greek-bar-bench
收藏Hugging Face2025-05-31 更新2025-06-01 收录
下载链接:
https://huggingface.co/datasets/AUEB-NLP/greek-bar-bench
下载链接
链接失效反馈官方服务:
资源简介:
GreekBarBench是一个基准数据集,旨在评估LLMs在希腊律师考试中五个不同法律领域的复杂法律推理问题上的表现,要求引用法律条文和案例事实。数据集由2015年至2024年希腊律师考试的真题组成,旨在模拟开放书籍考试格式,为模型提供案例事实、法律问题和相关法律法典章节。任务要求模型分析事实、识别适用的法律条文、综合信息并提供包含明确引用案例事实和法律条文的法律分析答案。数据集旨在评估复杂的法律推理能力,包括多跳推理和对法定法律的准确应用。
创建时间:
2025-05-30
原始信息汇总
GreekBarBench 数据集概述
数据集基本信息
- 名称: GreekBarBench (GBB)
- 类型: 法律问答与文本生成
- 语言: 希腊语 (el)
- 许可证: CC-BY-4.0
- 标签: 法律、推理、自由文本、引用、希腊语
- 数据量: <1K 样本
- 创建者: Odysseas S. Chlapanis
- 资助方: Archimedes Unit, Athena Research Center
数据集目的
评估大型语言模型在希腊律师资格考试中复杂法律推理问题的表现,要求引用法律条文和案件事实。
数据集结构
主要文件
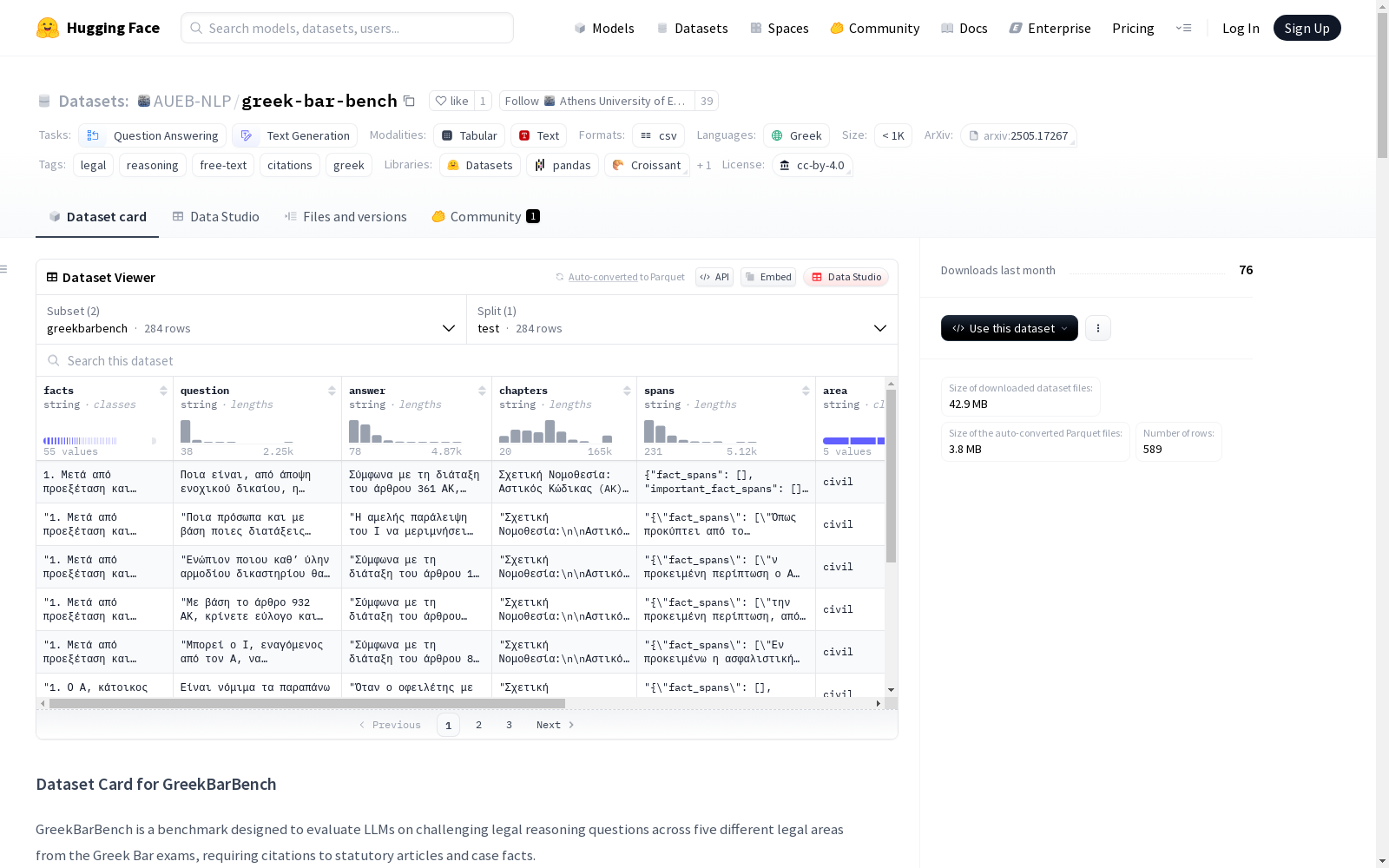
greekbarbench.csv(主测试集)- 字段:
facts: 案件事实(带编号的字符串)question: 法律问题answer: 标准答案(自由文本)chapters: 相关法律章节全文(约60k tokens)spans: 标注文本片段(事实/引用条文/分析维度)area: 法律领域(民事/刑事/商业/公共/律师)date: 考试场次标识(格式:{phase}_{year})articles: 引用条文内容number: 问题序号
- 字段:
gbb_jme.csv(LLM法官元评估集)- 字段:
number: 问题序号model: 模型标识response: 模型回答facts/articles/analysis: 专家评分(1-10)avg: 平均分area/date: 同主文件reasoning: 模型推理过程(如有)
- 字段:
数据来源
- 原始数据: 2015-2024年希腊律师资格考试题及参考答案(来自lawspot.gr)
- 法律条文: 希腊法律数据库(et.gr)
- 论文: arXiv:2505.17267
