TJNU-Ground-based-Cloud-Dataset
收藏github2024-10-30 更新2024-10-31 收录
下载链接:
https://github.com/shuangliutjnu/TJNU-Ground-based-Cloud-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
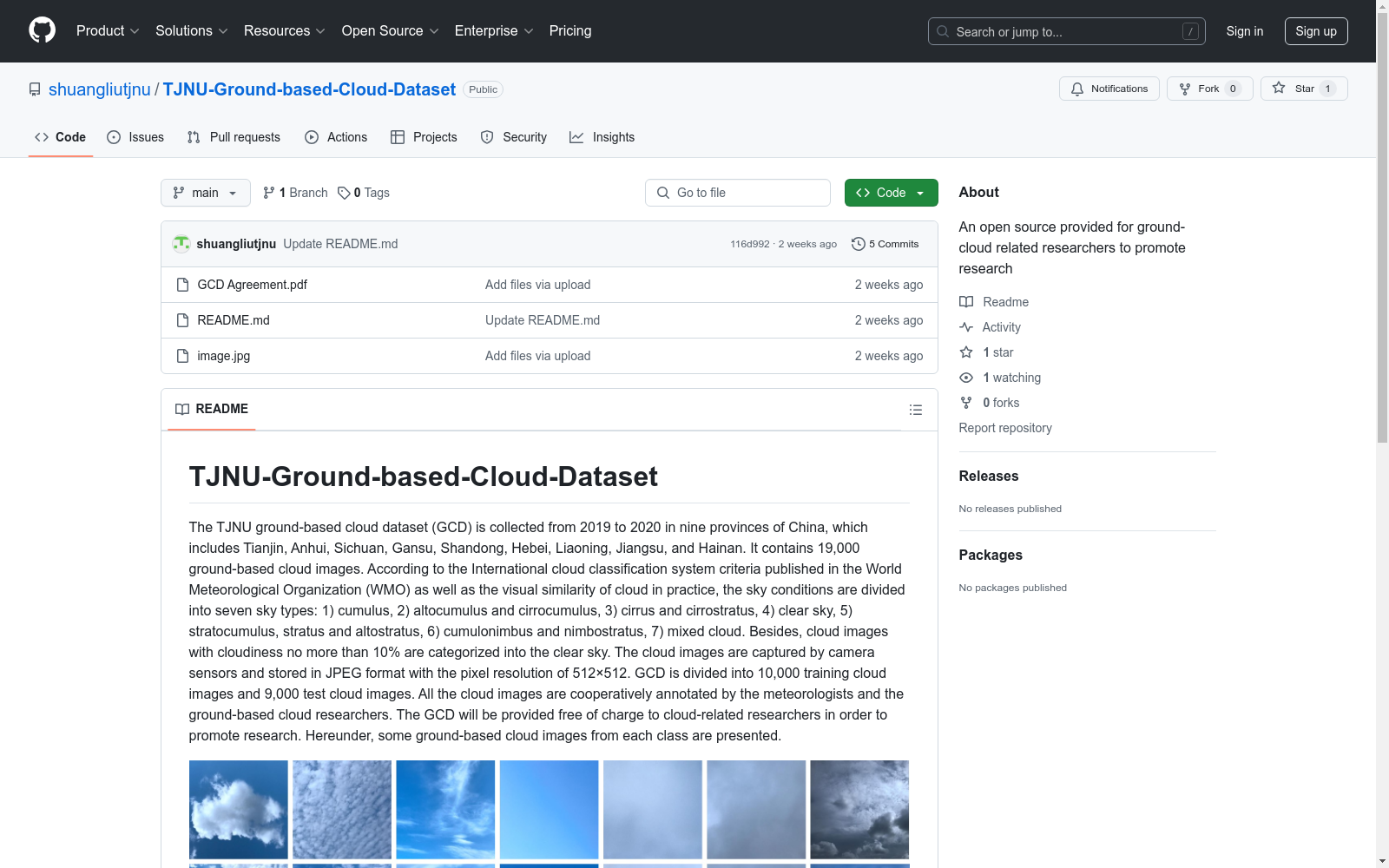
TJNU地基云数据集(GCD)是从2019年到2020年在中国九个省份(天津、安徽、四川、甘肃、山东、河北、辽宁、江苏和海南)收集的,包含19,000张地基云图像。根据世界气象组织(WMO)发布的国际云分类系统标准以及实际操作中的视觉相似性,天空条件被分为七种类型:1) 积云,2) 高积云和卷积云,3) 卷云和卷层云,4) 晴空,5) 层积云、层云和高层云,6) 积雨云和雨层云,7) 混合云。此外,云量不超过10%的云图像被归类为晴空。云图像由相机传感器捕获并以JPEG格式存储,分辨率为512×512像素。GCD分为10,000张训练云图像和9,000张测试云图像。所有云图像均由气象学家和地基云研究人员共同标注。GCD将免费提供给云相关研究人员,以促进研究。
TJNU Ground-based Cloud Dataset (GCD) was collected from 2019 to 2020 across nine provinces in China (Tianjin, Anhui, Sichuan, Gansu, Shandong, Hebei, Liaoning, Jiangsu and Hainan), containing 19,000 ground-based cloud images. According to the international cloud classification system standards released by the World Meteorological Organization (WMO) and the visual similarity in practical operations, sky conditions are categorized into seven types: 1) Cumulus, 2) Altocumulus and Cirrocumulus, 3) Cirrus and Cirrostratus, 4) Clear sky, 5) Stratocumulus, Stratus and Altostratus, 6) Cumulonimbus and Nimbostratus, 7) Mixed clouds. Additionally, cloud images with cloud cover not exceeding 10% are classified as clear sky. The cloud images were captured by camera sensors and stored in JPEG format with a resolution of 512×512 pixels. GCD was divided into 10,000 training cloud images and 9,000 test cloud images. All cloud images were jointly annotated by meteorologists and ground-based cloud researchers. GCD will be provided free of charge to researchers engaged in cloud-related studies to promote academic research.
