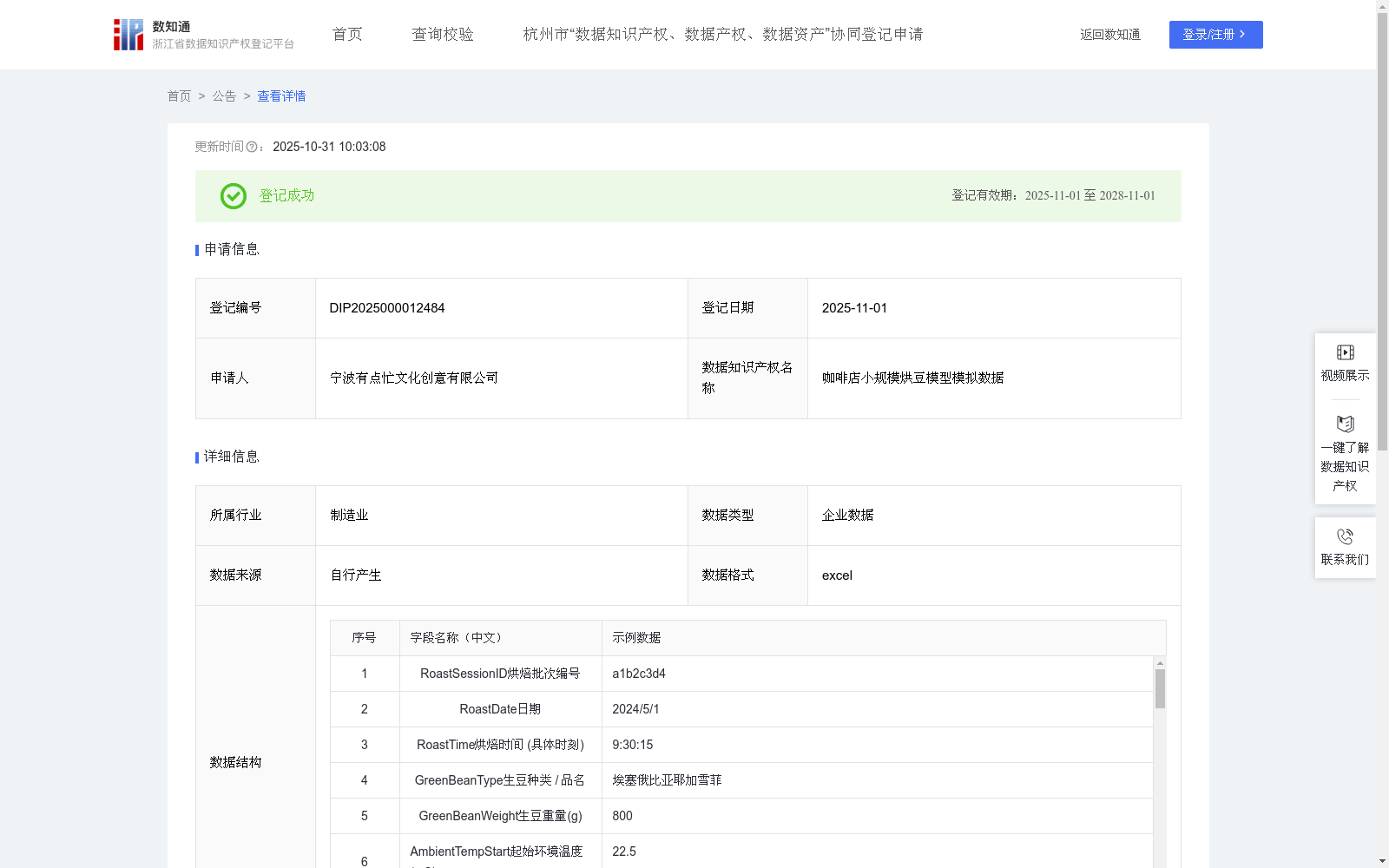
咖啡店小规模烘豆模型模拟数据
收藏浙江省数据知识产权登记平台2025-10-31 更新2025-11-01 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/7170547
下载链接
链接失效反馈官方服务:
资源简介:
烘焙曲线优化: 通过分析不同烘焙参数与最终杯测分数之间的关系,咖啡师可以识别出最佳的烘焙曲线,以最大限度地提升特定咖啡豆的风味表现。例如,调整发展时间或一爆温度,以增强咖啡的甜感或酸度。 质量控制与一致性: 监测每次烘焙的豆温、升温速率和颜色等数据,确保每次烘焙都能达到预设的目标,从而保证产品质量的一致性,减少批次间的差异。 问题诊断与故障排除:当杯测结果不佳时,可以回溯烘焙数据,找出可能的问题源头,例如环境温度的异常波动、热量供给不足或发展时间过短。新品研发与配方调整: 在尝试新的生豆或开发新的烘焙配方时,数据模型可以帮助咖啡师系统地记录和评估不同尝试的效果,加速研发进程。 库存管理与预测: 根据历史烘焙数据,预测在特定烘焙条件下所需的生豆量和预期产出量,优化生豆采购和熟豆库存。 培训与知识传承: 新烘焙师可以通过分析历史数据,学习和理解经验丰富的烘焙师如何操作,加速技能提升。1、数据收集:持续记录公司咖啡店的烘豆设备多次烘焙的输入参数和对应的输出结果数据。2、模型训练:为了根据上述数据预测和优化烘焙结果(例如:最终杯测分数、烘焙颜色、风味特征),可以采用多元线性回归 (Multiple Linear Regression, MLR) 模型或神经网络 (Neural Network) 模型。以多元线性回归 (MLR) 为例:模型形式: Y=β0+β1X1+β2X2+...+βnXn+ϵ Y: 预测的目标变量(例如:OverallCuppingScore 或 FinalRoastColor)。 X1,X2,...,Xn: 烘焙过程中的输入参数(例如:TotalRoastTime, DevelopmentTime, FirstCrackTemp, AvgRateOfRise, DrumSpeedSetting, AirflowSetting, PreheatTemp 等)。 β0: 截距。 β1,β2,...,βn: 各个自变量的回归系数,表示当其他变量不变时,该自变量每增加一个单位,因变量平均变化的量。 ϵ: 误差项。使用历史数据对MLR模型进行训练,计算出最佳的回归系数(β值)。这通常涉及到最小化预测值与实际值之间的平方误差。3、模型预测: 一旦模型训练完成,给定一组新的烘焙参数,模型就可以预测出预期的杯测分数、烘焙颜色等结果。 4、模型评估与优化: 通过评估模型的准确性(如R2值、均方误差RMSE),可以判断模型的优劣。如果模型表现不佳,可能需要收集更多数据、增加新的特征变来捕捉非线性关系。 通过这样的数据收集和模型应用,小型咖啡店能够将烘焙从艺术提升到科学的层面,实现更精确的控制和更优质的出品。
Roasting Curve Optimization: By analyzing the relationship between various roasting parameters and final cupping scores, baristas can identify the optimal roasting curves to maximize the flavor performance of specific coffee beans. For instance, adjusting development time or first crack temperature can enhance the coffee's sweetness or acidity.
Quality Control and Consistency: Monitor data such as bean temperature, heating rate, and roast color for each roasting batch to ensure every roast meets preset targets, thereby guaranteeing consistent product quality and reducing batch-to-batch variations.
Troubleshooting and Problem Diagnosis: When cupping results are subpar, roasting data can be retroactively analyzed to identify potential root causes, such as abnormal fluctuations in ambient temperature, insufficient heat supply, or overly short development time.
New Product Development and Recipe Adjustment: When experimenting with new green coffee beans or developing new roasting recipes, data models can help baristas systematically record and evaluate the outcomes of different trials, accelerating the research and development process.
