adsabs/WIESP2022-NER
收藏Hugging Face2023-05-17 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/adsabs/WIESP2022-NER
下载链接
链接失效反馈官方服务:
资源简介:
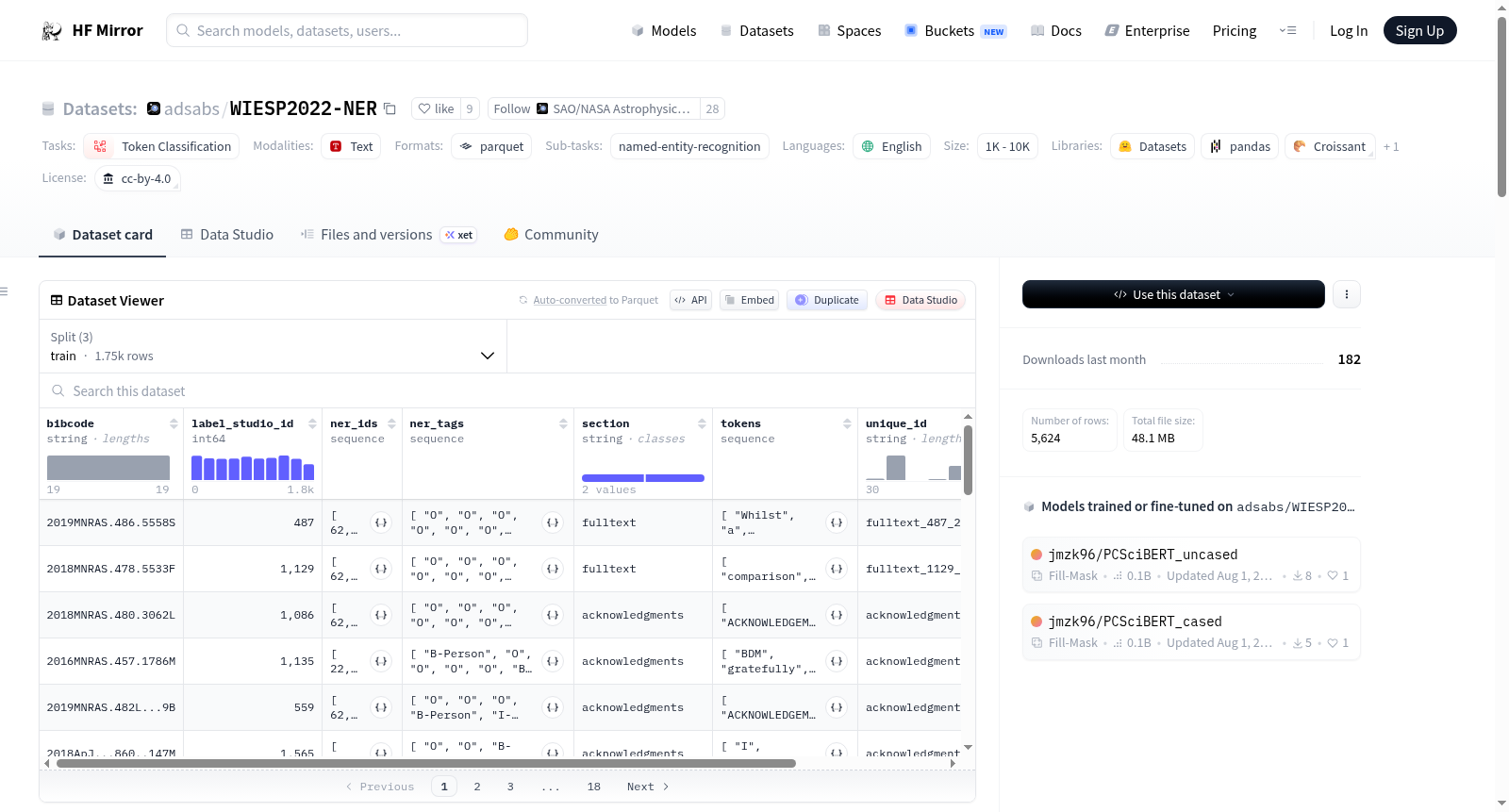
WIESP2022-NER数据集包含来自天体物理学论文的文本片段,由NASA天体物理数据系统提供,并手动标记了天文设施和其他感兴趣的实体(如天体)。数据集采用JSON Lines格式,每个条目是一个JSON字典,包含唯一标识符、标记列表和NER标签列表。数据集用于命名实体识别任务,标签遵循IOB2语法。
The WIESP2022-NER dataset, provided by the NASA Astrophysics Data System, contains text excerpts from astrophysical papers and has been manually annotated with astronomical facilities and other entities of interest (e.g., celestial bodies). The dataset is in JSON Lines format, where each entry is a JSON dictionary containing a unique identifier, a token list, and an NER tag list. This dataset is intended for named entity recognition (NER) tasks, and the tags follow the IOB2 tagging scheme.
