广告视频数据集
收藏arXiv2025-04-08 更新2025-04-10 收录
下载链接:
http://arxiv.org/abs/2504.05673v1
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由字节跳动公司创建,包含157万条广告视频内容,对应38.9万个独特产品。数据集通过自动语音识别模型提取视频中的口播脚本和对应时间戳,并进行视频分段。经过筛选和人工标注,最终保留了23万个高质量视频。数据集分为预训练集和微调集,用于训练和评估自动生成广告视频的系统。数据集广泛应用于服装配饰、食品饮料和建筑材料等行业的广告制作。
This dataset was created by ByteDance. It contains 1.57 million advertising video clips corresponding to 389,000 unique products. The spoken commentary scripts and their corresponding timestamps are extracted from the videos via automatic speech recognition (ASR) models, and video segmentation is performed. After screening and manual annotation, 230,000 high-quality video clips are finally retained. The dataset is divided into a pre-training set and a fine-tuning set, which are used for training and evaluating automatic advertising video generation systems. This dataset is widely applied in advertising production across industries such as apparel and accessories, food and beverage, and building materials.
提供机构:
字节跳动
创建时间:
2025-04-08
搜集汇总
数据集介绍
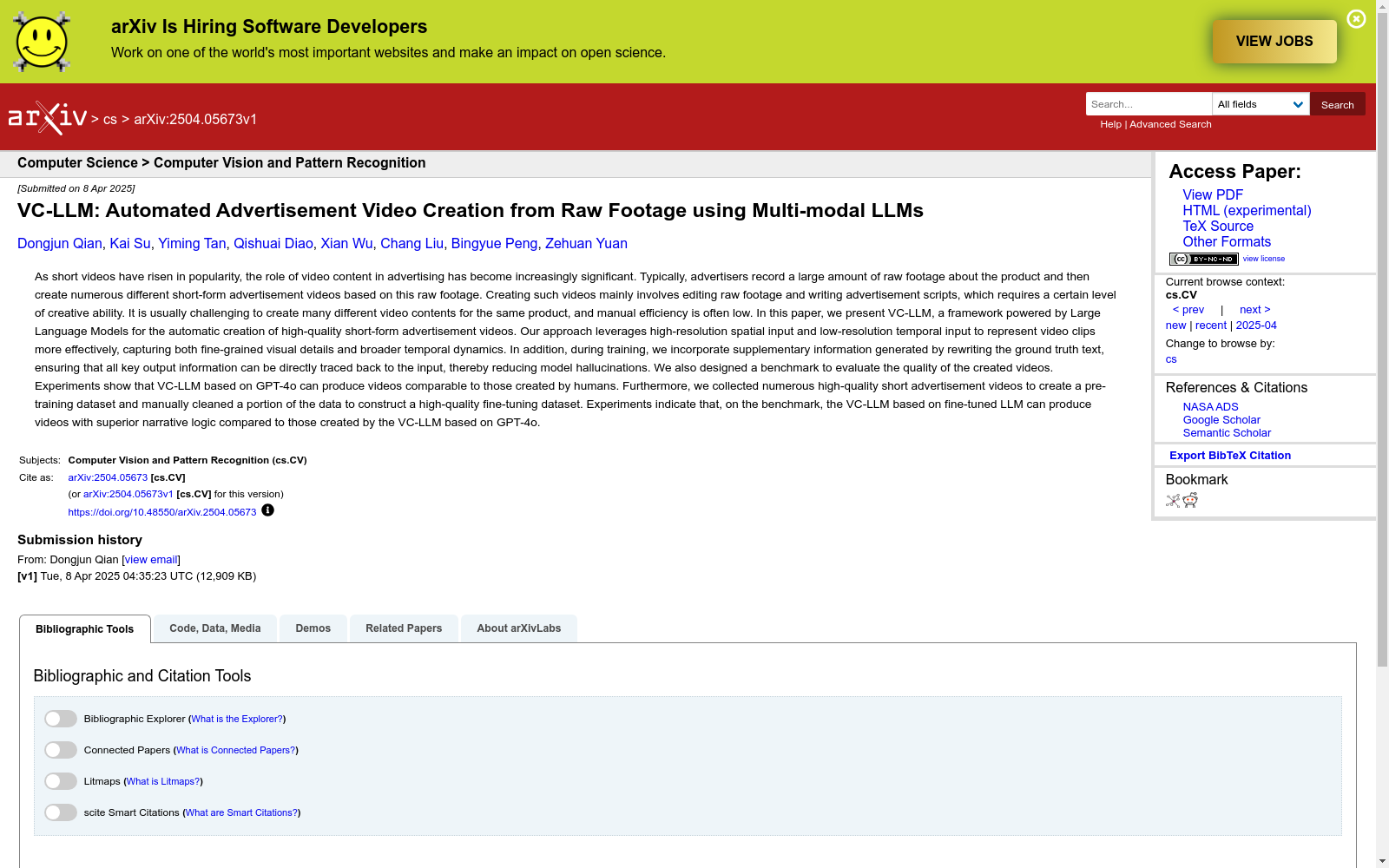
构建方式
广告视频数据集的构建过程分为四个关键阶段:数据筛选、解析、处理与分割。研究团队从国内平台收集了389,000种商品的157万条广告视频,通过自动语音识别(ASR)模型提取口语脚本及时间戳,辅以视觉特征差异分析进行视频分段。经过GPT-4o辅助的质量过滤(包括时长、片段数量、语义相关性等指标)和人工标注精修,最终形成包含23万条高质量视频的训练集,其中10万条用于持续预训练,1万条用于监督微调,并保留5,000种独立商品视频作为测试基准。
特点