创建时间:
2024-10-30
原始信息汇总
TJNU-Ground-based-Cloud-Dataset
数据集概述
- 时间范围:2019年至2020年
- 采集地点:中国九个省份,包括天津、安徽、四川、甘肃、山东、河北、辽宁、江苏和海南
- 数据量:包含19,000张地面云图
- 图像格式:JPEG格式,分辨率为512×512像素
- 分类:根据国际云分类系统标准和视觉相似性,将天空条件分为七种类型:
- 积云
- 高积云和卷积云
- 卷云和卷层云
- 晴空
- 层积云、层云和高层云
- 积雨云和雨层云
- 混合云
- 云量分类:云量不超过10%的图像被归类为晴空
- 数据划分:10,000张训练图像和9,000张测试图像
- 标注:由气象学家和地面云研究者共同标注
使用条款
- 数据集免费提供给云相关研究者
- 使用数据集前需阅读并同意GCD协议
- 下载和使用数据集即表示同意协议中的所有限制和要求
引用
-
如果使用该数据集进行研究,请引用以下文献:
@article{liu2022ground,
title = {Ground-based Remote Sensing Cloud Classification via Context Graph Attention Network},
author = {Liu, Shuang and Duan, Linlin and Zhang, Zhong and Cao, Xiaozhong and Durrani, Tariq S.},
journal = {IEEE Transactions on Geoscience and Remote Sensing},
volume = {60},
pages = {1-11},
year = {2022},
publisher = {IEEE}
}
下载
- 下载链接:Google Drive
搜集汇总
数据集介绍
构建方式
TJNU-Ground-based-Cloud-Dataset(GCD)的构建始于2019年,持续至2020年,涵盖了中国九个省份,包括天津、安徽、四川、甘肃、山东、河北、辽宁、江苏和海南。该数据集包含19,000张地面云图,这些图像通过相机传感器捕捉,并以512×512像素的JPEG格式存储。依据世界气象组织(WMO)发布的国际云分类系统标准及实际视觉相似性,天空条件被细分为七种类型:积云、高积云和卷积云、卷云和卷层云、晴空、层积云、层云和高积云、积雨云和雨层云、混合云。此外,云量不超过10%的图像被归类为晴空。数据集被划分为10,000张训练图像和9,000张测试图像,所有图像均由气象学家和地面云研究专家共同标注。
使用方法
使用TJNU-Ground-based-Cloud-Dataset(GCD)时,研究者需首先阅读并理解GCD协议中的所有条款,并通过指定链接下载数据集。下载和使用该数据集即表示同意协议中的所有限制和要求。数据集分为10,000张训练图像和9,000张测试图像,适用于各类云相关研究,特别是云分类和识别任务。在使用过程中,研究者应遵循学术规范,如在研究成果中引用相关文献,以确保数据的合法使用和学术诚信。