Inventory Management and Forecasting: Based on historical roasting data, the required green coffee bean quantity and expected output under specific roasting conditions can be predicted, optimizing green coffee procurement and roasted bean inventory management.
Training and Knowledge Inheritance: New roasters can analyze historical data to learn and understand the operational practices of experienced roasters, accelerating their skill improvement.
1. Data Collection: Continuously record input parameters and corresponding output results from multiple roasting batches using the bean roasting equipment in the company's coffee shops.
2. Model Training: To predict and optimize roasting outcomes (e.g., final cupping scores, roast color, flavor characteristics) using the aforementioned data, either Multiple Linear Regression (MLR) models or Neural Network models can be employed. Taking Multiple Linear Regression (MLR) as an example:
Model Formulation: $Y = eta_0 + eta_1X_1 + eta_2X_2 + ... + eta_nX_n + epsilon$
Where:
- $Y$: The predicted target variable (e.g., OverallCuppingScore or FinalRoastColor).
- $X_1, X_2, ..., X_n$: Input parameters during the roasting process (e.g., TotalRoastTime, DevelopmentTime, FirstCrackTemp, AvgRateOfRise, DrumSpeedSetting, AirflowSetting, PreheatTemp, etc.).
- $eta_0$: The intercept term.
- $eta_1, eta_2, ..., eta_n$: Regression coefficients for each independent variable, representing the average change in the dependent variable per unit increase of the independent variable while all other variables remain constant.
- $epsilon$: The error term.
Train the MLR model using historical data to calculate the optimal regression coefficients (β values), which typically involves minimizing the squared error between predicted and actual values.
3. Model Prediction: Once the model is trained, given a set of new roasting parameters, the model can predict expected outcomes such as cupping scores and roast color.
4. Model Evaluation and Optimization: The performance of the model can be evaluated using metrics such as R-squared (R²) value and Root Mean Squared Error (RMSE). If the model performs poorly, more data may need to be collected or new feature variables added to capture non-linear relationships.
Through such data collection and model application, small coffee shops can elevate roasting from an art to a science, achieving more precise control and higher-quality output.
提供机构:
宁波有点忙文化创意有限公司
创建时间:
2025-07-26
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集记录了咖啡店小规模烘焙过程的550条模拟数据,涵盖生豆种类、烘焙时间、温度、杯测评分等31个参数,用于通过多元线性回归或神经网络模型优化烘焙曲线和提升产品质量。数据集每年更新,支持质量控制、问题诊断等应用,帮助咖啡店实现科学化烘焙管理。
以上内容由遇见数据集搜集并总结生成