该数据集具有显著的多模态特性与工业应用价值:视频时长集中在15-30秒,每个视频包含2-8个片段,中文字符数80-140字,完美契合短视频广告的传播规律。其独特之处在于采用双分辨率编码策略——高分辨率空间输入捕捉产品细节(996×560像素),低分辨率时序输入(560×315像素)表征动作连贯性。数据集覆盖服装配饰、食品饮料、家装建材等主要商品类别,并通过重写真实脚本作为补充输入信息,有效缓解模型幻觉问题。测试集特别包含无口语脚本的随机视频片段,增强了评估场景的多样性。
使用方法
该数据集支持四种渐进式任务:视频片段重组、脚本预测、字幕分割的单项训练,以及三模态结合的复合任务。使用时需将产品信息(名称、卖点)与无序视频片段输入VC-LLM框架,模型将输出排序后的视频序列、对应脚本及分段字幕。评估阶段采用六项指标:片段排序准确率(SRA)衡量叙事逻辑,视觉脚本相关性(VSC)和事实性(Fact)通过GPT-4o评分,字幕分割准确率(SSA)则基于字符数限制和中文分词校验。实验表明,基于该数据集微调的模型在叙事逻辑(SRA提升291%)和脚本长度控制(WCD降低84%)方面显著优于GPT-4o基础版本。
背景与挑战
背景概述
广告视频数据集由字节跳动公司的研究人员于2025年创建,旨在解决短视频广告内容创作中的自动化问题。随着短视频平台的兴起,广告商需要从大量原始素材中高效制作多样化的广告视频,这一过程传统上依赖人工剪辑和脚本创作,效率低下且成本高昂。该数据集通过整合多模态大语言模型(如GPT-4o)和高质量广告视频样本,为自动化视频生成提供了研究基础,显著提升了广告内容的生产效率和质量,对数字营销和多媒体内容生成领域具有重要影响。
当前挑战
广告视频数据集面临的主要挑战包括:1) 领域问题的挑战:自动化生成的视频需在视觉与脚本的语义对齐、叙事逻辑和事实一致性上达到人工水平,同时需适应多样化的产品类型和广告风格;2) 构建过程的挑战:原始素材的多样性和质量不均增加了数据清洗和标注的难度,且多模态数据的融合(如高分辨率空间输入与低分辨率时间输入的协同)对模型架构设计提出了更高要求。此外,减少模型幻觉(即生成与输入无关的内容)也是数据集构建中的关键难点。
常用场景
经典使用场景
广告视频数据集在自动化广告创作领域具有广泛的应用,特别是在短广告视频的生成和优化方面。该数据集通过整合大量原始视频片段和高质量广告脚本,为多模态大语言模型(如VC-LLM)提供了丰富的训练素材。其经典使用场景包括自动生成符合产品特性的广告脚本、智能剪辑视频片段以增强视觉吸引力,以及优化字幕分割以提升用户体验。这些功能显著降低了广告制作的创意门槛和时间成本。
实际应用
在实际应用中,广告视频数据集被广泛用于电商平台、社交媒体和数字营销领域。例如,广告商可以利用该数据集快速生成多个针对不同目标受众的广告变体,从而优化广告投放效果。数据集还支持自动化字幕生成和视频剪辑,显著提升了广告制作的效率和质量。实验表明,基于该数据集训练的模型(如VC-LLM)生成的广告视频在视觉-脚本对齐和叙事逻辑上优于人工创作的内容。
衍生相关工作
该数据集衍生了一系列经典研究工作,包括多模态大语言模型(如InternLM-XComposer系列)在广告创作中的应用、视频片段与脚本的语义对齐算法,以及基于GPT-4o的自动化广告生成框架。这些工作进一步推动了多模态内容生成领域的发展,并为个性化广告的大规模生产提供了技术基础。此外,数据集还启发了对模型幻觉抑制和事实性增强的研究,为其他领域的多模态任务提供了借鉴。
以上内容由遇见数据集搜集并总结生成


