sapiens-technology/enem_2025
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/sapiens-technology/enem_2025
下载链接
链接失效反馈官方服务:
资源简介:
ENEM 2025数据集是从2025年巴西国家高中考试(ENEM)中提取的问答对集合,旨在评估和提高大型语言模型在巴西葡萄牙语中的推理、阅读理解和多项选择答题能力。该数据集涵盖自然科学、人文科学、数学、语言和常识等多个领域。每个样本包含一个葡萄牙语的情境化多项选择题和正确答案。该数据集特别适合评估现实世界的学术推理、构建智能辅导系统以及在pt-BR语境下评估多语言模型,同时保留了标准化教育评估的结构和复杂性。
ENEM 2025 Dataset is a curated collection of question-answer pairs derived from the 2025 edition of the Brazilian National High School Exam (ENEM), designed to evaluate and improve the reasoning, reading comprehension, and multiple-choice answering capabilities of large language models in Brazilian Portuguese. The dataset spans multiple domains including natural sciences, human sciences, mathematics, languages, and general knowledge. Each sample follows a structured format composed of an input containing a contextualized multiple-choice question in Portuguese and an output representing the correct answer. This dataset is particularly suited for assessing real-world academic reasoning, building intelligent tutoring systems, and evaluating multilingual models in pt-BR contexts, while preserving the structure and complexity of standardized educational assessments.
提供机构:
sapiens-technology
搜集汇总
数据集介绍
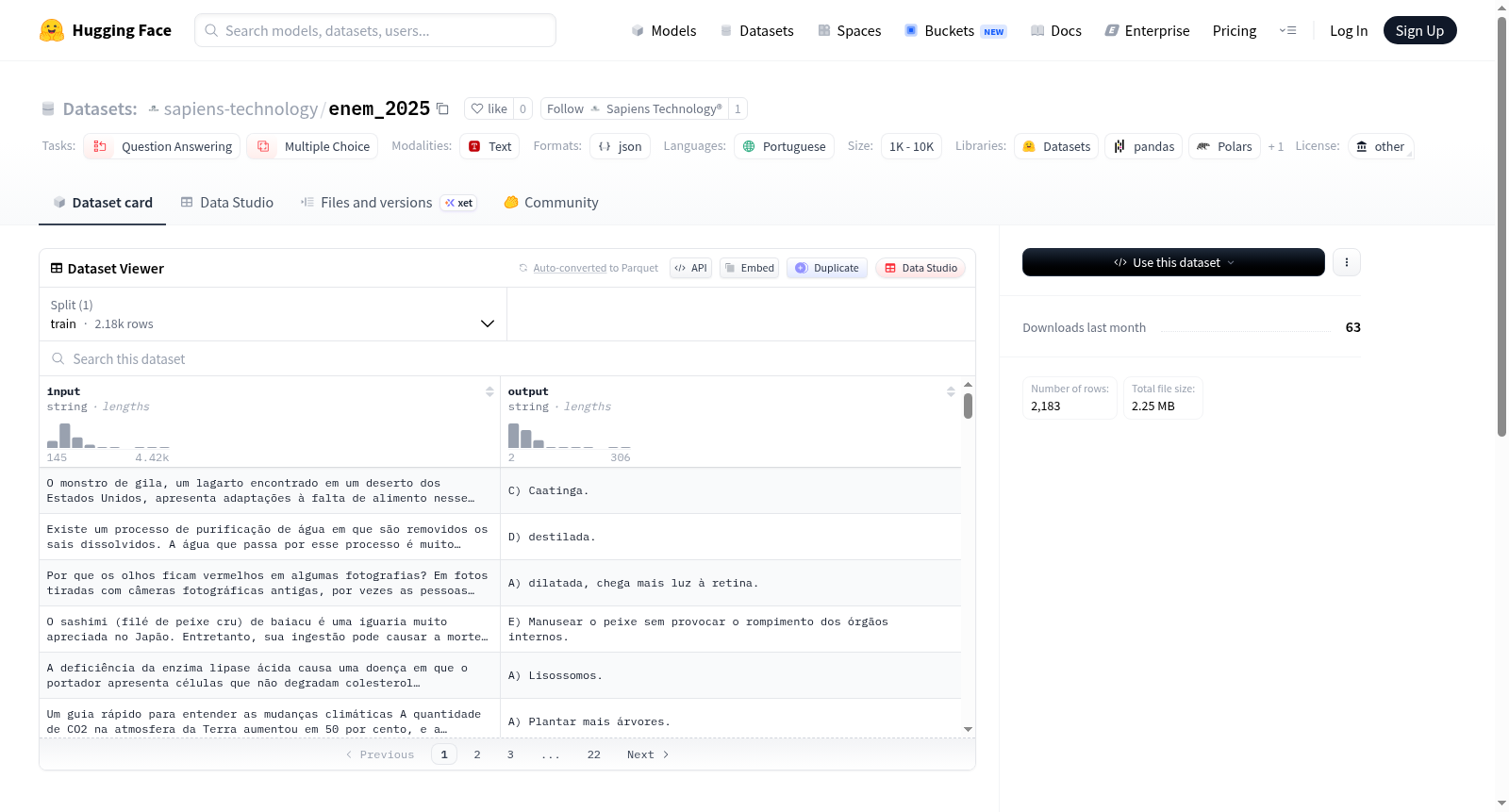
构建方式
ENEM 2025数据集基于巴西最具影响力的全国统一高中考试——ENEM 2025年度试卷构建而成。该数据集精心提取了考试中的问题与答案对,每个样本以结构化格式呈现,包含一段葡萄牙语情境化多项选择题作为输入,以及对应正确答案作为输出。构建过程严格遵循原始考试的学科分布,涵盖了自然科学、人文科学、数学、语言及常识等多个领域,旨在保留学术评估的现实复杂性与多样性。
特点
