eval-whisper-large-v3-turbo-multimed-hard-20260408-1931
收藏Hugging Face2026-04-09 更新2026-04-10 收录
下载链接:
https://huggingface.co/datasets/Trelis/eval-whisper-large-v3-turbo-multimed-hard-20260408-1931
下载链接
链接失效反馈官方服务:
资源简介:
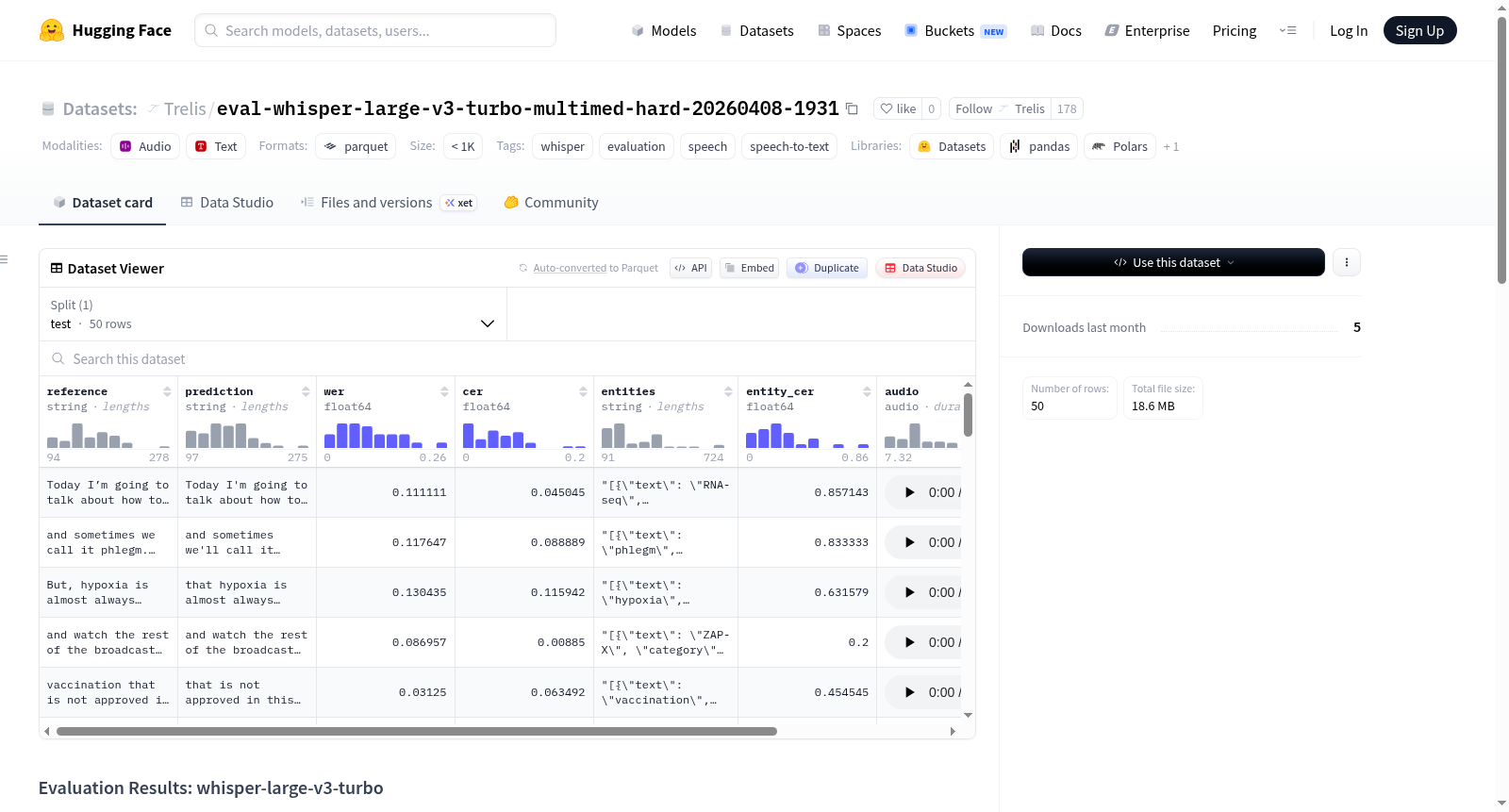
该数据集包含对Whisper模型'whisper-large-v3-turbo'在'Trelis/multimed-hard'数据集上的评估结果。评估指标包括词错误率(WER)和字符错误率(CER),以及针对不同实体类别的详细CER分析。数据集列包括音频样本(如果源数据集提供)、参考转录文本、模型预测文本、样本级别的WER和CER值,以及实体标注和实体CER。实体CER分为多个类别,如解剖学、生物标志物、条件、药物、组织和手术等。该数据集适用于语音识别模型的性能评估和错误分析任务。
提供机构:
Trelis
创建时间:
2026-04-09
搜集汇总
数据集介绍
构建方式
在语音识别模型的性能评估领域,eval-whisper-large-v3-turbo-multimed-hard-20260408-1931数据集作为专项评估结果集,其构建源于对特定模型在选定基准上的系统化测试。该数据集并非通过传统的原始数据采集与标注流程生成,而是通过将开源模型openai/whisper-large-v3-turbo在公开的医学语音识别挑战数据集Trelis/multimed-hard上进行推理,并逐条计算其转录结果与标准参考答案之间的误差指标而形成。其核心构建逻辑在于自动化地执行模型推理、文本比对与误差统计,最终将每条样本的音频引用、参考答案、模型预测、词错误率、字错误率以及细粒度的实体识别错误率进行结构化整合,从而生成了一个可直接用于模型性能分析的评估结果集合。
特点
该数据集的核心特征在于其高度结构化与细粒度的评估维度。它不仅提供了模型在整体语料上的词错误率与字错误率宏观指标,更深入至样本级别,为每一条测试样本记录了独立的误差分数。尤为突出的是,数据集引入了实体级别的错误率分析,针对医学领域常见的解剖结构、生物标志物、疾病状况、药物、组织机构及医疗程序等六类实体,分别统计了其字符错误率,揭示了模型在不同专业术语类别上的识别性能差异。这种从整体到样本、从通用文本到专业实体的多层次评估框架,为深入理解语音识别模型在复杂专业场景下的能力边界提供了精准的量化视角。
使用方法
