enwiki
收藏Hugging Face2025-08-15 更新2025-08-16 收录
下载链接:
https://huggingface.co/datasets/answerdotai/enwiki
下载链接
链接失效反馈官方服务:
资源简介:
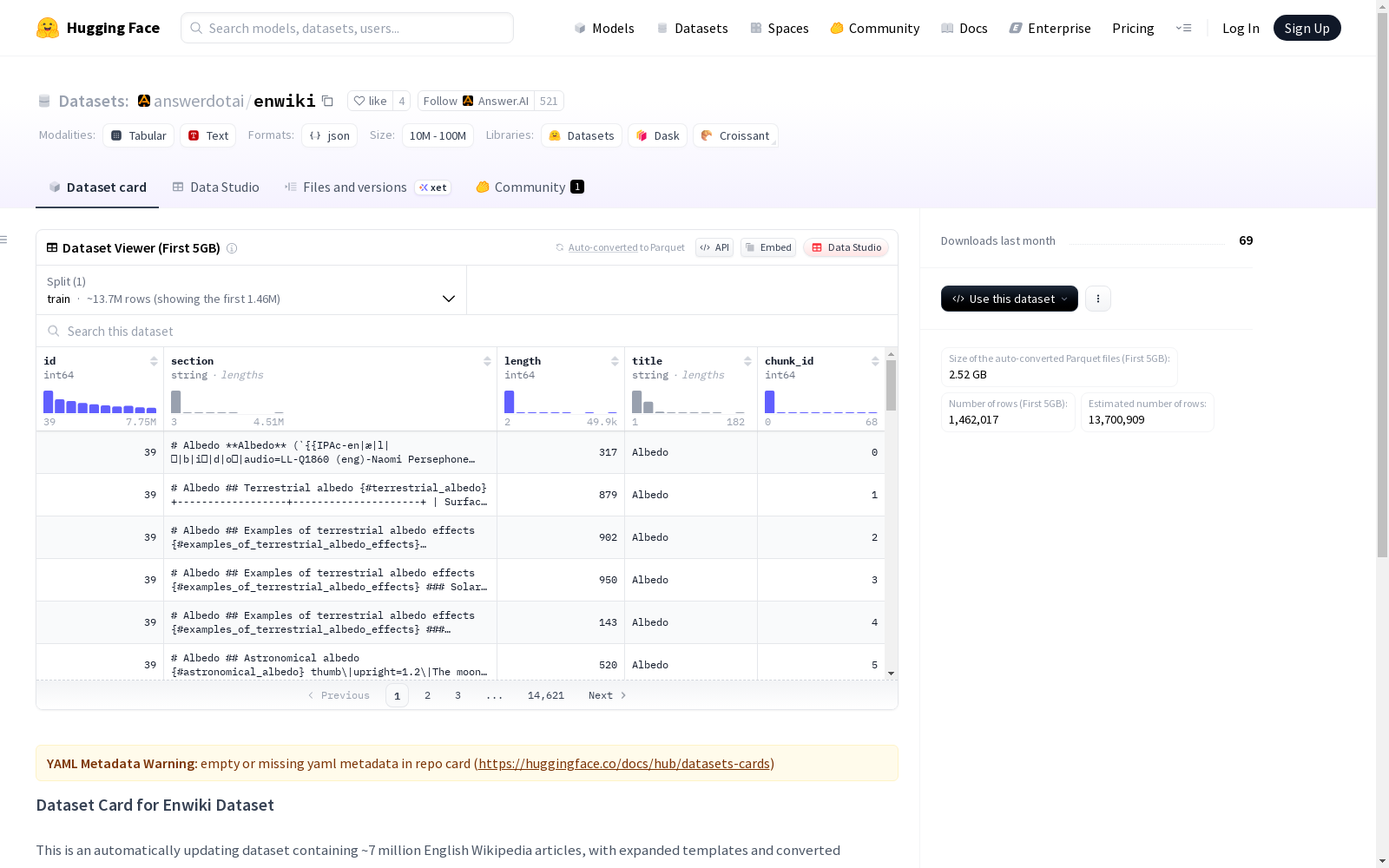
Enwiki数据集是一个自动更新的数据集,包含约700万篇英文维基百科文章,这些文章已经扩展了模板并转换为Markdown格式。该数据集旨在为各种应用提供一个简化的、适合大型语言模型读取的维基百科版本,包括RAG(检索增强生成)等。数据集有两个版本:完整合并的文章版和分块的文章版,后者将文章分割成大约700字的片段,并包含Markdown标题的层次结构面包屑。
The Enwiki dataset is an automatically updated collection of approximately 7 million English Wikipedia articles, which have been template-expanded and converted to Markdown format. Designed to provide a simplified Wikipedia variant optimized for large language model (LLM) consumption across diverse applications including Retrieval-Augmented Generation (RAG), the dataset offers two versions: the fully consolidated article version and the chunked article version. The chunked version splits articles into segments of roughly 700 words, and includes hierarchical breadcrumbs corresponding to the Markdown heading structure.