该数据集作为评估大语言模型在巴西葡萄牙语环境下学术推理能力的标杆,具备高度的现实性与学术性。其特点在于跨学科覆盖广泛,问题设计注重语境理解与逻辑分析,能够全面检验模型的阅读理解和多项选择应答能力。此外,数据集规模适中,适用于一致性基准测试、微调训练及教育AI应用,为构建智能辅导系统提供了可靠资源。
使用方法
研究人员可将ENEM 2025数据集直接用于葡萄牙语大语言模型的基准评估,通过输入情境化多项选择题并比对模型输出与正确答案,衡量其推理与理解水平。该数据集同样适用于模型的微调训练,以增强其在学术推理任务上的表现。此外,开发者可借助此数据集构建智能辅导系统或教育评估工具,推动巴西葡萄牙语场景下AI教育的实际应用。
背景与挑战
背景概述
巴西国家高中考试(ENEM)作为拉丁美洲规模最大的标准化考试之一,其内容涵盖自然科学、人文科学、数学、语言及通用知识等多学科领域,为评估人工智能的学术推理能力提供了天然且复杂的测试场景。ENEM 2025数据集由Sapiens Technology团队于2025年创建,旨在系统性地评估与提升大语言模型在巴西葡萄牙语语境下的阅读理解、多选推理与学术应答能力。该数据集基于2025年ENEM官方试题构建,包含结构化的问答对,每一个样本均结合上下文情景,形成具有真实学术挑战的标准化评估体系。ENEM 2025的发布对于推动葡萄牙语自然语言处理、构建智能教育辅助系统以及检验多语言模型的领域适应性具有重要意义,为低资源语言的高质量评测基准注入了新鲜活力。
当前挑战
ENEM 2025数据集的主要挑战集中在三个方面。首先,所解决的领域问题在于多学科交叉的学术推理:考题跨越物理、化学、历史、地理、文学与数学等广泛范畴,要求模型同时具备语言理解、逻辑推演与领域知识调用能力,这对大模型在葡萄牙语学术语境下的综合表现构成严峻考验。其次,数据集构建过程中的挑战体现在试题结构的复杂性与本地化处理的精准性——需确保每个输入中包含上下文化的问题描述与正确的单选答案格式一致,同时避免翻译或转写带来的语义失真。最后,面对巴西葡萄牙语特有的区域变体、术语表达与修辞风格,如何保证数据的高质量标注与评测的无偏性,也是该基准长期稳定的关键难点。
常用场景
经典使用场景
ENEM 2025数据集作为巴西国家高中教育评估体系的核心载体,被广泛用于评测大语言模型在葡萄牙语学术推理中的综合能力。研究者常将其作为多选题问答基准,通过模型对自然科学、人文科学、数学等多领域情境化问题的作答表现,衡量其文本理解与逻辑推演水平。该数据集的经典使用方式包括零样本推理测试与少样本提示学习,旨在揭示模型应对真实学术情境时的泛化能力与知识迁移潜力。
解决学术问题
该数据集解决了葡萄牙语自然语言处理中高质量学术评估数据匮乏的困境,为跨语言与多模态推理研究提供了标准化基准。它填补了拉丁美洲大型标准化考试在AI评测中的空白,使学术界能够系统研究模型在非英语语境下的知识结构完整性、因果推理一致性及领域间知识协调能力。其结构化问答格式还助力于探索多任务学习中的样本效率与认知负荷分配问题,推动教育评估与人工智能深度融合。
衍生相关工作
基于ENEM 2025数据集,研究者开发了多项衍生工作:包括面向葡萄牙语的学术推理特征提取方法、少样本知识蒸馏框架,以及融合多模态信息的增强型问答模型。部分工作进一步构建了跨年度ENEM对比基准,用于追踪模型在时间维度上的知识更新能力;还有团队结合图神经网络与注意力机制,优化了多选题中选项间语义关系的建模策略。这些工作共同促进了教育领域大语言模型评测体系的完善。
以上内容由遇见数据集搜集并总结生成