提供机构:
adsabs
原始信息汇总
数据集概述
基本信息
- 名称: WIESP2022-NER
- 语言: 英语(en)
- 许可证: CC-BY-4.0
- 多语言性: 单语种
- 大小: 1K<n<10K
数据集创建
- 标注创建者: 专家生成
- 语言创建者: 发现
任务相关
- 任务类别: 令牌分类
- 任务ID: 命名实体识别
数据格式
- 文件格式: JSON Lines
- 数据结构: 每个条目包含
unique_id,tokens,ner_tags等键
数据内容
- 来源: 来自天体物理学论文的文本片段,由NASA天体物理数据系统提供,手动标注了天文设施和其他感兴趣的实体(如天体对象)
文件列表
- 训练数据: WIESP2022-NER-TRAINING.jsonl (1753样本)
- 开发数据: WIESP2022-NER-DEV.jsonl (20样本)
- 验证数据: WIESP2022-NER-VALIDATION-NO-LABELS.jsonl (1366样本) 和 WIESP2022-NER-VALIDATION.jsonl (1366样本)
- 测试数据: WIESP2022-NER-TESTING-NO-LABELS.jsonl (2505样本) 和 WIESP2022-NER-TESTING.jsonl (2505样本)
- 示例预测: WIESP2022-NER-DEV-sample-predictions.jsonl
- 标签定义: tag_definitions.md
- 评分脚本: 包含在
scoring-scripts/目录中,如compute_MCC.py和compute_seqeval.py
引用信息
- 论文: Overview of the First Shared Task on Detecting Entities in the Astrophysics Literature (DEAL) (Grezes et al., WIESP 2022)
- 引用格式: python @inproceedings{grezes-etal-2022-overview, title = "Overview of the First Shared Task on Detecting Entities in the Astrophysics Literature ({DEAL})", author = "Grezes, Felix and Blanco-Cuaresma, Sergi and Allen, Thomas and Ghosal, Tirthankar", booktitle = "Proceedings of the first Workshop on Information Extraction from Scientific Publications", month = "nov", year = "2022", address = "Online", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2022.wiesp-1.1", pages = "1--7", abstract = "..." }
搜集汇总
数据集介绍
构建方式
在科学文献信息抽取领域,WIESP2022-NER数据集依托NASA天体物理数据系统,从天体物理学论文中精选文本片段构建而成。该数据集由专家人工标注,聚焦于天文设施及天体对象等关键实体,采用JSON Lines格式存储,每条记录包含唯一标识符、词汇序列及符合IOB2标注规范的命名实体识别标签,确保了数据结构的一致性与标注的权威性。
特点
该数据集专为天体物理学文献的实体检测任务设计,其标注体系精细覆盖了天文设施、天体对象等多类实体,具备明确的领域特异性。数据规模适中,包含训练、开发与验证多个子集,并提供了无标签测试集以支持模型评估。其格式与CONLL2003兼容,便于直接适配主流自然语言处理工具,为领域内实体识别研究提供了标准化基准。
使用方法
使用者可通过Hugging Face库直接加载数据集,或从本地JSONL文件导入。模型预测需按照规范格式提交,包含原始标识符、词汇序列及预测标签。评估过程依托配套脚本计算马修斯相关系数与序列标注指标,支持对模型性能进行多维度量化分析。该数据集适用于训练与评估命名实体识别模型,尤其服务于天体物理学文本的信息抽取研究。
背景与挑战
背景概述
在科学文献信息抽取领域,天体物理学文献蕴含丰富的专业实体,如天文设施与天体对象,其自动化识别对构建知识库与增强文献检索至关重要。2022年,NASA天体物理数据系统联合相关研究机构,于首届科学出版物信息抽取研讨会上推出了WIESP2022-NER数据集,旨在推动天体物理学文本的命名实体识别研究。该数据集由专家人工标注,涵盖数千个文本片段,采用IOB2格式标注,为核心任务DEAL提供了基准资源,促进了学术社区对专业领域实体抽取技术的探索与优化。
当前挑战
该数据集致力于解决天体物理学文献中命名实体识别的独特挑战,包括专业术语的歧义性、实体边界的模糊性以及领域知识的依赖性,这些因素使得传统自然语言处理模型难以准确捕捉实体上下文。在构建过程中,挑战主要源于专家标注的高成本与一致性要求,以及从非结构化科学文本中提取并标准化实体标签的复杂性,需平衡标注质量与数据规模,确保标注体系能全面覆盖天体物理学的多样实体类别。
常用场景
经典使用场景
在科学文献信息提取领域,WIESP2022-NER数据集为命名实体识别任务提供了专门的天体物理学文本语料。其经典应用场景在于训练和评估机器学习模型,以自动识别天文设施、天体对象等专业实体。通过采用IOB2标注格式,该数据集支持序列标注模型的精细化学习,为天体物理学文献的结构化信息抽取奠定基础。
衍生相关工作
围绕WIESP2022-NER数据集,衍生出多项经典研究工作。例如,在WIESP2022研讨会上举办的DEAL共享任务,吸引了多支团队参与开发实体识别系统。这些工作探索了基于Transformer的预训练模型在天体物理文本上的适应性,以及领域特定词嵌入的有效性,进一步推动了科学文献信息提取技术的发展与优化。
数据集最近研究
最新研究方向
在科学文献信息抽取领域,WIESP2022-NER数据集作为天体物理学文献命名实体识别的基准资源,正推动前沿研究向跨学科知识图谱构建与多模态融合分析拓展。该数据集源自NASA天体物理数据系统,其标注的天文设施与天体实体为领域自适应与少样本学习提供了关键语料,促进了预训练语言模型在专业科学文本上的微调优化。近期研究热点集中于利用该数据集开发端到端实体链接系统,以增强科学文献的自动化索引与元数据生成能力,进而支撑大规模学术知识库的智能检索与语义推理应用,对加速天体物理学领域的知识发现与信息整合具有深远意义。
以上内容由遇见数据集搜集并总结生成


