open-thoughts/AgentTrove
收藏Hugging Face2026-05-07 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/open-thoughts/AgentTrove
下载链接
链接失效反馈官方服务:
资源简介:
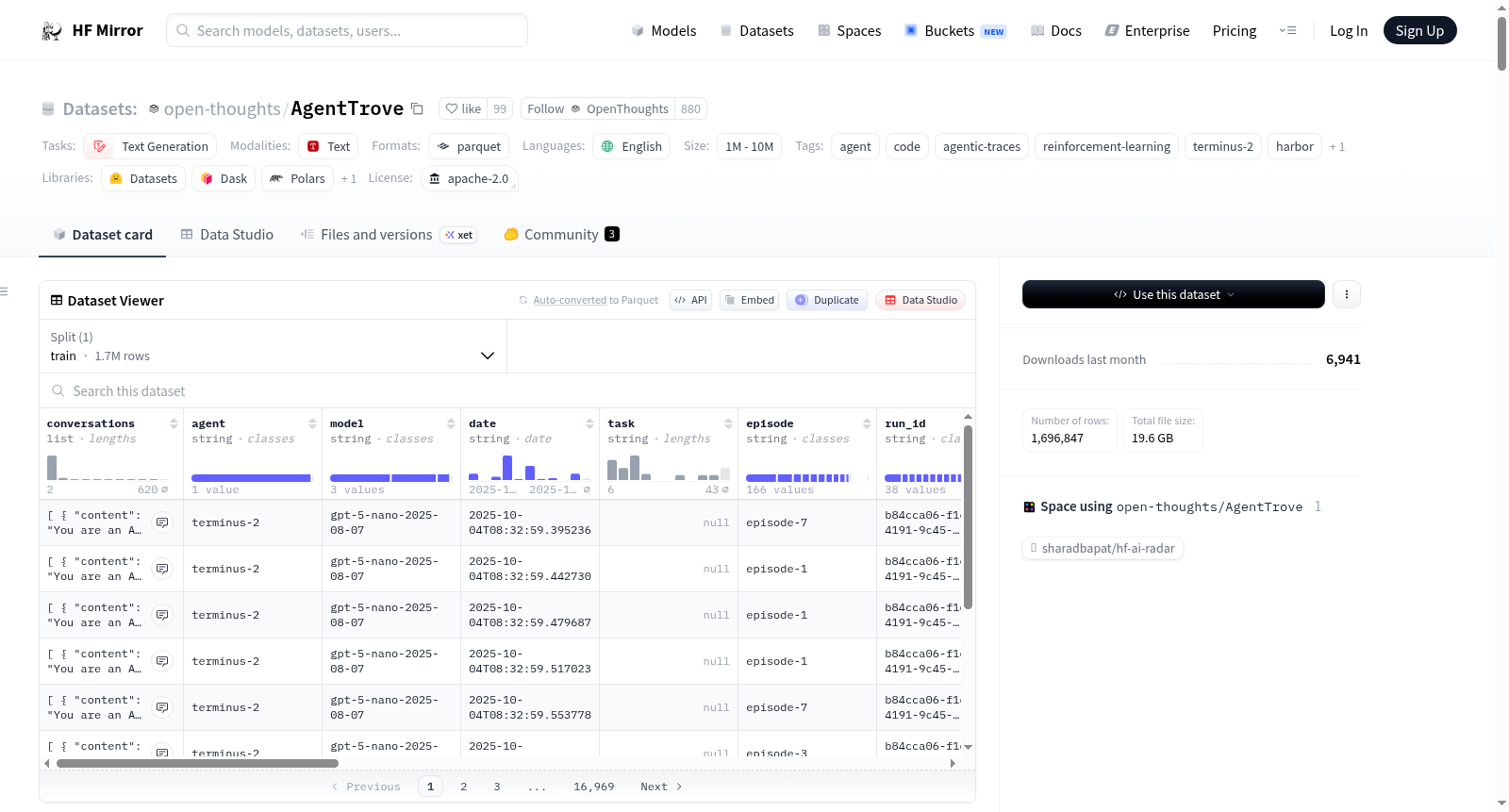
AgentTrove是迄今为止最大的开源代理交互轨迹集合,由OpenThoughts-Agent团队发布。它包含了来自219个源数据集的1,696,847行数据,涵盖代码修复、shell脚本编写、数学问题解决、竞技编程和一般计算机使用任务等多个领域。该数据集比之前最大的开源代理轨迹数据集Nemotron Terminal Corpus(430K行)大4倍。所有轨迹均以terminus-2 harness格式发布,这是一种ShareGPT风格的对话布局,每行代表一个完整的代理轨迹,包括工具调用、环境响应和最终推理。数据生成使用了开源的Harbor代理评估和数据生成框架。
AgentTrove is the largest open-source collection of agentic interaction traces to date, released by the OpenThoughts-Agent team. It contains 1,696,847 rows drawn from 219 source datasets spanning code repair, shell scripting, mathematical problem-solving, competitive programming, and general computer-use tasks. At 1.7 million rows, AgentTrove is 4× the size of the Nemotron Terminal Corpus (430 K rows), the previous largest open-source agentic trace dataset. Consistent with the Nemotron Terminal Corpus, all traces in AgentTrove are released in the terminus-2 harness format — a ShareGPT-style conversation layout where each row represents a complete agent trajectory, including tool calls, environment responses, and final reasoning. All traces were generated using the open-source Harbor agentic evaluation and data-generation framework.
