atgarcia/EMGSoundTrain1
收藏Hugging Face2024-03-25 更新2024-06-11 收录
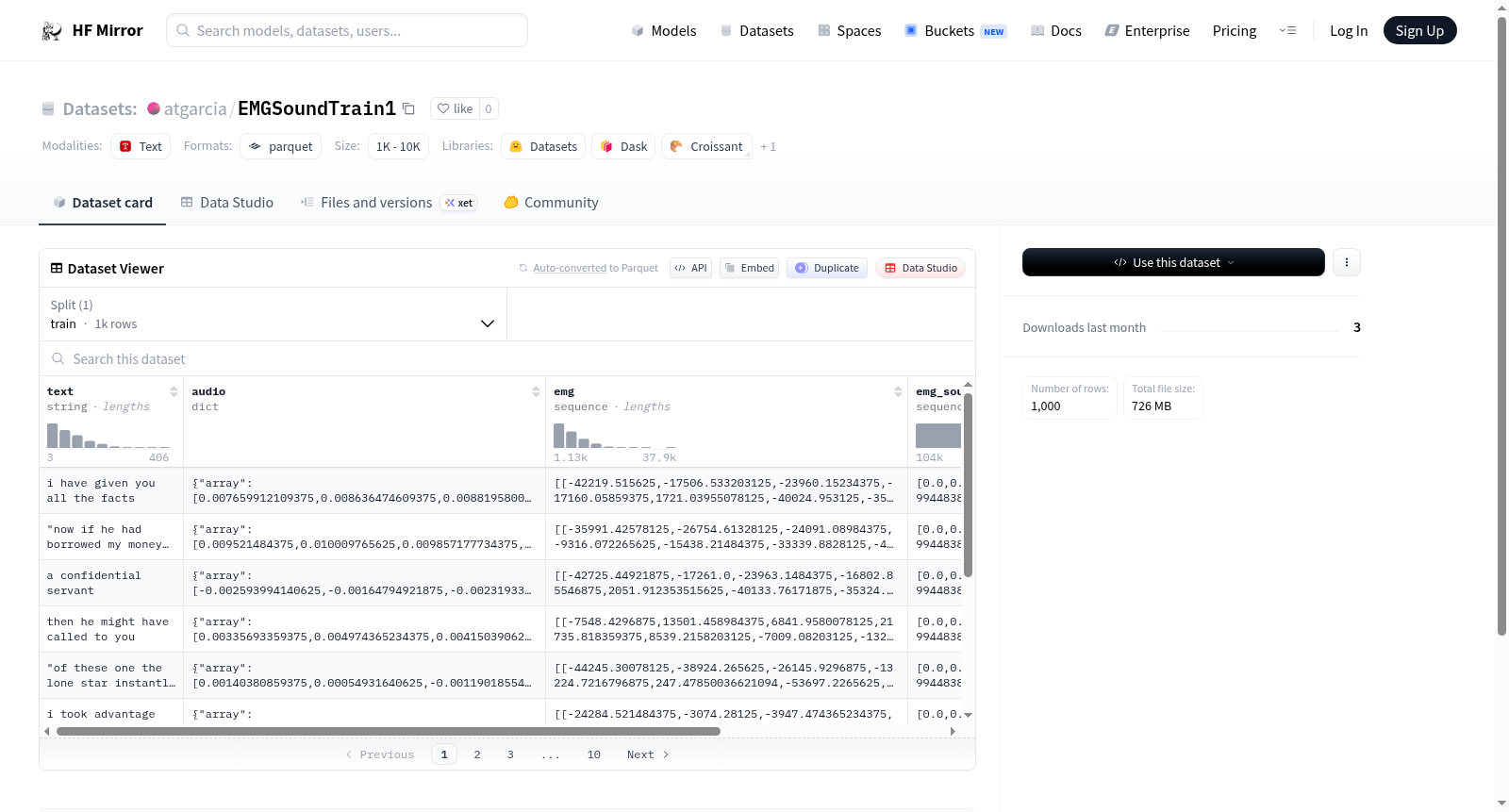
下载链接:
https://hf-mirror.com/datasets/atgarcia/EMGSoundTrain1
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: text
dtype: string
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: emg
sequence:
sequence: float64
- name: emg_sound
sequence: float64
splits:
- name: train
num_bytes: 2167603794
num_examples: 1000
download_size: 726445609
dataset_size: 2167603794
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
数据集信息:
特征项:
- 名称:text,数据类型:字符串
- 名称:audio,为结构体类型,包含子字段:
- array:序列类型,元素为64位浮点数
- path:数据类型:字符串,用于存储文件路径
- sampling_rate:数据类型:64位整型,即采样率
- 名称:emg:为嵌套序列类型,元素为64位浮点数的序列(二维浮点序列)
- 名称:emg_sound:为64位浮点数的序列类型
数据集划分:
- 划分名称:train(训练集),占用字节数:2167603794,样本总数:1000
下载总大小:726445609
数据集总存储大小:2167603794
数据集配置:
- 配置名称:default(默认配置),数据文件配置:
- 针对训练划分:数据文件路径为 data/train-*
提供机构:
atgarcia
原始信息汇总
数据集概述
数据集特征
- text: 数据类型为字符串。
- audio: 结构化数据,包含以下子特征:
- array: 序列数据类型为浮点数64位。
- path: 数据类型为字符串。
- sampling_rate: 数据类型为整数64位。
- emg: 序列数据类型为浮点数64位。
- emg_sound: 序列数据类型为浮点数64位。
数据集划分
- train: 包含1000个样本,数据集大小为2167603794字节。
数据集大小
- 下载大小: 726445609字节。
- 数据集总大小: 2167603794字节。
配置
- default: 训练数据文件路径为
data/train-*。
搜集汇总
数据集介绍
构建方式
在生物信号处理与听觉感知交叉领域,EMGSoundTrain1数据集的构建体现了多模态数据采集的前沿方法。该数据集通过同步记录肌电图信号与对应的音频数据,构建了包含1000个样本的训练集。每个样本均整合了文本描述、原始音频波形、肌电信号序列以及经过处理的肌电声音特征,数据以结构化格式存储,确保了信号的时间对齐与完整性。构建过程注重数据的多样性与代表性,为跨模态学习提供了坚实基础。
