How2Sign
收藏arXiv2021-04-02 更新2024-06-21 收录
下载链接:
http://how2sign.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
How2Sign数据集是由卡内基梅隆大学等机构联合创建的大型多模态美国手语(ASL)数据集,包含超过80小时的连续手语视频及相应的语音、英文文本和深度数据。该数据集通过与专业ASL手语者合作,精心录制并标注,涵盖了2500多个教学视频,涉及广泛的主题类别。数据集的创建旨在推动手语识别、翻译和生成等领域的研究,特别是在缺乏大规模标注数据集的情况下。此外,数据集还包括详细的3D姿态估计,为计算机视觉系统理解和分析手语提供了重要资源。
The How2Sign dataset is a large-scale multimodal American Sign Language (ASL) dataset jointly created by Carnegie Mellon University and other institutions. It contains over 80 hours of continuous sign language videos along with corresponding speech, English text and depth data. The dataset was meticulously recorded and annotated in collaboration with professional ASL signers, covering more than 2,500 instructional videos spanning a wide range of topic categories. The dataset was developed to advance research in fields such as sign language recognition, translation and generation, particularly in scenarios where large-scale annotated datasets are scarce. Furthermore, the dataset includes detailed 3D pose estimation, providing an important resource for computer vision systems to understand and analyze sign language.
提供机构:
卡内基梅隆大学
创建时间:
2020-08-19
搜集汇总
数据集介绍
构建方式
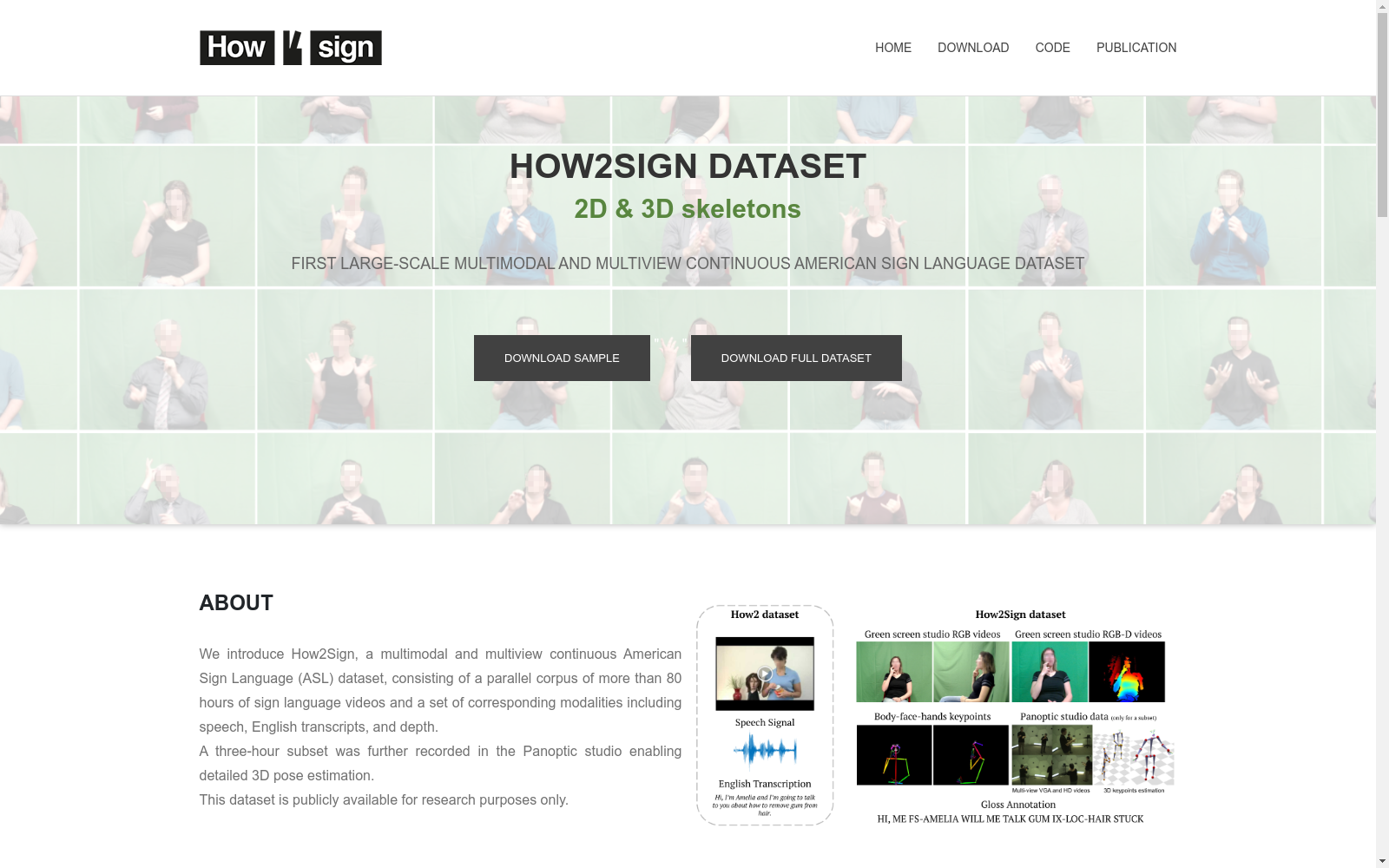
How2Sign 数据集的构建始于收集现有的 How2 数据集中的 2500 个教学视频,并将其翻译成美式手语(ASL)视频。这些 ASL 视频由 11 位参与者录制,其中包括 5 位听力正常者、4 位聋人和 2 位听力受损者。录制过程在两个地点进行:绿幕工作室和全景工作室。绿幕工作室配备了深度传感器和高清相机,用于录制多角度的 ASL 视频。而全景工作室则配备了数百个相机和传感器,用于进行详细的 3D 姿态估计。此外,数据集还包含了与视频内容对齐的语音、英语转录文本和注释。
使用方法
How2Sign 数据集可用于多种手语理解任务,如手语识别、翻译和生成,以及更广泛的多模态和计算机视觉任务,如 3D 人体姿态估计。数据集可用于训练深度学习模型,以实现手语识别、翻译和生成等功能。此外,数据集还可以用于评估模型在不同 signer 和 out-of-vocabulary 词汇上的泛化能力。
