ColorConceptBench
收藏Hugging Face2026-05-08 更新2026-05-09 收录
下载链接:
https://huggingface.co/datasets/ColorConceptBench/ColorConceptBench
下载链接
链接失效反馈官方服务:
资源简介:
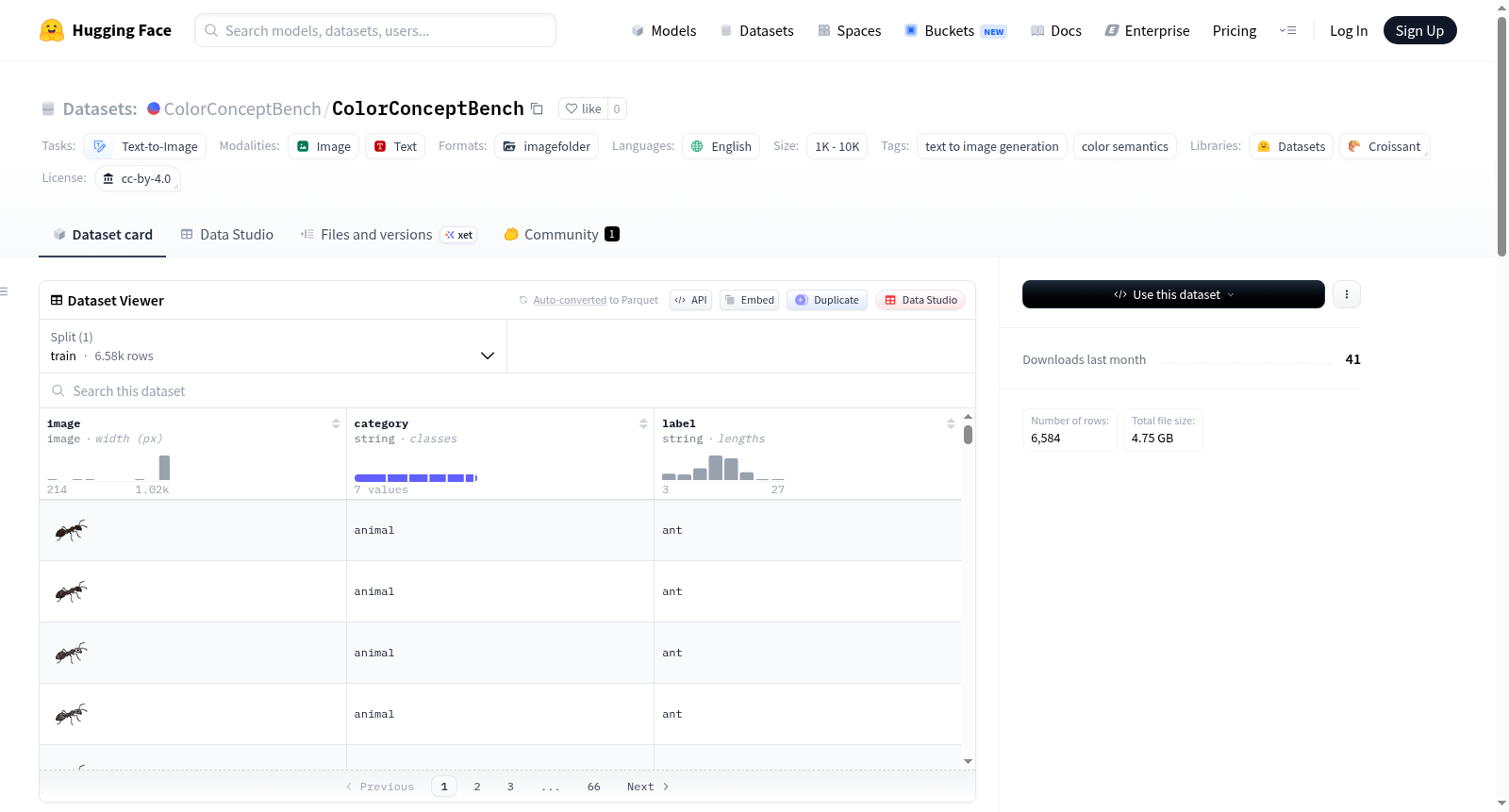
ColorConceptBench 是一个专家标注的基准数据集,旨在系统评估文本到图像(T2I)模型在颜色概念关联方面的能力。该数据集超越了显式颜色规范,通过概率颜色分布研究了模型如何解释 1,281 个隐式颜色概念,这些概念基于 6,584 个人类标注。数据集包含多个语义类别(如动物、建筑、食物、水果、景观、植物、蔬菜),每个类别下有不同数量的标签。每个概念分为三种定义类型:原始(基础名词)、视觉状态(基础名词加客观物理修饰符)和情感(基础名词加情感修饰符)。该数据集还提出了一个概率评估协议,包括概率性和确定性特征对齐,为未来研究提供了细粒度的框架。通过对九种领先 T2I 模型的系统评估,发现当前模型对隐式语义的敏感性不足,这一局限性即使在推理时应用无分类器引导缩放仍然存在。数据集采用 CC BY 4.0 许可。
ColorConceptBench is an expert-annotated benchmark dataset designed to systematically evaluate the capabilities of text-to-image (T2I) models in color-concept association. The dataset goes beyond explicit color specifications by studying how models interpret 1,281 implicit color concepts through probabilistic color distributions, based on 6,584 human annotations. It includes multiple semantic categories (e.g., animals, buildings, food, fruits, landscapes, plants, vegetables), each with varying numbers of labels. Each concept is divided into three definition types: original (basic nouns), visual state (basic nouns plus objective physical modifiers), and emotional (basic nouns plus emotional modifiers). The dataset also proposes a probabilistic evaluation protocol, including probabilistic and deterministic feature alignment, providing a fine-grained framework for future research. A systematic evaluation