In-Context Learning Embedding and Reranker Benchmark (ICLERB)
收藏arXiv2024-11-28 更新2024-12-03 收录
下载链接:
https://huggingface.co/spaces/crossingminds/iclerb
下载链接
链接失效反馈官方服务:
资源简介:
In-Context Learning Embedding and Reranker Benchmark (ICLERB) 是由Crossing Minds, Inc创建的一个评估框架,旨在比较不同检索器在增强大型语言模型(LLM)在上下文学习(ICL)任务中的准确性。数据集通过多个数据集和LLM模型评估现有嵌入模型和重排序器的性能。ICLERB的创建过程涉及使用强化学习从AI反馈(RLRAIF)算法微调检索模型,以优化ICL任务中的文档检索。该数据集主要应用于改进LLM在特定任务中的表现,特别是在需要动态检索相关文档以增强模型输出的场景中。
In-Context Learning Embedding and Reranker Benchmark (ICLERB) is an evaluation framework created by Crossing Minds, Inc. It aims to compare the performance of different retrievers in enhancing the accuracy of Large Language Models (LLMs) on in-context learning (ICL) tasks. The benchmark evaluates existing embedding models and rerankers across multiple datasets and LLM models. The development of ICLERB involves fine-tuning retrieval models using the Reinforcement Learning from AI Feedback (RLRAIF) algorithm to optimize document retrieval for ICL tasks. This framework is primarily used to improve the performance of LLMs in specific scenarios, especially those requiring dynamic retrieval of relevant documents to augment model outputs.
提供机构:
Crossing Minds, Inc
创建时间:
2024-11-28
搜集汇总
数据集介绍
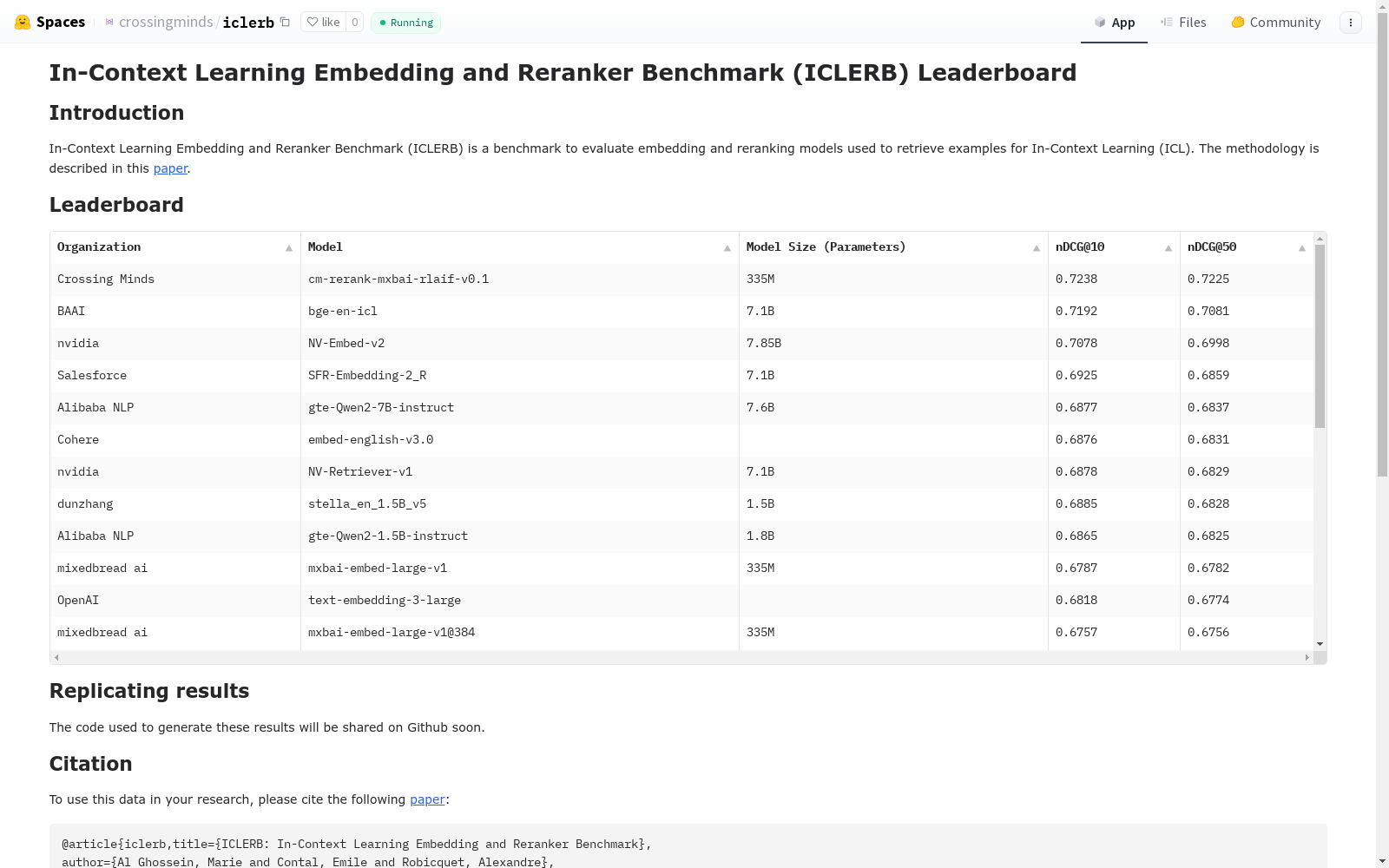
构建方式
ICLERB数据集的构建方式独特,它将传统的检索任务重新定义为推荐问题,旨在选择那些能够最大化上下文学习(ICL)任务效用的文档。数据集通过利用直接偏好优化(DPO)指标来评估检索模型,该指标量化了文档在增强大型语言模型(LLM)性能方面的效用。ICLERB通过跨多个数据集和LLM的交叉验证结果来聚合排名指标,确保评估的全面性和准确性。