特点
EMGSoundTrain1数据集的核心特点在于其多模态融合与高维度特征表达。数据集囊括了文本、音频及肌电信号三类异构数据,其中肌电信号以序列形式呈现,捕捉了肌肉活动的动态细节。音频数据包含原始波形与采样率信息,而肌电声音特征则提供了信号转换后的声学表征。这种多维度的数据组织方式,不仅支持传统的单模态分析,更为跨模态关联研究开辟了新的路径,适用于探索生理信号与声音之间的复杂映射关系。
使用方法
利用EMGSoundTrain1数据集进行研究时,可基于其多模态特性设计丰富的实验方案。研究者可通过加载数据集中的训练分割,直接访问文本、音频及肌电信号字段,进行特征提取与对齐分析。该数据集适用于机器学习模型的训练,特别是在跨模态生成、信号分类或回归任务中,能够通过肌电信号预测声学特征或反之。数据以标准格式存储,兼容主流深度学习框架,便于实现端到端的模型构建与评估。
背景与挑战
背景概述
在生物医学信号处理与跨模态学习领域,肌电图(EMG)与声音信号的同步采集与分析,为无创人机交互与康复工程开辟了新路径。数据集atgarcia/EMGSoundTrain1由研究人员atgarcia构建,其核心在于探索肌电信号与对应声音之间的映射关系,旨在推动语音合成、辅助通信及运动功能恢复等应用的发展。该数据集通过整合多模态信息,为跨域特征提取与模型泛化提供了关键数据支撑,对促进神经工程与计算听觉场景分析的交叉研究具有显著影响力。
当前挑战
该数据集致力于解决肌电信号到声音转换这一跨模态生成问题的挑战,其难点在于肌电信号的噪声干扰大、个体差异显著,且与声音间的非线性映射关系复杂,模型需在有限样本下实现高保真重建。在构建过程中,挑战集中于多传感器数据的精确同步采集、信号预处理中的伪影去除,以及跨模态对齐的标注一致性维护,这些因素共同增加了数据质量控制的难度。
常用场景
经典使用场景
在生物信号处理与跨模态学习领域,EMGSoundTrain1数据集为肌电信号(EMG)与音频信号的联合分析提供了关键资源。该数据集通过同步采集肌电信号及其对应的声音信号,构建了多模态数据对,典型应用于跨模态生成与识别任务。研究者可利用该数据集训练模型,实现从肌电信号到声音信号的直接映射,探索人体肌肉活动与发声机制之间的内在关联,为无声语音合成或辅助通信技术奠定基础。
实际应用
在实际应用层面,EMGSoundTrain1数据集可服务于医疗康复与智能人机交互领域。例如,在言语障碍患者的辅助沟通系统中,基于肌电信号的声音合成技术能够帮助用户通过肌肉活动生成语音,提升生活自主性。同时,该数据集也可用于开发无声语音识别系统,在嘈杂环境或保密场景下实现可靠的命令控制,为特种作业或残疾人土提供创新的交互解决方案。
衍生相关工作
围绕EMGSoundTrain1数据集,已衍生出多项经典研究工作,主要集中在跨模态生成与生物信号处理方向。例如,基于该数据集的生成对抗网络(GAN)模型被用于肌电信号到音频的高保真转换,提升了合成语音的自然度;此外,时序卷积网络(TCN)与注意力机制的结合,优化了信号对齐的精度,推动了无声语音识别算法的进步。这些工作不仅丰富了多模态学习的理论框架,也为实际应用提供了技术原型。
以上内容由遇见数据集搜集并总结生成


