Syn-TurnTurk
收藏arXiv2026-04-15 更新2026-04-18 收录
下载链接:
https://huggingface.co/datasets/tugrulbayrak/Syn-TurnTurk
下载链接
链接失效反馈官方服务:
资源简介:
Syn-TurnTurk是由Ata技术平台开发的合成土耳其语对话数据集,旨在解决土耳其语轮换预测研究中高质量数据缺乏的问题。该数据集包含1625条动态对话,总计12560次说话者轮换,覆盖79个不同主题,通过五种Qwen大语言模型生成,模拟真实对话中的重叠和策略性沉默。数据集生成过程中,通过调整温度参数平衡对话的连贯性和自发性,并包含5305次重叠实例和2213.5秒的并发语音。该数据集主要应用于自然语言处理和对话系统领域,用于训练模型识别土耳其语对话中的轮换边界,提升人机交互的自然度。
Syn-TurnTurk is a synthetic Turkish conversational dataset developed by Ata Technology Platform, aiming to address the shortage of high-quality data in Turkish conversation turn prediction research. This dataset contains 1,625 dynamic conversations, totaling 12,560 speaker turns, covering 79 distinct topics. It is generated via five Qwen large language models, simulating overlapping speech and strategic silences in real-world dialogues. During the dataset generation process, the temperature parameter is adjusted to balance the coherence and spontaneity of the conversations. The dataset also includes 5,305 overlapping speech instances and 2,213.5 seconds of concurrent speech. This dataset is primarily applied in the fields of natural language processing and conversational systems, used for training models to recognize turn boundaries in Turkish conversations and improving the naturalness of human-computer interaction.
提供机构:
Ata技术平台
创建时间:
2026-04-15
原始信息汇总
Syn-TurnTurk 数据集概述
数据集简介
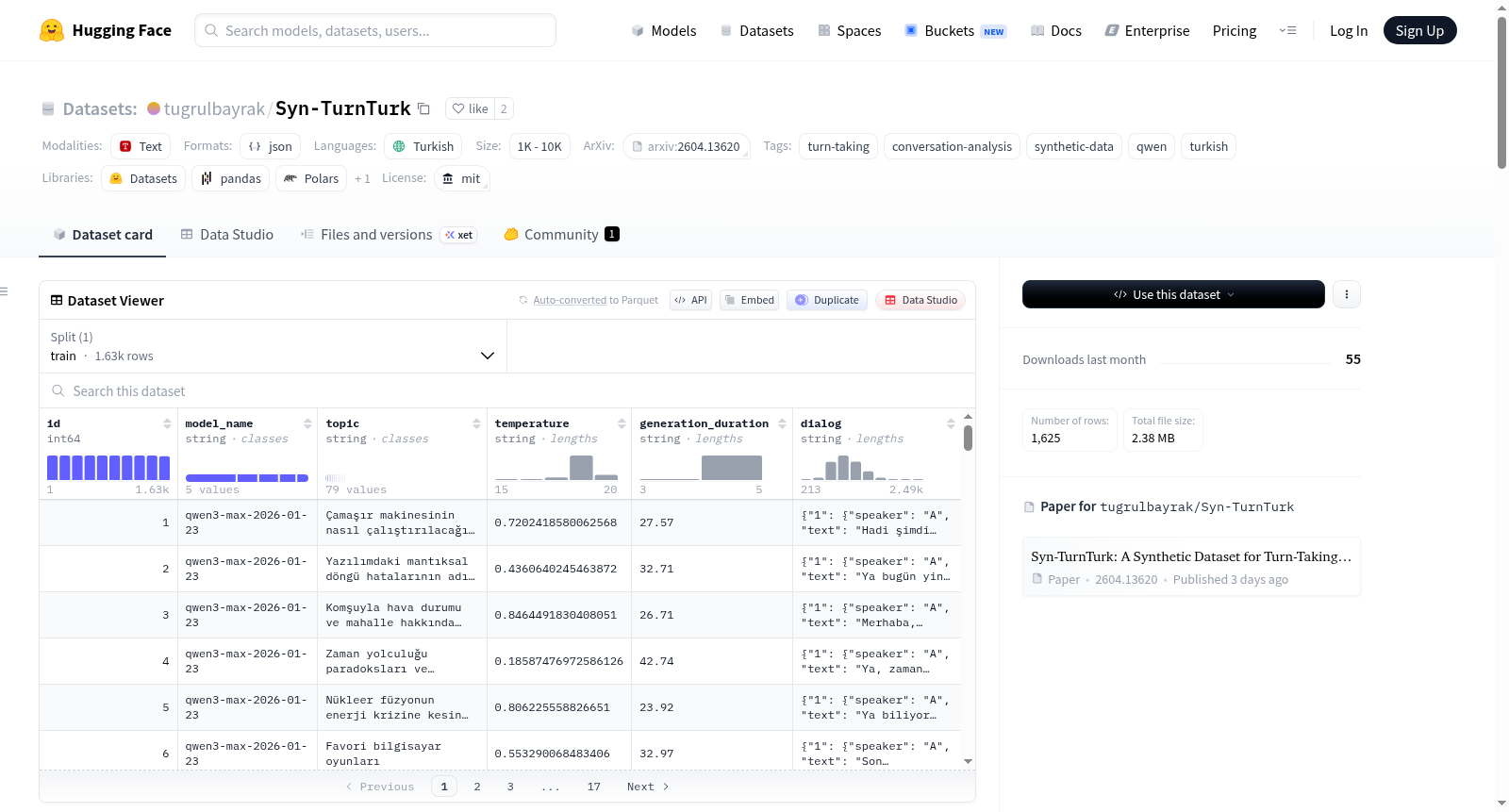
Syn-TurnTurk 是一个为改进基于语音的对话系统中的话轮转换预测而创建的合成土耳其语对话文本数据集。所有对话均通过向具有不同架构和容量的Qwen系列模型进行API调用生成。为确保多样性,每次调用时主题和温度值均为随机分配。
数据集详情
- 总对话数: 1625
- 总话轮转换数: 12560
- 主题多样性: 79
- 温度范围: 0.0 - 1.0
模型分布
| 模型来源 | 数量 |