背景与挑战
背景概述
TJNU-Ground-based-Cloud-Dataset(GCD)是由中国九个省份(包括天津、安徽、四川、甘肃、山东、河北、辽宁、江苏和海南)在2019年至2020年间收集的地面云图像数据集。该数据集包含19,000张地面云图像,根据世界气象组织(WMO)发布的国际云分类系统标准以及实际视觉相似性,将天空条件分为七种类型:积云、高积云和卷积云、卷云和卷层云、晴空、层积云、层云和高积云、积雨云和雨层云、混合云。此外,云量不超过10%的图像被归类为晴空。这些图像由相机传感器捕获,并以512×512像素分辨率的JPEG格式存储。GCD被分为10,000张训练图像和9,000张测试图像,所有图像均由气象学家和地面云研究人员共同标注。该数据集旨在免费提供给云相关研究人员,以促进云研究的发展。
当前挑战
TJNU-Ground-based-Cloud-Dataset在构建过程中面临多项挑战。首先,云图像的多样性和复杂性使得分类任务变得复杂,尤其是在不同气象条件和地理位置下。其次,图像的标注过程需要高度的专业知识和经验,确保分类的准确性和一致性。此外,数据集的规模和分布也带来了存储和处理上的挑战,特别是在处理高分辨率图像时。最后,确保数据集的广泛可用性和遵守相关协议,以促进研究的同时保护数据隐私和知识产权,也是一项重要的挑战。
常用场景
经典使用场景
在气象学领域,TJNU-Ground-based-Cloud-Dataset(GCD)被广泛用于云分类研究。该数据集包含了19,000张地基云图像,涵盖了中国九个省份的多种云类型。通过结合国际云分类系统和实际视觉相似性,数据集将天空条件细分为七种类型,包括积云、高积云和卷积云、卷云和卷层云、晴空、层积云、层云和高积云、积雨云和雨层云以及混合云。这些图像的高分辨率和专业标注使其成为训练和验证云分类算法的理想选择。
解决学术问题
TJNU-Ground-based-Cloud-Dataset解决了云分类研究中的关键问题,特别是在地基观测数据的多样性和复杂性方面。通过提供大量高质量的地基云图像,该数据集有助于改进现有的云分类算法,提高其在不同地理和气象条件下的泛化能力。此外,数据集的专业标注由气象学家和云研究专家共同完成,确保了数据的准确性和可靠性,这对于推动云分类技术的进步具有重要意义。
实际应用
在实际应用中,TJNU-Ground-based-Cloud-Dataset被用于开发和优化气象预报系统。通过准确识别和分类云类型,这些系统能够更精确地预测天气变化,特别是在极端天气事件的预警和响应中。此外,该数据集还支持气候变化研究,帮助科学家分析云层变化对全球气候的影响。在农业、航空和能源管理等领域,准确的云分类信息也具有重要的应用价值。
数据集最近研究
最新研究方向
在气象学与遥感技术的交叉领域,TJNU-Ground-based-Cloud-Dataset的最新研究方向主要集中在基于地基云图像的自动分类与识别。该数据集通过整合中国九个省份的19,000张地基云图像,为研究人员提供了丰富的数据资源。研究者们正利用深度学习技术,特别是图注意力网络(Graph Attention Network),来提升云分类的准确性和效率。这一研究不仅有助于提高天气预报的精确度,还为气候变化研究提供了重要的数据支持。此外,该数据集的开放使用,极大地促进了国际合作与学术交流,推动了气象学与遥感技术的发展。
以上内容由遇见数据集搜集并总结生成