背景与挑战
背景概述
手势语作为一种重要的视觉语言,为全球约4.66亿听障人士提供主要交流方式。然而,手势语处理领域的发展长期受限于大规模标注数据集的匮乏。How2Sign数据集的创建旨在解决这一问题,它由来自How2数据集的2500多个教学视频的ASL翻译视频和标注组成,包含超过80小时的ASL视频,以及语音、英语字幕和深度信息。该数据集不仅词汇量大,且具有多模态和多视角的特点,为手势语识别、翻译和生成等任务提供了宝贵资源。
当前挑战
尽管How2Sign数据集在规模和多样性方面取得了显著进展,但手势语处理领域仍面临诸多挑战。首先,手势语具有丰富的非语言特征,如头部运动、面部表情、眼睛注视等,这些特征对于完整理解手势语至关重要,但目前的计算机视觉技术仍难以准确捕捉。其次,连续手势语的处理需要考虑手势之间的协同作用,即手势的起始和结束会根据前后手势进行调整,这对模型的识别和生成能力提出了更高要求。此外,手势语数据集的收集和标注过程耗时耗力,且容易受到主观因素的影响,导致数据存在偏差和泛化能力不足等问题。
常用场景
经典使用场景
How2Sign 数据集是一套大规模的多模态和多视角连续美国手语 (ASL) 数据集,包含超过 80 小时的手语视频,并具有多种对应的模态,包括语音、英文转录和深度信息。该数据集的特点是词汇量丰富,涵盖了超过 2,500 个来自 How2 数据集的说明性视频,并具有超过 35,000 个句子的句级对齐。此外,该数据集还包含丰富的注释,包括注释、类别标签以及自动提取的超过 6,000,000 帧的 2D 关键点。其中一部分数据集在 Panoptic 工作室中重新录制,并使用超过 500 个相机实现了高质量的 3D 关键点估计。How2Sign 数据集最经典的使用场景包括手语识别、翻译和生成,以及更广泛的多模态和计算机视觉任务,如 3D 人体姿态估计。
解决学术问题
How2Sign 数据集解决了手语处理研究中缺乏大型标注数据集的问题,尤其是连续手语数据集,即数据需要以句子级别进行分割和标注。现有的连续手语数据集数量非常有限,且无法满足当前深度学习模型的需求。How2Sign 数据集的引入为手语处理研究提供了大量的数据资源,有助于推动该领域的发展,并促进手语识别、翻译和生成等技术的进步。
实际应用
How2Sign 数据集在实际应用场景中具有广泛的应用价值。例如,它可以用于开发自动手语识别系统,帮助聋人用户更好地与外界沟通;可以用于开发自动手语翻译系统,将手语翻译成文本或语音,方便听障人士与听人沟通;可以用于开发手语生成系统,将文本或语音转换为手语,为聋人用户提供更便捷的信息获取方式。此外,How2Sign 数据集还可以用于开发 3D 人体姿态估计系统,为计算机视觉、游戏和动画等领域提供技术支持。
数据集最近研究
最新研究方向
How2Sign数据集的最新研究方向主要聚焦于连续美式手语(ASL)的多模态和多视角理解。该数据集的引入旨在解决当前手语处理研究中数据集规模有限的问题,并推动手语识别、翻译和生成等领域的研究。How2Sign数据集包含了超过80小时的多视角ASL视频,以及对应的语音、英文转录和深度信息。此外,该数据集还包含了在全景工作室录制的一个3小时子集,用于更详细的3D姿态估计。How2Sign数据集的引入为研究人员提供了丰富的数据资源,以探索手语处理的前沿问题,例如连续手语的理解、基于姿态估计的手语生成、以及多模态手语翻译等。
相关研究论文
- 1How2Sign: A Large-scale Multimodal Dataset for Continuous American Sign Language卡内基梅隆大学 · 2021年
以上内容由遇见数据集搜集并总结生成