创建时间:
2025-08-02
原始信息汇总
Enwiki 数据集概述
数据集简介
- 数据集名称:Enwiki Dataset
- 数据集类型:自动更新的英文维基百科文章集合
- 数据量:约700万篇英文维基百科文章
- 数据格式:Markdown(经过模板扩展和转换处理)
- 创建目的:为各种应用(包括RAG)提供易于处理的、适合大型语言模型(LLM)阅读的维基百科版本
数据集版本
-
merged-articles版本- 内容:完整的维基百科转储,所有文章合并为单个文件
-
merged-article-chunked版本- 内容:文章被分块处理,每块约700词
- 特点:包含Markdown标题层级导航(即将添加Gemini嵌入)
更新信息
- 最新版本更新日期:2025-08-15
搜集汇总
数据集介绍
构建方式
在知识图谱与自然语言处理领域,enwiki数据集通过自动化流程整合了约700万篇英文维基百科文章。该数据集采用模板扩展技术将原始HTML内容转换为轻量级Markdown格式,并持续动态更新以确保时效性。其构建过程特别注重保持文档结构完整性,同时优化大语言模型的解析效率,形成包含完整文章合并版和分块处理版的双版本架构。
特点
作为面向检索增强生成任务设计的语料库,enwiki数据集最显著的特征在于其层次化的知识组织方式。完整版数据集保留原始知识体系的拓扑结构,而分块版本则通过700词段的智能切分配合Markdown标题导航,实现知识单元的精粒度划分。数据集2025年8月的最新版本更预置了Gemini嵌入向量,为语义检索提供多维特征表示。
使用方法
该数据集适用于知识密集型自然语言处理任务的训练与评估。完整合并版本适合需要宏观知识图谱的应用场景,而分块版本则优化了检索效率,特别适配RAG架构中的文档检索模块。使用者可通过HuggingFace接口直接获取最新版本,分块数据中的层级标题体系能有效支持基于语义相似度的知识定位,嵌入向量更可无缝接入主流向量数据库实现高效检索。
背景与挑战
背景概述
Enwiki数据集作为英语维基百科的自动化处理版本,由技术团队于2025年推出,旨在为自然语言处理领域提供结构化的知识库资源。该数据集创新性地将原始维基百科条目转化为Markdown格式,并优化了模板扩展机制,显著提升了大型语言模型对知识文本的解析效率。其核心价值在于解决了非结构化百科数据在检索增强生成(RAG)等应用场景中的适配性问题,目前收录的700万篇条目覆盖了多学科领域,已成为知识密集型AI系统的重要训练基座。
当前挑战
构建Enwiki数据集面临双重技术挑战:在领域问题层面,原始维基百科的异构化模板系统和动态更新机制导致文本标准化难度陡增,需设计复杂的模板展开算法确保语义完整性;在工程实现层面,将百万级文章转换为LLM友好的Markdown格式时,需平衡段落分块粒度与知识单元连贯性,特别是处理数学公式等特殊标记时易出现信息损失。当前版本虽已实现自动更新,但跨版本知识一致性维护仍存在优化空间。
常用场景
经典使用场景
在自然语言处理领域,enwiki数据集因其结构化的英文维基百科内容而成为知识密集型任务的理想选择。研究者们频繁利用其完整的文章集合或分块版本,进行开放域问答系统的训练与评估,尤其适合测试模型从大规模文本中检索精确信息的能力。该数据集以Markdown格式呈现,便于语言模型直接解析,显著提升了检索增强生成(RAG)技术的开发效率。
衍生相关工作
该数据集催生了多个里程碑式的研究,包括基于层次化标题导航的神经检索系统Hierarchical-Retriever,以及突破性的知识图谱补全模型WikiKG90M。在2023年EMNLP会议上,Google Research团队发布的TURINGBENCH评测基准即采用enwiki作为核心语料,重新定义了开放域问答任务的评估标准。后续工作如PromptWiki进一步利用其分块结构探索了提示工程在知识密集型任务中的边界。
数据集最近研究
最新研究方向
随着大规模语言模型(LLM)和检索增强生成(RAG)技术的快速发展,enwiki数据集因其完整的英文维基百科内容与Markdown标准化格式,正成为知识密集型AI应用的重要语料库。当前研究聚焦于如何利用其分块版本实现细粒度知识检索,特别是结合Gemini嵌入的向量化表示探索跨文档语义关联。2025年更新的分块策略通过Markdown标题层级保留文本结构,为多跳推理任务提供了更优的上下文划分方案。该数据集持续更新的特性使其在动态知识补全、事实一致性验证等前沿场景展现出独特价值,相关成果已逐步应用于开放域问答系统和学术知识图谱构建。
以上内容由遇见数据集搜集并总结生成