特点
ICLERB数据集的主要特点在于其专注于评估检索模型在上下文学习任务中的效用,而非传统的语义相关性。它通过DPO指标来衡量检索文档对LLM性能的提升,从而提供了一种更为精确和相关的评估方法。此外,ICLERB还考虑了LLM的多样性,通过在多个LLM上重复交叉验证方案来确保结果的鲁棒性。
使用方法
使用ICLERB数据集时,研究者可以通过其提供的评估框架来测试和比较不同的嵌入模型和重排序器在上下文学习任务中的表现。数据集提供了详细的评估指标和方法,包括基于DPO的奖励计算和归一化折现累积增益(nDCG)等排名质量指标。研究者可以利用这些工具来优化和验证其检索模型,确保其在实际应用中能够有效提升LLM的性能。
背景与挑战
背景概述
In-Context Learning Embedding and Reranker Benchmark (ICLERB) 是由Crossing Minds, Inc的研究人员Marie Al Ghossein、Emile Contal和Alexandre Robicquet于2024年创建的。该数据集专注于评估大型语言模型(LLMs)在上下文学习(ICL)中的表现,特别是通过检索增强生成(RAG)方法。ICLERB的核心研究问题是如何选择能够最大化ICL任务效用的文档,从而重新定义检索问题为推荐问题。这一研究对自然语言处理领域具有重要影响,因为它提供了一种新的评估框架,能够更准确地衡量检索模型在增强LLM性能方面的能力。
当前挑战
ICLERB在构建过程中面临的主要挑战包括:1) 如何生成一个能够反映文档在提升LLM性能中效用的检索数据集,这一过程计算成本高昂;2) 由于查询-文档对的数量呈二次方增长,评估所有可能的查询-文档对是不可行的;3) 传统的无监督评分方法可能无法与ICL的目标对齐。此外,现有的评估方法主要关注语义相关性,而非文档在特定任务中的效用,这需要新的基准和评估方法。RLRAIF算法的引入旨在通过最小化的LLM反馈来微调检索模型,以解决这些挑战。
常用场景
经典使用场景
ICLERB数据集的经典使用场景在于评估和优化大型语言模型(LLMs)在情境学习(ICL)中的表现。通过提供一个包含查询、文档和响应的基准框架,ICLERB允许研究者测试和比较不同的检索模型,以确定它们在增强LLMs在ICL任务中的准确性方面的能力。这种评估方法超越了传统的语义相关性评估,专注于检索文档在实际任务中的效用,从而为开发更高效的ICL增强模型提供了宝贵的见解。
解决学术问题
ICLERB数据集解决了在情境学习(ICL)中检索增强生成(RAG)模型的评估难题。传统检索方法侧重于语义相关性,而ICLERB则提出将检索问题重新定义为推荐问题,旨在选择最大化ICL任务效用的文档。这一转变不仅揭示了现有评估方法的局限性,还强调了开发专门针对ICL的基准和训练策略的必要性,从而推动了学术界在这一领域的研究进展。
衍生相关工作
ICLERB数据集的引入催生了一系列相关研究和工作,特别是在强化学习(RL)和检索模型的微调方面。例如,提出的RLRAIF算法通过利用LLM的反馈来优化检索模型,显著提升了ICL任务中的表现。此外,ICLERB还激发了对现有检索模型在ICL背景下表现的深入分析,以及对新评估方法和基准的需求探讨,推动了整个领域的发展和创新。
以上内容由遇见数据集搜集并总结生成


