FreedomIntelligence/PubMedVision
收藏Hugging Face2025-02-18 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/FreedomIntelligence/PubMedVision
下载链接
链接失效反馈官方服务:
资源简介:
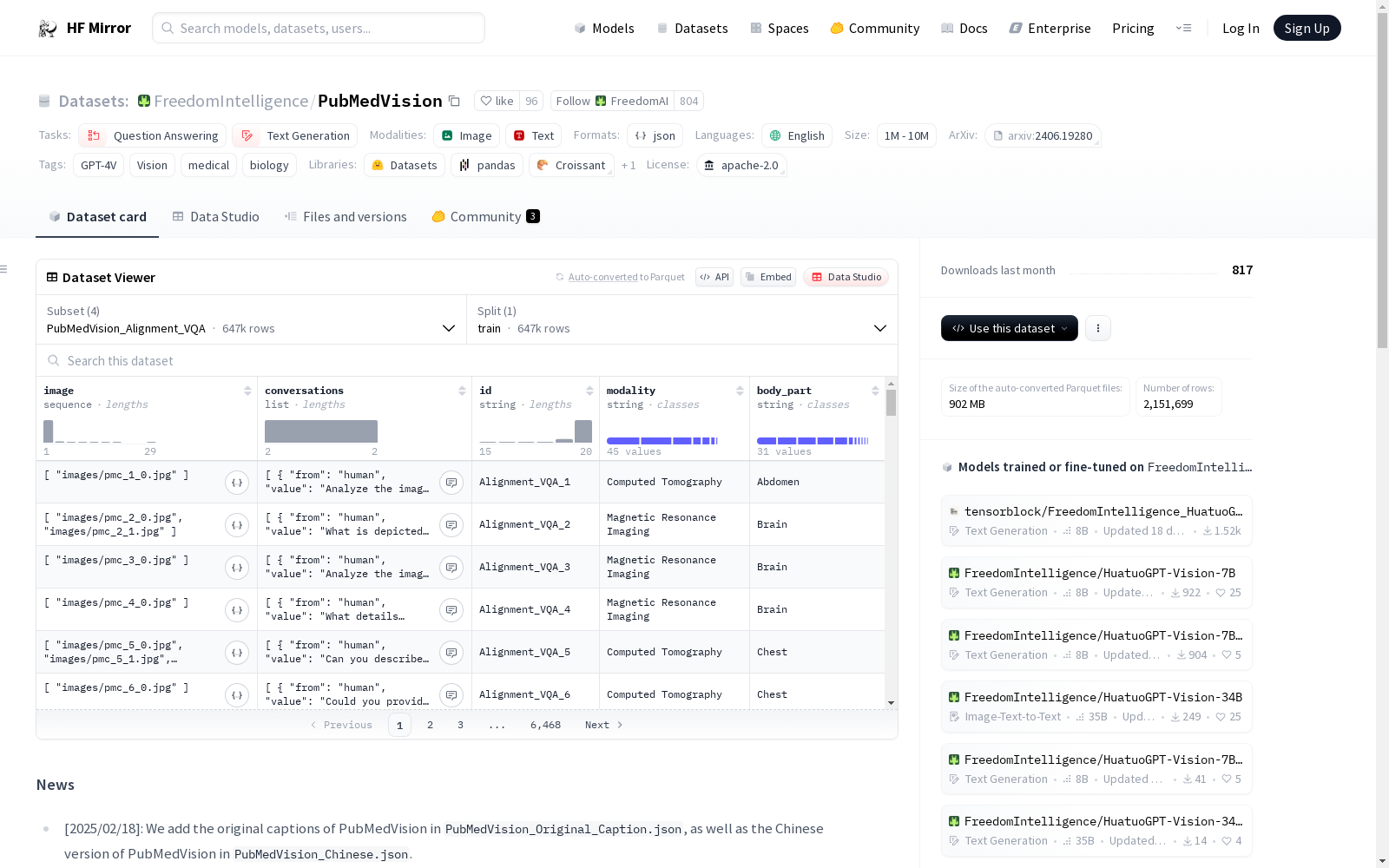
PubMedVision是一个大规模的医学视觉问答(VQA)数据集。我们从PubMed中提取了高质量的图像-文本对,并使用GPT-4V对其进行重新格式化以提高质量。该数据集显著提升了多模态大语言模型(MLLMs)在医学领域的多模态能力。数据集包含1.3百万个医学VQA,分为Alignment VQA和Instruction Tuning VQA两部分。
PubMedVision是一个大规模的医学视觉问答(VQA)数据集。我们从PubMed中提取了高质量的图像-文本对,并使用GPT-4V对其进行重新格式化以提高质量。该数据集显著提升了多模态大语言模型(MLLMs)在医学领域的多模态能力。数据集包含1.3百万个医学VQA,分为Alignment VQA和Instruction Tuning VQA两部分。
提供机构:
FreedomIntelligence
原始信息汇总
PubMedVision 数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别:
- 问答
- 文本生成
- 语言: 英语
- 标签:
- GPT-4V
- Vision
- medical
- biology
- 数据规模: 1M<n<10M
配置
- PubMedVision_Alignment_VQA:
- 数据文件:
PubMedVision_Alignment_VQA.json
- 数据文件:
- PubMedVision_InstructionTuning_VQA:
- 数据文件:
PubMedVision_InstructionTuning_VQA.json
- 数据文件:
数据集描述
- PubMedVision 是一个大规模的医学视觉问答(VQA)数据集。
- 从PubMed中提取高质量的图像-文本对,并使用GPT-4V进行重新格式化以提高质量。
- 该数据集显著提升了医学领域多模态大语言模型(MLLMs)的能力。
数据量
- PubMedVision_Alignment_VQA: 647,031
- PubMedVision_InstructionTuning_VQA: 647,031
- 总计: 1,294,062
图像数据
images_*.zip包含压缩的图像数据。- 可以使用以下代码解压缩图像: bash for ((i=0; i<20; i++)) do unzip -j images_$i.zip -d images/ & # 耐心等待,解压需要一些时间... done
引用
-
如果使用该数据集,请引用以下文献:
@misc{chen2024huatuogptvisioninjectingmedicalvisual, title={HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale}, author={Junying Chen and Ruyi Ouyang and Anningzhe Gao and Shunian Chen and Guiming Hardy Chen and Xidong Wang and Ruifei Zhang and Zhenyang Cai and Ke Ji and Guangjun Yu and Xiang Wan and Benyou Wang}, year={2024}, eprint={2406.19280}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2406.19280}, }