|---|---|
| qwen3-max-2026-01-23 | 675 |
| qwen3.5-35b-a3b | 283 |
| qwen3.5-plus-2026-02-15 | 169 |
| qwen3.5-397b-a17b | 228 |
| qwen3.5-flash-2026-02-23 | 270 |
统计分析
1. 话轮转换偏移量分析
话轮转换偏移量用于测量说话者转换之间的时间差。
| 指标 | 值 |
|---|---|
| 平均值 | 0.286s |
| 中位数 | 0.742s |
| 标准差 | 0.619s |
| 最大重叠 | -2.500s |
| 最大间隔 | 0.880s |
2. 语音持续时间
| 指标 | 值 |
|---|---|
| 平均值 | 3.152s |
| 中位数 | 3.000s |
| 标准差 | 0.820s |
3. 按模型划分的平均话轮转换偏移量
| 模型 | 平均话轮转换偏移量 |
|---|---|
| qwen3.5-flash-2026-02-23 | 0.255s |
| qwen3-max-2026-01-23 | 0.266s |
| qwen3.5-35b-a3b | 0.268s |
| qwen3.5-plus-2026-02-15 | 0.358s |
| qwen3.5-397b-a17b | 0.367s |
详细结果
数据集中共有5305次重叠(总计2213.50秒)和总计5810.58秒的静默时间。平均每次对话包含3.26次重叠和3.58秒静默。
许可信息
本数据集采用MIT许可证。
引用信息
若使用本数据集,请引用以下论文: bibtex @misc{bayrak2026synturnturk, title={Syn-TurnTurk: A Synthetic Dataset for Turn-Taking Prediction in Turkish Dialogues}, author={Ahmet Tuğrul Bayrak and Mustafa Sertaç Türkel and Fatma Nur Korkmaz}, year={2026}, eprint={2604.13620}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2604.13620}, }
搜集汇总
数据集介绍
构建方式
在对话系统研究领域,构建高质量的语言特定数据集是推进自然交互技术的关键。Syn-TurnTurk数据集的生成依托于五种不同的Qwen大语言模型,通过API调用实现。为确保对话的多样性与真实性,研究团队预先设定了79个独特话题,并在每次生成中随机选取主题作为对话基础。模型被明确指令融入重叠发言、策略性沉默及日常插话等人类言语特征,以模拟真实交流场景。通过调整温度参数控制生成内容的变异性,多数对话在温度为0.7的条件下生成,以平衡语句连贯性与对话自发性。最终生成的原始数据经过格式化处理,并托管于Hugging Face平台,便于后续分析与应用。
使用方法
为验证数据集在话轮预测任务中的效用,Syn-TurnTurk被设计用于训练与评估多种机器学习与深度学习模型。在使用前,需对对话文本进行标注处理:在每个话轮转换处,将文本序列的最后三分之一标记为正样本,并从剩余部分随机选取两段作为负样本,最终构成包含12,560个正样本与25,120个负样本的平衡数据集。文本表示采用intfloat/multilingual-e5-large嵌入模型,以捕捉土耳其语的语言结构与语义细微差别。模型训练可采用决策树、随机森林、逻辑回归、LSTM及双向LSTM等架构,并通过五折交叉验证评估性能。研究结果表明,双向LSTM与集成学习方法在该数据集上表现优异,准确率与AUC分别达到0.839和0.910,证实了数据集在提升土耳其语人机交互自然度方面的潜在价值。
