marcov/cbt_CN_promptsource
收藏Hugging Face2024-11-25 更新2024-12-14 收录
下载链接:
https://hf-mirror.com/datasets/marcov/cbt_CN_promptsource
下载链接
链接失效反馈官方服务:
资源简介:
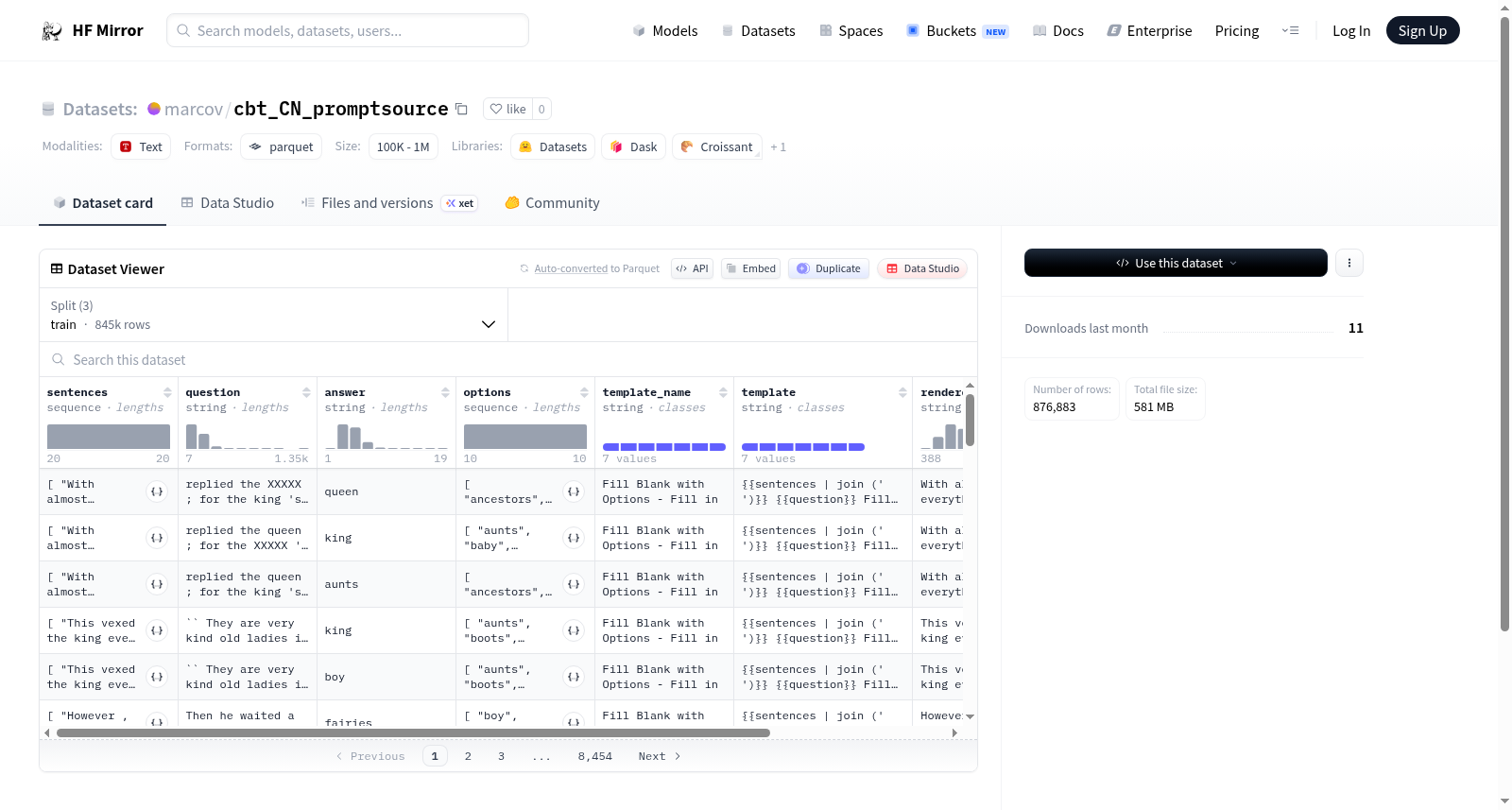
该数据集包含多个特征,包括句子、问题、答案、选项等。数据集分为训练集、测试集和验证集,其中训练集包含845,383个示例,测试集包含17,500个示例,验证集包含14,000个示例。数据集的下载大小为581,030,268字节,总大小为4,483,106,162字节。
The dataset contains multiple features, including sentences, questions, answers, options, etc. The dataset is divided into training, test, and validation sets, with the training set containing 845,383 examples, the test set containing 17,500 examples, and the validation set containing 14,000 examples. The download size of the dataset is 581,030,268 bytes, and the total size is 4,483,106,162 bytes.
提供机构:
marcov
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个用于自然语言处理任务的大规模文本数据集,包含约 877k 行数据,以 Parquet 格式存储,并分为训练、验证和测试集。数据特点包括填空式问答任务,涉及句子序列、问题、答案和选项字段,主要用于文本理解和生成模型的训练与评估。
以上内容由遇见数据集搜集并总结生成