创建过程
- 数据收集:
- 考试题PDF转换为文本
- 使用Segment-Any-Text模型分割案件事实
- 提取参考答案中引用的法律条文
- 标注:
- 2名希腊执业律师标注:
- GBB-JME集的模型回答评分
- 标准答案的文本片段标注(用于Span-Judge)
- 2名希腊执业律师标注:
评估方法
- 三维评分系统:
- 事实理解(Facts)
- 条文引用(Cited Articles)
- 分析质量(Analysis)
- LLM法官框架:
- Simple-Judge: 基础提示词评估
- Span-Judge: 基于标注片段的增强评估
- 元评估指标:
- 软配对准确率(SPA)
- 最佳法官模型: GPT-4.1-mini (SPA=0.856)
领域分布
涵盖5个法律领域:
- 民事(civil)
- 刑事(criminal)
- 商业(commercial)
- 公共(public)
- 律师伦理(lawyers)
引用格式
bibtex @misc{chlapanis2025greekbarbench, title={GreekBarBench: A Challenging Benchmark for Free-Text Legal Reasoning and Citations}, author={Odysseas S. Chlapanis et al.}, year={2025}, eprint={2505.17267}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
构建方式
GreekBarBench数据集基于2015至2024年希腊律师资格考试的真实试题构建,涵盖民事、刑事、商业、公共和律师伦理五大法律领域。研究团队从官方考试手册中提取虚构案例,通过神经文本分割模型对案件事实进行细粒度标注,并整合相关法律条文作为上下文背景。每道试题均包含案件事实描述、法律问题、标准答案及对应法条章节,构建过程严格遵循开卷考试模式,确保评估模型在真实法律场景下的推理能力。
特点
该数据集突出体现三大特征:采用三维评分体系(事实理解、法条引用、分析推理)全面评估法律推理能力;包含希腊语法律文本特有的语言结构和专业术语;提供基于人类专家标注的元评估基准GBB-JME。特别设计的span标注体系能精确追踪答案中事实引用、法条应用和逻辑分析的文本片段,为法律大模型提供可解释的评估框架。数据集包含288个测试样本,法律条文平均长度达6万标记,有效检验模型处理长文本和复杂法律概念的能力。
使用方法
