jordyvl/DUDE_loader
收藏Hugging Face2023-10-03 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/jordyvl/DUDE_loader
下载链接
链接失效反馈官方服务:
资源简介:
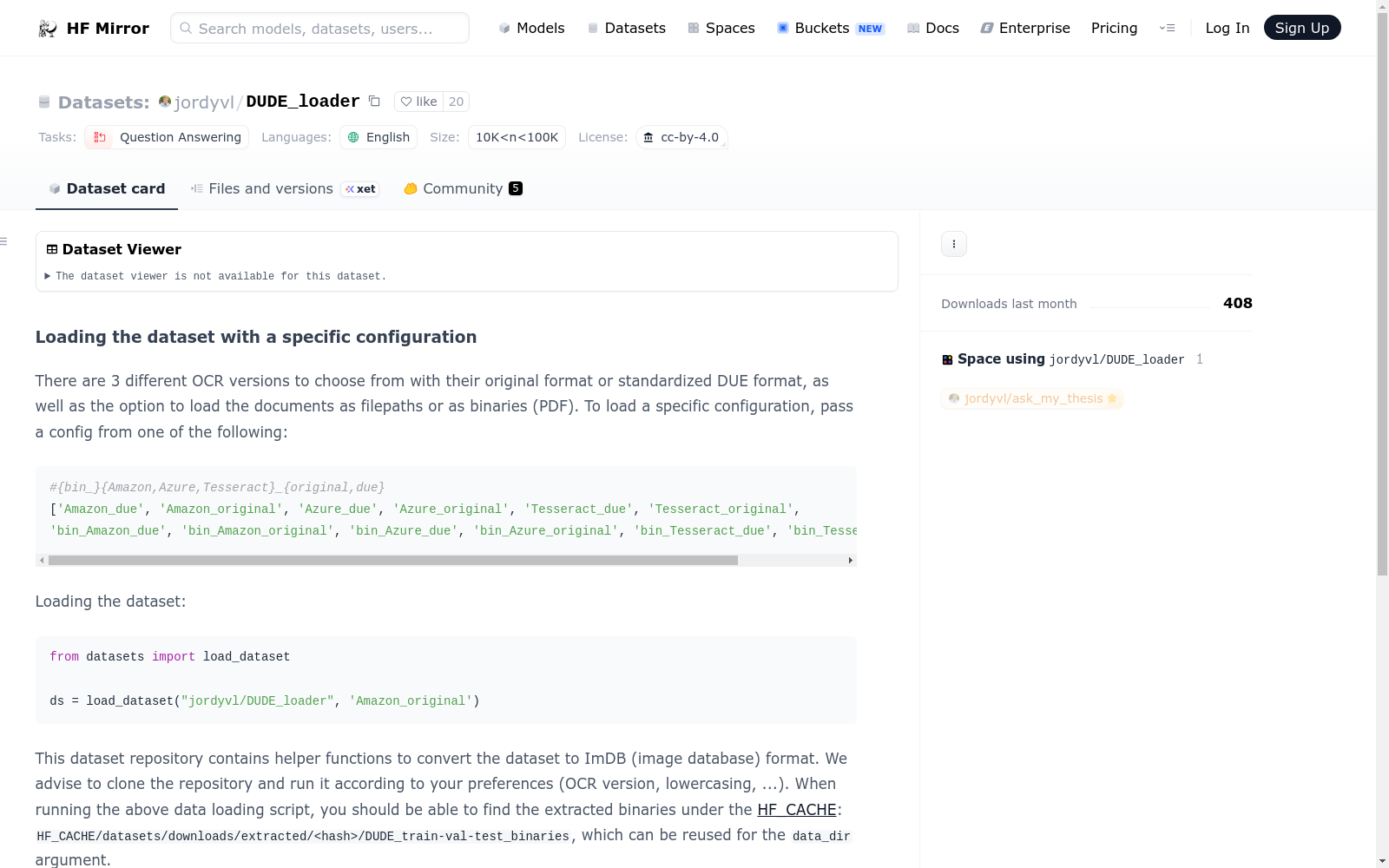
DUDE数据集是一个用于问答任务的英文数据集,包含多种OCR版本和格式选项。数据集支持以文件路径或二进制(PDF)形式加载,并提供了将数据集转换为ImDB格式的辅助功能。用户可以选择不同的OCR版本(如Amazon、Azure、Tesseract)及其原始格式或标准化的DUE格式。此外,README还提供了加载数据集的示例代码、缓存路径的使用说明以及如何提交测试集预测到DUDE竞赛排行榜的指南。
The DUDE dataset is an English-language dataset designed for question answering tasks, offering multiple OCR versions and format options. It supports loading via either file paths or binary (PDF) data, and provides auxiliary utilities for converting the dataset into the ImDB format. Users can choose from various OCR engines including Amazon, Azure, and Tesseract, alongside either their native original formats or the standardized DUE format. Additionally, the README includes sample code for loading the dataset, usage instructions for cache paths, and guidelines on submitting test set predictions to the DUDE competition leaderboard.
提供机构:
jordyvl
原始信息汇总
数据集概述
基本信息
- 许可证: CC-BY-4.0
- 任务类别: 问答
- 语言: 英语
- 数据集名称: DUDE
- 数据集大小: 10K<n<100K
数据加载
- 支持三种不同的OCR版本:Amazon, Azure, Tesseract,每种版本都有原始格式和标准化DUE格式。
- 数据可以作为文件路径或二进制(PDF)加载。
- 加载配置示例: python from datasets import load_dataset ds = load_dataset("jordyvl/DUDE_loader", Amazon_original)
数据转换
- 提供辅助函数将数据集转换为ImDB格式。
- 建议克隆仓库并根据个人偏好(OCR版本、小写化等)运行。
数据存储
- 提取的二进制文件存储路径示例: bash ~/.cache/huggingface/datasets/downloads/extracted/7adde0ed7b0150b7f6b32e52bcad452991fde0f3407c8a87e74b1cb475edaa5b/DUDE_train-val-test_binaries/
基准测试
- 推荐参考MP-DocVQA仓库进行基准测试。
提交测试集预测
- 鼓励在DUDE竞赛排行榜上提交测试集预测。
- 提供样本提交文件
RRC_DUDE_testset_submission_example.json以帮助提交预测。
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集名为DUDE_loader,主要用于英语问答任务,数据规模中等(10K<n<100K),提供多种OCR版本和格式选择,需安装pdf2image依赖。数据集支持转换为ImDB格式,并鼓励用户参与竞赛排行榜。
以上内容由遇见数据集搜集并总结生成