该数据集的主要用途在于为研究人员提供关于whisper-large-v3-turbo模型在医学语音转录任务上性能的即用型分析基准。使用者可直接加载该数据集,通过其预计算的WER、CER及实体CER等字段,进行快速的模型性能横向对比或纵向分析,无需重复运行耗时的模型推理过程。具体而言,研究者可以分析不同实体类别的错误率分布,以识别模型在特定医学术语上的薄弱环节;也可以考察样本级别的错误情况,用于错误案例分析或模型失败模式的归纳。该数据集作为一个静态的性能快照,为模型评估、报告撰写及后续研究方向的确立提供了可靠的数据支撑。
背景与挑战
背景概述
随着自动语音识别技术的快速发展,特别是在医疗等专业领域,对模型性能的精准评估变得至关重要。eval-whisper-large-v3-turbo-multimed-hard-20260408-1931数据集由Trelis机构于2024年构建,旨在系统评估Whisper-large-v3-turbo模型在复杂多媒体医疗语音数据上的转录准确性。该数据集依托开源评估框架,聚焦于模型在真实医疗场景中的实体识别能力,如解剖结构、生物标志物等专业术语的转录效果,为语音识别技术在专业领域的应用提供了关键的性能基准。
当前挑战
该数据集所针对的核心挑战在于提升自动语音识别系统在专业领域,尤其是医疗语境下的鲁棒性与准确性。医疗语音通常包含大量专业术语、缩写及复杂实体名称,模型容易在实体转录上出现较高错误率,如数据中显示整体实体字符错误率达21.80%,其中“组织”类实体错误率更高达28.71%。在构建过程中,挑战主要源于如何有效标注多模态医疗数据中的实体边界与类别,并确保评估指标(如CER、WER)能够精准反映模型在细粒度医疗术语上的性能差异,同时保持评估过程的可复现性与标准化。
常用场景
经典使用场景
在自动语音识别领域,该数据集专为评估模型在复杂多模态医疗环境下的转录性能而设计。其核心应用场景在于对Whisper系列大型模型进行系统性评测,通过对比预测文本与真实标注,计算词错误率和字符错误率,从而量化模型在专业医疗术语识别上的准确性。这一过程为研究者提供了模型在嘈杂或专业语境中鲁棒性的直观洞察,是优化语音识别技术的关键环节。
衍生相关工作
围绕该数据集,衍生出多项聚焦于医疗语音识别的经典研究工作。例如,基于实体错误分析,研究者开发了针对药物名称或解剖术语的增强训练策略;同时,它也被用于对比不同Whisper变体在跨语言医疗数据上的表现,催生了领域自适应方法的发展。这些工作进一步拓展了多模态硬样本评估框架,推动了语音识别在专业垂直领域的标准化评测体系形成。
数据集最近研究
最新研究方向
在语音识别领域,针对医学专业场景的模型性能评估正成为前沿焦点。基于Whisper-large-v3-turbo模型在multimed-hard数据集上的评测结果揭示了其在处理复杂医学术语时的挑战,整体实体字符错误率高达21.80%,尤其在解剖学和组织机构类别上表现显著不足。这一发现推动了研究向领域自适应和细粒度错误分析深入,旨在通过实体级别的性能剖析优化模型在专业场景的鲁棒性。当前热点集中于利用此类评估数据改进端到端语音识别系统对专业术语的捕捉能力,其进展对临床语音应用和自动化病历转录具有重要实践意义。
以上内容由遇见数据集搜集并总结生成


