ParlaSpeech-CZ
收藏数据集概述
数据集名称
ParlaSpeech-CZ.v1.0
数据来源
该数据集由捷克部分ParlaMint语料库中的议会会议记录和捷克议会YouTube频道提供的议会录音构建而成。
数据内容
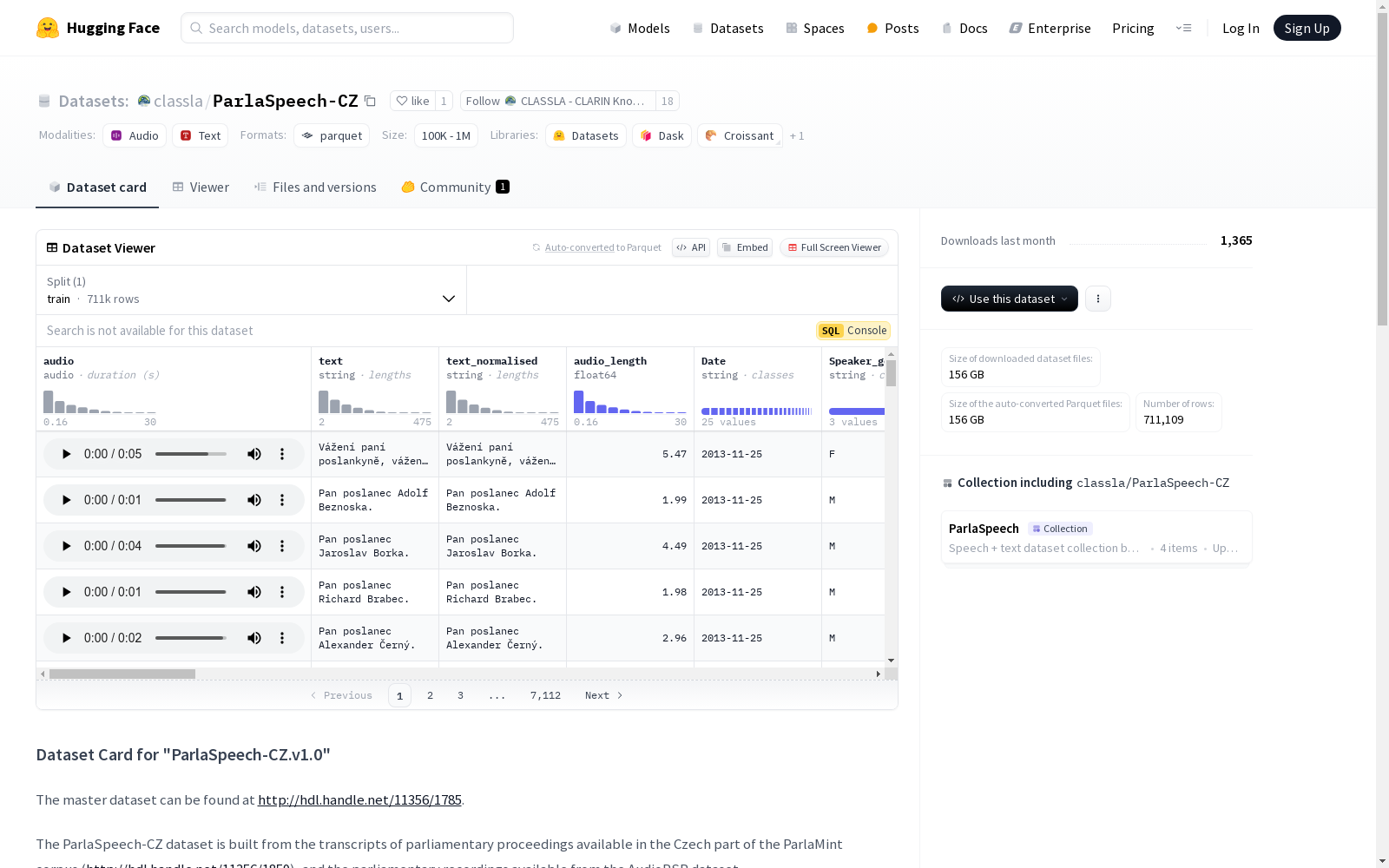
数据集包含与记录中特定句子对应的音频片段,并提供单词级别的对齐信息,包括字符和毫秒的起始和结束偏移。每个片段通过话语ID和字符偏移与ParlaMint 4.0语料库关联。
数据特征
- audio: 音频数据,采样率为16000Hz。
- audio_end: 音频结束时间,数据类型为float64。
- audio_length: 音频长度,数据类型为float64。
- audio_source: 音频来源,数据类型为string。
- audio_start: 音频开始时间,数据类型为float64。
- id: 标识符,数据类型为string。
- sentence_id: 句子标识符,数据类型为string。
- speaker_info: 说话者信息,包含多个子字段,如Agenda、Body、Date等,数据类型均为string。
- text: 文本内容,数据类型为string。
- text_end: 文本结束位置,数据类型为int64。
- text_start: 文本开始位置,数据类型为int64。
- words: 单词列表,包含多个子字段,如char_e、char_s、id等,数据类型分别为int64和string。
数据分割
- train: 训练集,包含720091个样本,总大小为187604534404.769字节。
数据集大小
- 下载大小: 40094695351字节。
- 数据集大小: 187604534404.769字节。
数据集特点
- 已移除超过30秒的序列,适用于大多数现代GPU。
- 包含
text_normalised属性,移除了议会评论(如[[Applause]]等)。
引用信息
@inproceedings{ljubesic-etal-2022-parlaspeech, title = "{P}arla{S}peech-{HR} - a Freely Available {ASR} Dataset for {C}roatian Bootstrapped from the {P}arla{M}int Corpus", author = "Ljube{v{s}}i{c}, Nikola and Kor{v{z}}inek, Danijel and Rupnik, Peter and Jazbec, Ivo-Pavao", editor = "Fi{v{s}}er, Darja and Eskevich, Maria and Lenardi{v{c}}, Jakob and de Jong, Franciska", booktitle = "Proceedings of the Workshop ParlaCLARIN III within the 13th Language Resources and Evaluation Conference", month = jun, year = "2022", address = "Marseille, France", publisher = "European Language Resources Association", url = "https://aclanthology.org/2022.parlaclarin-1.16", pages = "111--116", }