搜集汇总
数据集介绍
构建方式
PubMedVision数据集的构建,是通过从PubMed中提取高质量的图像-文本对,并利用GPT-4V对这些对进行重构以提升其质量。该数据集包含两种类型的VQA数据,即对齐VQA和指令微调VQA,均由超过647,000条医疗视觉问答组成,总计1,294,062条数据。
使用方法
在使用PubMedVision数据集时,用户可以从提供的配置中选择,如PubMedVision_Alignment_VQA、PubMedVision_InstructionTuning_VQA等。数据集压缩的图像数据可以通过提供的bash命令进行解压,以便于在模型训练或评估中使用。同时,数据集的Apache-2.0许可协议为研究者提供了宽松的使用条款。
背景与挑战
背景概述
在医学领域,多模态信息的融合与分析是提升机器学习模型智能水平的关键。PubMedVision数据集,创建于2024年,由深圳大数据研究院与香港中文大学(深圳)的研究团队共同研发,旨在通过提取PubMed中的高质量图像-文本对,并利用GPT-4V进行格式化处理,以提高多模态语言模型的医学多模态能力。该数据集包含129万4千6百62个医学视觉问答实例,其研究背景与核心问题聚焦于如何将医学视觉知识注入大规模的多模态语言模型中,对医学信息处理领域产生了显著影响。
当前挑战
PubMedVision数据集在构建过程中面临了诸多挑战,其中包括如何确保从PubMed中提取的图像-文本对的质量,以及如何通过适当的技术手段将医学视觉知识有效融合进语言模型中。此外,数据集在解决医学视觉问答领域问题方面,也面临着如何提高模型对医学专业术语的理解能力,以及如何在保证数据隐私和合规的前提下,实现数据的最大化利用等挑战。
常用场景
经典使用场景
在医学视觉问答的领域内,PubMedVision数据集因其庞大的规模与高质量的图像-文本对而成为研究者的首选。该数据集通过GPT-4V的再格式化,使得多模态语言模型在处理医学图像相关的问题时,能够展现出更为卓越的性能。
解决学术问题
该数据集的构建解决了医学领域内,多模态语言模型在处理视觉信息时的能力不足问题。它为研究者提供了一个强大的工具,用以提升模型在理解医学图像内容并进行准确问答的能力,对医学信息学的进步具有深远的意义。
实际应用
在实际应用中,PubMedVision数据集可以被用于开发辅助诊断系统,帮助医疗专业人员更快速地解读医学图像,以及提高医学研究的效率。此外,它还可以被整合入医学教育平台,为学生提供丰富的学习资源。
数据集最近研究
最新研究方向
在医学视觉问答领域,PubMedVision数据集的推出标志着大规模医疗VQA数据集的新进展。近期研究聚焦于利用该数据集提升多模态语言模型在医学图像理解与文本交互方面的能力,尤其是通过GPT-4V模型对PubMed中的图像文本对进行重构,以增强数据质量。PubMedVision数据集不仅丰富了医学多模态学习的资源库,也为HuatuoGPT-Vision-7B等模型的发展提供了坚实基础,推动了医学视觉知识在多模态LLM中的融合与应用。
以上内容由遇见数据集搜集并总结生成