of nine leading T2I models revealed that current models lack sufficient sensitivity to implicit semantics, a limitation that persists even when applying classifier-free guidance scaling during inference. The dataset is licensed under CC BY 4.0.
创建时间:
2026-05-06
原始信息汇总
ColorConceptBench 数据集概述
基本信息
- 许可证:CC BY 4.0
- 任务类型:文本到图像生成
- 语言:英语
- 标签:文本到图像生成、颜色语义
数据集简介
ColorConceptBench 是一个由专家标注的基准数据集,用于系统评估文本到图像(T2I)模型在颜色-概念关联方面的能力。该数据集通过概率颜色分布,评估模型对 1,281 个隐含颜色概念的理解,这些概念基于 6,584 个人工标注。
关键贡献
- 人类标注的颜色-概念关联基准:首个基于专业设计师标注的大规模基准,包含 1,281 个颜色概念的 6,584 个草图着色,用于量化 AI 生成颜色与人类颜色概念理解之间的概率差距。
- 概率评估协议:建立了包含概率和确定性特征对齐的评估协议,为提升语义颜色可控性提供框架。
- 系统评估与洞察:对主流 T2I 模型在不同概念、风格和引导尺度下进行了全面评估,揭示当前模型对隐含语义缺乏敏感性,且该局限在更强引导下仍难以克服。
数据集类别与规模
| 类别 | 标签数量 |
|---|---|
| animal | 40 |
| building | 221 |
| food | 182 |
| fruit | 210 |
| landscape | 339 |
| plant | 99 |
| vegetables | 190 |
概念定义方式
每个概念包含三种变体:
- 原始:基础名词(如
apple、forest) - 视觉状态:基础名词 + 客观物理修饰语(如
rotten apple、misty forest) - 情感:基础名词 + 情感修饰语(如
lonely cabin、terrifying ocean)
搜集汇总
数据集介绍
构建方式
ColorConceptBench的构建根植于专业设计师的细致标注,通过收集6,584份手绘色彩方案,覆盖了横跨动物、建筑、食物、水果、风景、植物及蔬菜七大类别的1,281个隐式色彩概念。每个概念被精心设计为三种变体:原始基准名词、视觉状态(即附加客观物理修饰词,如“腐烂的苹果”)以及情感状态(即附加情感修饰词,如“孤独的小屋”)。这种多维度的构建策略旨在系统性地探测量化人类对色彩与概念关联的直觉理解,为评估模型提供了丰富且扎实的参照基准。
使用方法
ColorConceptBench专为文本到图像生成模型的设计者与研究者打造。使用者可基于数据集提供的1,281个隐式概念及其人类标注的色彩分布,设计对比实验:通过将模型生成的图像色彩分布与数据集中的人类标注进行概率性对齐评估,量化模型在不同概念类型(特别是原始、视觉状态与情感三类)上的表现。建议结合分类器自由引导等推理策略进行消融研究,以深入分析模型对隐式语义的响应机制,推动更符合人类色彩认知的生成模型发展。
背景与挑战
背景概述