使用该数据集时,需将案件事实、法律问题和相关法条章节作为输入,要求模型生成包含明确引用的自由文本答案。评估采用LLM-as-a-Judge框架,推荐使用增强版Span-Judge提示策略,该策略结合人类标注的span rubric能显著提升评分准确性。研究人员可通过GBB-JME子集进行法官模型元评估,采用软配对准确率(SPA)指标衡量自动评分与人类专家评分的一致性。数据集支持端到端评估和分阶段验证,适用于法律推理、引文生成和跨语言法律分析等研究场景。
背景与挑战
背景概述
希腊法律考试基准数据集GreekBarBench由雅典研究中心Archimedes Unit的Odysseas S. Chlapanis团队于2025年构建,旨在评估大型语言模型在希腊法律领域的复杂推理能力。该数据集收录了2015至2024年间希腊律师资格考试的真实试题,涵盖民事、刑事、商事、公法及律师伦理五大法律领域,要求模型在开卷考试情境下结合案例事实与法律条文进行多跳推理,并生成包含明确引用的自由文本答案。作为首个针对希腊法律体系的专业评测基准,该数据集为法律人工智能研究提供了重要的跨语言评估工具,推动了法律文本理解与推理技术的发展。
当前挑战
该数据集面临双重挑战:在领域问题层面,法律推理要求模型精确理解案例事实、准确引用相关法条并进行逻辑严密的专业分析,这对自然语言处理技术提出了极高的领域适应性与逻辑连贯性要求;在构建过程中,团队需处理希腊语法律文本特有的复杂语法结构,将PDF格式的考试材料转化为结构化数据,并通过专业律师人工标注建立三维评分体系(事实理解、法条引用、分析论证)。此外,为确保评估可靠性,还需设计基于大语言模型的自动评分机制,并通过GBB-JME元评估基准验证其与人类专家评分的一致性。
常用场景
经典使用场景
在法学与自然语言处理的交叉领域,GreekBarBench数据集为研究者提供了一个独特的实验平台。该数据集通过模拟希腊律师资格考试的开放式答题场景,要求模型在给定案件事实和相关法律条文的基础上,生成包含明确引用的自由文本答案。这种设置特别适合评估大语言模型在复杂法律推理任务中的表现,包括多跳推理能力、法律条文准确引用能力以及综合分析能力。
实际应用
在实际应用中,GreekBarBench数据集可服务于多个重要场景。法律科技公司可利用该数据集开发智能法律助手,帮助律师快速检索相关判例和法条;法学院校可基于此构建模拟考试系统,辅助学生备考;司法机构也可借鉴其评估框架,用于自动化法律文书审查。这些应用显著提高了法律工作的效率和质量。
衍生相关工作
围绕该数据集已产生一系列创新性研究。最突出的工作包括基于Span-Judge提示的GPT-4.1-mini评估框架,其0.856的SPA分数展现了优异的评判能力。此外,研究者还开发了多维度评分系统,将法律答案解构为事实理解、条文引用和分析推理三个维度,为后续法律AI研究提供了可借鉴的方法论。这些衍生工作共同推动了法律智能评估技术的发展。
以上内容由遇见数据集搜集并总结生成