提供机构:
open-thoughts
搜集汇总
数据集介绍
构建方式
AgentTrove由OpenThoughts-Agent团队构建,是迄今为止规模最大的开源智能体交互轨迹数据集。该数据集整合了来自219个源数据集的1,696,847条轨迹,这些源数据集涵盖了代码修复、脚本编写、数学问题求解、竞赛编程及通用计算机使用等多元化任务。所有轨迹均采用统一的terminus-2 harness格式,即ShareGPT风格的对话布局,每条记录代表一个完整的智能体轨迹,包含工具调用、环境响应及最终推理过程。轨迹数据由开源框架Harbor生成,确保了格式的一致性与可复现性。通过汇聚不同教师模型(如GLM-4.6、GPT 5.1 Nano、Kimi K2.0等)在不同任务场景下的交互记录,数据集在规模上达到了先前最大公开数据集Nemotron Terminal Corpus的四倍,为智能体学习研究提供了丰富的资源基础。
使用方法
AgentTrove可直接用于智能体模型的监督学习微调或强化学习训练。用户可通过HuggingFace Datasets库加载数据,每条记录包含messages(轨迹对话)、original_source(任务来源)、original_teacher(教师模型)、reward(奖励值)及task_id(任务ID)等关键字段。由于其格式与Nemotron Terminal Corpus一致,研究人员可无缝复用已有的处理流水线。推荐将成功轨迹(reward=1.0)作为正样本进行行为克隆训练,同时可结合失败案例进行对比学习或拒绝采样。数据集适用于代码生成、工具调用规划、多步推理等场景的模型优化,也可作为智能体评估基准的补充数据。用户应根据任务需求筛选特定来源或教师模型的数据子集,以适配目标应用场景的领域特性。
背景与挑战
背景概述
AgentTrove是OpenThoughts-Agent团队于2025年12月发布的开源智能体交互轨迹数据集,是目前规模最大的同类资源,包含来自219个源数据集的169万余条轨迹,覆盖代码修复、Shell脚本、数学求解、竞赛编程及通用计算机任务。其发布背景源于智能体系统(如代码生成、工具调用)对高质量、多样化训练数据的迫切需求。AgentTrove的规模是此前最大开源智能体轨迹数据集Nemotron Terminal Corpus的四倍,为强化学习与智能体微调提供了前所未有的数据基础,有望推动智能体泛化能力与鲁棒性的研究进展。
当前挑战
AgentTrove所解决的领域核心挑战是智能体训练数据的稀缺性与多样性不足:现有数据集往往规模小、任务单一,导致智能体在复杂真实场景中泛化能力差。构建过程中,团队面临数据异构性难题——219个源数据集具有不同模式,需统一转化为terminus-2格式;同时,轨迹质量参差不齐,需通过奖励信号(rewards)筛选成功与失败案例,并利用多种教师模型(如GLM-4.6、GPT-5-mini)生成轨迹,以平衡数据来源与覆盖度,确保数据集的可复现性与实用性。
常用场景
经典使用场景
在人工智能体研究的蓬勃浪潮中,AgentTrove数据集以其宏大的规模和丰富的维度,为智能体交互轨迹建模提供了坚实的基石。其最经典的用途在于训练和评估能够执行复杂多步骤任务的智能体模型,涵盖代码修复、Shell脚本编写、数学求解、算法竞赛以及通用计算机操作等多元领域。研究者常借助该数据集中标准化的terminus-2格式轨迹,开展行为克隆或强化学习,使模型习得从环境感知、工具调用到最终推理的端到端决策能力,进而推动自主智能体在真实场景中实现可靠的任务完成。
解决学术问题
AgentTrove数据集的核心学术价值在于弥合了智能体轨迹数据稀缺与规模不足之间的鸿沟。此前,开源领域最大的同类数据集仅包含43万条记录,而AgentTrove以超过169万条轨迹的体量,为探究智能体策略迁移、多任务泛化以及奖励信号设计等关键问题提供了前所未有的实验平台。该数据集的出现终结了研究者因数据量有限而不得不重复生成轨迹的困境,使得大规模预训练与微调智能体模型成为可能,显著推动了关于智能体行为一致性、鲁棒性和效率的深层机理研究。
实际应用
在实际应用层面,AgentTrove展现了卓越的赋能潜力。基于其涵盖的代码库修复、命令行操作与现实网页交互等多样化轨迹,开发者可以训练出能够辅助程序员进行自动化缺陷定位与补丁生成的智能助手,或是构建在云端环境中自主执行运维任务的虚拟工程师。此外,通过利用其中包含的奖励反馈信息,企业能够定制化地微调智能体模型,使其精准适配内网任务规范,从而在软件开发、系统管理与数据分析等垂直行业中实现从理论验证到生产部署的无缝转化。
数据集最近研究
最新研究方向
AgentTrove作为迄今规模最大的开源智能体交互轨迹数据集,汇聚了来自219个原始数据集的逾169万条代理轨迹,覆盖代码修复、Shell脚本、数学推理、竞赛编程及通用计算机操作等多类任务,体量达到先前最大同类数据集Nemotron Terminal Corpus的4倍。该数据集的发布标志着智能体行为学习领域迈入规模化数据驱动的新阶段,其采用统一的terminus-2格式与开源Harbor框架生成,为强化学习、偏好对齐及多轮工具调用研究提供了高质量的训练与评估基准。当前,围绕AgentTrove的前沿探索正聚焦于利用其丰富的多样化轨迹训练更鲁棒的通用任务代理,并通过分析海量成功与失败案例来优化智能体的错误恢复与元认知能力,此举对推动自主编程、复杂工作流自动化及人机协作系统的演进具有深远意义。
以上内容由遇见数据集搜集并总结生成