文本到图像生成模型近年来取得了显著进展,能够从文本描述中生成高质量图像。然而,模型对颜色与概念之间关联的理解仍主要局限于显式颜色名称或代码,对情感和视觉状态等隐含概念的把握尚不充分。为解决这一研究空白,ColorConceptBench基准数据集应运而生。该数据集由领域专家创建,基于6,584条人工标注,系统评估了1,281个隐含颜色概念的概率性颜色分布。通过评估九种主流文本到图像生成模型,研究表明模型在不同语义类别上的表现差异显著,且对抽象语义缺乏敏感性。这一成果为理解模型颜色概念学习提供了重要参考,对提升文本到图像生成模型的语义可控性具有深远影响。
当前挑战
ColorConceptBench所解决的核心挑战在于文本到图像生成模型对隐含颜色概念理解的不足。现有模型虽能处理显式颜色描述,却难以捕捉情感(如“孤独的小屋”)和视觉状态(如“腐烂的苹果”)等隐含语义所对应的颜色分布。在构建过程中,研究者面临两大挑战:一是需要设计涵盖多元语义类别(包括动物、建筑、食物等七大领域)的隐含概念集合,确保标注的广泛性和代表性;二是建立概率性评估框架,量化模型生成颜色分布与人类认知之间的差距。此外,模型即使在推理时采用无分类器引导缩放,仍对抽象语义不敏感,揭示当前范式在表示隐含语义上的根本性局限。
常用场景
经典使用场景
在文本到图像生成领域,ColorConceptBench被广泛用于评估模型对颜色与概念之间关联的理解能力。该基准测试通过概率化颜色分布,系统性地考察模型如何处理1281个隐含颜色概念,涵盖动物、建筑、食物、水果、景观、植物和蔬菜等七大语义类别。研究者利用其中包含视觉状态和情感修饰的概念样本,检验生成图像在色彩表现上是否与人类标注一致,从而揭示当前模型在处理抽象语义时的局限性。
解决学术问题
ColorConceptBench有效解决了文本到图像生成中模型对隐含语义色彩理解不足的学术难题。传统评估方法多聚焦于显式颜色名称或代码的匹配,而忽视了情感和视觉状态等抽象概念对颜色分布的影响。该基准通过引入6584条人类标注,构建了概率化的评估协议,量化了AI生成色彩与人类认知之间的差距,推动了模型从简单颜色匹配向深层语义理解的演进,为提升色彩可控性提供了理论依据。
实际应用
在实际应用中,ColorConceptBench为设计师、艺术家和内容创作者提供了评估生成图像色彩准确性的工具。例如,当生成‘孤独的小屋’或‘阴森的海洋’等带有情感色彩的图像时,该基准可检验模型是否捕捉到微妙色调变化。它还用于优化广告创意、虚拟场景构建和游戏美术设计中的色彩渲染,确保AI生成的视觉内容符合人类审美预期,提升人机交互的自然度。
数据集最近研究
最新研究方向
ColorConceptBench的提出标志着文本到图像生成领域对隐式语义色彩的评估迈入系统化阶段。当前前沿研究聚焦于破解模型在抽象概念(如情绪与视觉状态)与色彩关联中的感知失灵问题——尽管主流T2I模型已能精准还原显式颜色指令,但在处理‘腐烂苹果’或‘孤寂小屋’这类蕴含情感与物理修饰的隐式概念时,其色彩映射仍与人类审美直觉存在显著鸿沟。该基准通过6,584份专家标注的色彩概率分布,首次量化了九类前沿模型在动物、建筑等七个语义类别上的表现差异,揭示出模型对抽象语义敏感度的结构性匮乏。这一发现直接挑战了现有无分类器引导缩放技术的有效性,促使研究者重新审视模型在隐式语义表征上的学习范式,为提升可控生成中色彩语义的拟人性提供了关键评估工具。
以上内容由遇见数据集搜集并总结生成


