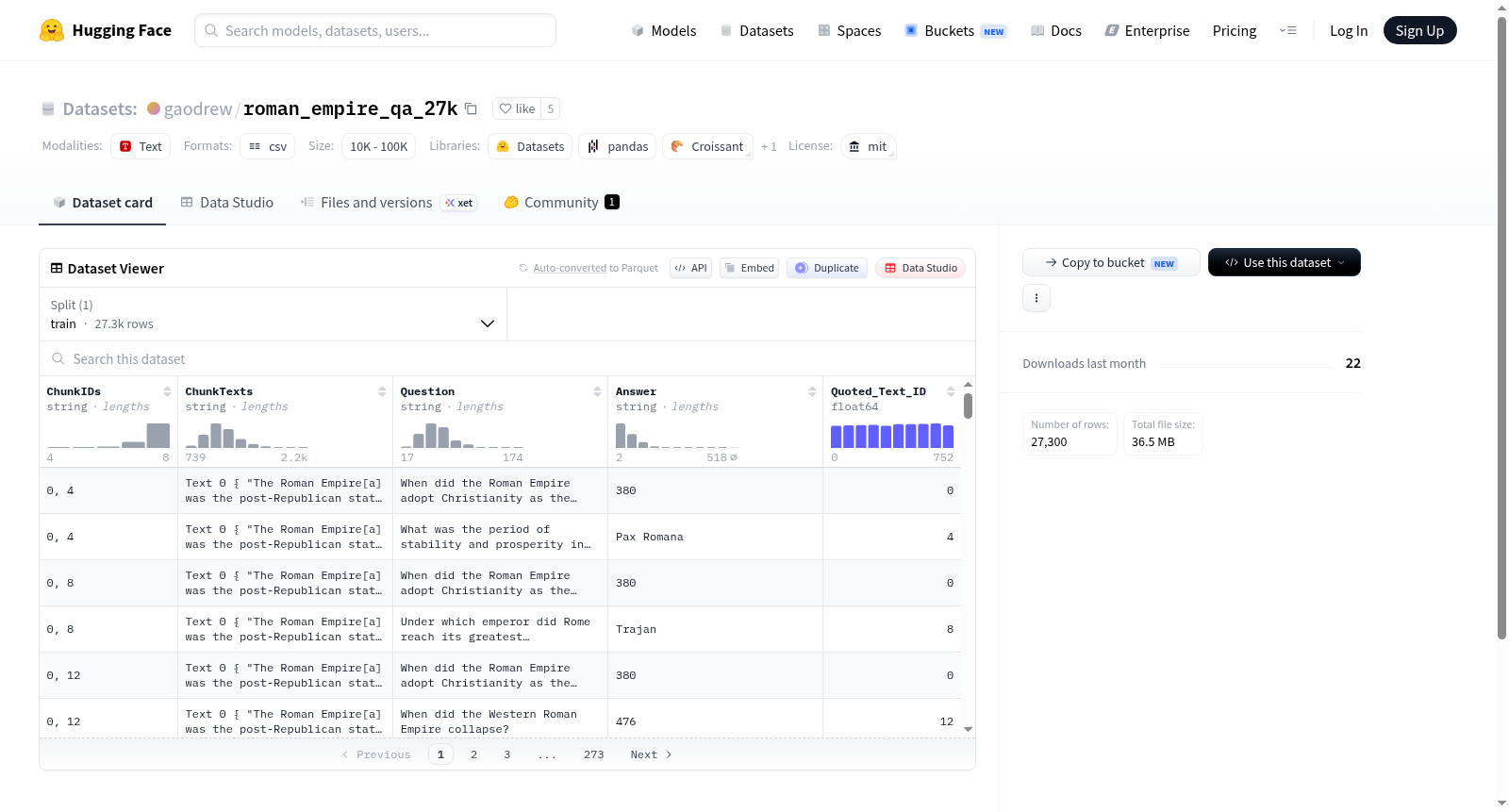
roman_empire_qa_27k is a prompt-completion pairs dataset of 27,300 questions and answers about the Roman Empire.
Also provided are context snippets from which the questions and answers were generated (by GPT-3.5-turbo).