背景与挑战
背景概述
随着生成式人工智能的蓬勃发展,语音聊天机器人已成为众多行业的关键工具。然而,构建能够模拟人类自然对话节奏的系统仍面临严峻挑战,尤其在基于语音的交互中,对话时机的精准把握对于用户体验至关重要。针对土耳其语这类资源相对匮乏的语言,高质量对话数据的缺失进一步加剧了该领域的研究难度。在此背景下,Ata Technology Platforms的研究团队于2026年提出了Syn-TurnTurk数据集,该数据集通过调用多种Qwen大语言模型生成了包含1,625段对话的合成语料,旨在解决土耳其语对话中话轮转换预测的核心问题。该数据集的构建不仅填补了土耳其语在该领域的空白,也为开发更自然的人机交互系统提供了重要的数据基础。
当前挑战
Syn-TurnTurk数据集致力于解决话轮转换预测这一核心领域挑战,其目标在于使模型能够准确识别对话中的话轮边界,从而避免语音聊天机器人因依赖简单静默检测而错误打断用户的问题。这一挑战在土耳其语中尤为突出,因其独特的后缀语法和句子结构使得基于英语训练的现有模型难以捕捉其对话细微差别。在数据集构建过程中,研究团队面临合成数据真实性模拟的挑战,需通过指令引导模型生成包含重叠发言、策略性沉默等真实对话特征的数据,并利用温度参数调控生成多样性以确保语料覆盖79个不同主题。此外,如何确保合成对话的时序动态性,使其包含足够的交叠实例与静默间隙以准确反映自然言语模式,亦是构建过程中的关键难点。
常用场景
经典使用场景
在自然语言处理与对话系统领域,Syn-TurnTurk数据集为土耳其语对话中的话轮转换预测提供了关键资源。该数据集通过模拟真实对话中的重叠发言、策略性沉默等言语特征,为模型训练创造了高度仿真的语言环境。其经典应用场景集中于训练和评估各类机器学习与深度学习模型,特别是双向长短期记忆网络和集成学习方法,以精准识别土耳其语对话中的话轮边界,从而优化语音交互系统的响应时机。
解决学术问题
Syn-TurnTurk数据集有效解决了土耳其语在话轮转换预测研究中面临的数据稀缺问题。传统基于静默检测的方法难以适应土耳其语独特的后缀语法和句子结构,常导致对话中断。该数据集通过合成对话模拟真实言语模式,使模型能够学习语言内部的结构性线索,而非依赖简单的时序特征。这推动了针对低资源语言的话轮预测研究,为建立语言特定的对话理解模型提供了实证基础,促进了跨语言对话系统的发展。
实际应用
在实际应用中,Syn-TurnTurk数据集训练的模型可显著提升土耳其语语音助手和客服系统的交互自然度。系统能够更准确地判断用户发言是否结束,减少不当打断,保障对话流畅性。这对于土耳其语地区的智能车载系统、在线教育平台以及无障碍通信工具具有重要价值,能够为用户提供更人性化、高效率的语音交互体验,推动相关技术在本土化场景中的落地与普及。
数据集最近研究
最新研究方向
在对话系统领域,转向预测是提升人机交互自然度的核心挑战,尤其对于资源稀缺的语言如土耳其语。Syn-TurnTurk数据集的推出,标志着利用大语言模型生成高质量合成数据的前沿探索。该数据集通过模拟真实对话中的重叠发言与策略性沉默,为模型训练提供了丰富的语言结构线索。当前研究聚焦于结合深度学习方法,如BI-LSTM与集成模型,以捕捉土耳其语特有的语法和时序特征,推动跨语言对话系统向更精准、低延迟的方向演进。这一进展不仅弥补了土耳其语数据空白,也为多语言转向预测的普适性框架奠定了实证基础。
相关研究论文
- 1Syn-TurnTurk: A Synthetic Dataset for Turn-Taking Prediction in Turkish DialoguesAta技术平台 · 2026年
以上内容由遇见数据集搜集并总结生成