提供机构:
gaodrew
原始信息汇总
罗马帝国问答数据集
概述
- 名称: roman_empire_qa_27k
- 类型: 问答对数据集
- 数量: 包含27,300个问题和答案对
- 内容: 关于罗马帝国的问答
- 来源: 问题和答案由GPT-3.5-turbo生成,并提供相关上下文片段
- 许可证: MIT许可证
搜集汇总
数据集介绍
构建方式
罗马帝国作为古典文明的巅峰,其政治、军事与文化体系始终是历史研究的核心议题。该数据集基于这一宏阔背景,通过调用GPT-3.5-turbo模型,从预选的历史文献片段中自动生成问答对,构建了涵盖帝国兴衰、制度沿革与人物事件的系统性知识库。每个问题与答案均附有对应的上下文片段,确保生成内容的可追溯性与语义连贯性,最终形成27,300条提示-完成配对。
使用方法
该数据集适用于监督式微调或零样本评估,可直接作为提示-完成格式的输入加载至大语言模型训练流程。使用时,建议将上下文片段作为额外输入特征,以增强模型对历史语境的理解能力。数据以标准JSON格式存储,兼容主流框架(如HuggingFace Transformers),无需额外预处理即可用于构建罗马帝国领域的专业问答系统或历史知识增强应用。
背景与挑战
背景概述
罗马帝国作为古代世界最为庞大的政治实体之一,其历史研究长期依赖于古典文献与考古发现,然而传统研究方法在知识整合与规模化问答方面存在瓶颈。gaodrew/roman_empire_qa_27k数据集由研究人员于近期创建,旨在通过27,300个问答对系统覆盖罗马帝国的政治、军事、社会与文化等多维度知识。该数据集依托GPT-3.5-turbo从特定上下文片段中自动生成问答,为历史学与自然语言处理的交叉研究提供了结构化资源。其发布推动了古典知识库的数字化进程,尤其适用于智能问答系统与教育辅助工具的研发,在历史信息检索领域具有开创性意义。
当前挑战
当前数据集面临的核心挑战包括:其一,历史领域问答的精确性难以保证,自动生成的答案可能因模型对模糊史实的泛化而产生偏差,例如对罗马帝国不同时期的政策解读存在歧义;其二,构建过程中依赖的GPT-3.5-turbo模型受限于训练数据的时间范围,无法覆盖最新考古发现或争议性历史观点,导致知识时效性不足;其三,上下文片段的选择标准缺乏透明性,可能遗漏关键历史细节,影响问答对的完整性和逻辑连贯性。此外,数据集规模虽大但主题分布不均,例如军事类问题占比过高而经济制度类偏少,这限制了其在均衡历史研究中的应用潜力。
常用场景
经典使用场景
在历史自然语言处理与知识图谱构建的交叉领域中,gaodrew/roman_empire_qa_27k数据集以其精细化的问答对结构,成为研究古代文明信息检索与推理的经典基准。该数据集涵盖罗马帝国从政治制度、军事征战到社会文化等多维度议题,为训练和评估模型在特定历史语料上的事实性问答能力提供了标准化测试床。研究者常借助其上下文片段设计封闭域问答任务,以验证模型对复杂历史叙事的理解深度与信息抽取精度。
解决学术问题
该数据集有效解决了历史领域知识问答中标注数据稀缺与领域特异性难题,为学术研究提供了首个大规模、高质量的古罗马主题问答资源。通过标准化的问题-答案-上下文三元组,它推动了事实性问答系统在长尾历史实体上的鲁棒性评估,并支撑了上下文增强生成技术(如RAG)在历史文本中的有效性验证。其意义在于填补了古典学与人工智能交叉研究的资源空白,促使模型从粗粒度知识记忆转向细粒度历史逻辑推理。
实际应用
在实际应用中,该数据集可赋能数字人文平台中的智能问答模块,例如为博物馆导览系统或历史教学助手提供精准的罗马帝国知识应答能力。通过微调语言模型,开发者能够构建面向公众的交互式历史查询工具,自动解析用户关于罗马皇帝、战役或法律制度的提问。此外,其上下文片段还可用于辅助古籍文献的自动注释与跨文本关联检索,提升文化遗产数字化过程中信息组织的效率。
数据集最近研究
最新研究方向
在历史学与自然语言处理的交叉领域,古罗马帝国作为西方文明的基石,其知识体系的数字化与智能化问答成为前沿热点。gaodrew/roman_empire_qa_27k数据集通过GPT-3.5-turbo自动生成2.73万条基于上下文片段的问题-答案对,为构建古罗马专题的智能问答系统提供了大规模、高质量的训练资源。该数据集不仅服务于历史教育中的自动答疑与知识检索,还推动了领域大模型在古典学知识图谱构建、历史事件因果推理等方向的研究。其生成方式体现了大语言模型在垂直领域数据增强中的潜力,为其他文明史料的数字化研究提供了可复现的方法论范式,具有重要的学术价值与应用前景。
以上内容由遇见数据集搜集并总结生成


