Movie Posters DataSet (MPDS)
收藏arXiv2024-10-22 更新2024-10-24 收录
下载链接:
https://anonymous.4open.science/r/MPDS-373k-BD3B
下载链接
链接失效反馈官方服务:
资源简介:
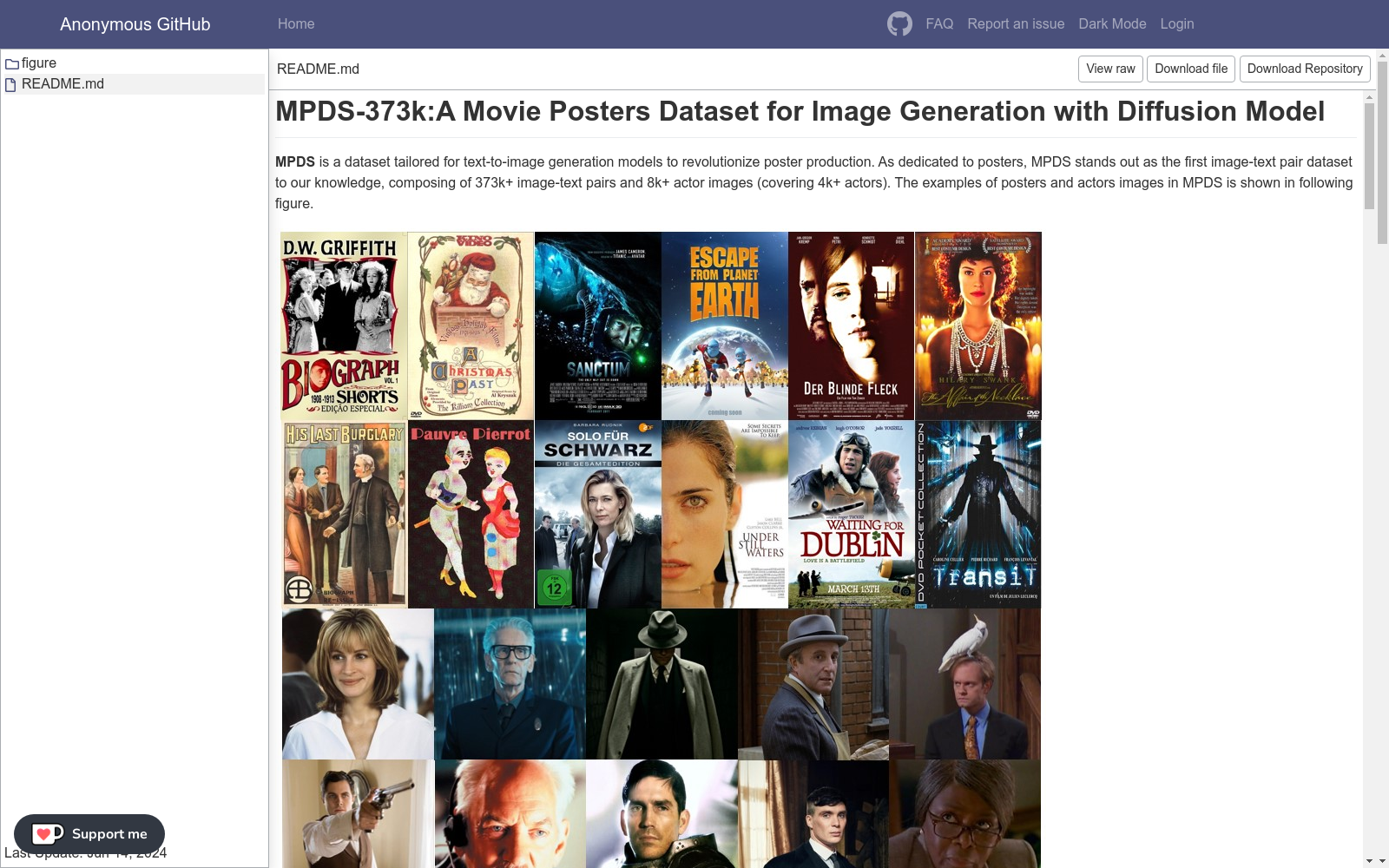
MPDS数据集是由南京理工大学和SeetaCloud合作创建的,专门用于电影海报生成的图像-文本对数据集。该数据集包含超过373,000对图像-文本对和8,000多张演员图像,覆盖了4,000多名演员。数据集的创建过程结合了自动化的视觉语言模型和人工校正,确保了描述的准确性和完整性。MPDS数据集的应用领域主要集中在个性化电影海报生成,旨在通过先进的扩散模型技术提升电影海报的设计效率和质量。
The MPDS dataset is a specialized image-text pair dataset for movie poster generation, co-developed by Nanjing University of Science and Technology and SeetaCloud. It contains over 373,000 image-text pairs, as well as more than 8,000 actor images covering over 4,000 distinct actors. The construction of the dataset integrates automated vision-language models and manual correction, which guarantees the accuracy and completeness of its descriptions. The primary application scenario of the MPDS dataset is personalized movie poster generation, where it aims to enhance the design efficiency and quality of movie posters through advanced diffusion model technologies.
提供机构:
南京理工大学,中国;SeetaCloud,中国
创建时间:
2024-10-22
搜集汇总
数据集介绍
构建方式
MPDS数据集的构建过程始于对电影海报及其相关信息的广泛收集。研究团队从IMDB等权威电影网站获取了超过373,000对图像-文本对和8,000多张演员图像,涵盖了4,000多名演员。这些数据经过精心整理,包括电影标题、类型、演员阵容和剧情简介等详细描述。为了确保数据的高质量和准确性,研究团队采用了半自动化的标注策略,首先使用Blip2模型进行初步标注,随后进行人工校正和整合,从而生成高质量的视觉感知提示和电影剧情提示。
特点
MPDS数据集的显著特点在于其针对电影海报生成模型的专门设计。该数据集不仅包含了丰富的图像-文本对,还引入了演员图像和海报字幕提示,为个性化海报生成提供了多维度的输入条件。此外,MPDS通过对比多条件学习方法,有效提升了生成海报的自然度和一致性。其数据结构的多样性和高质量的标注使其在推动电影海报生成研究方面具有独特的优势。
使用方法
MPDS数据集适用于多种电影海报生成任务,特别是基于扩散模型的文本到图像生成。用户可以通过加载数据集中的图像和文本对,训练和微调扩散模型,以生成高质量的电影海报。数据集中的多条件输入,如海报提示、海报字幕和演员图像,可以显著提升生成海报的个性化和专业性。此外,MPDS还支持基于演员和电影类型的子集划分,便于用户进行特定类型的海报生成研究。
背景与挑战
背景概述
电影海报在电影推广中扮演着不可或缺的角色,吸引观众、提升可见性、传达主题和情感,并影响市场竞争。传统的海报设计过程资源密集且耗时。近年来,基于扩散的图像生成模型(如Ho, Jain, and Abbeel 2020; Song, Meng, and Ermon 2020; Rombach et al. 2022; Saharia et al. 2022; Balaji et al. 2022; Sohl-Dickstein et al. 2015; Yang et al. 2023)的出现,彻底改变了创意领域,使得生成引人注目的视觉内容成为可能。然而,尽管文本到图像扩散模型取得了显著进展,但当前模型在生成令人满意的海报结果方面仍显不足,主要问题在于缺乏专门用于模型训练的海报数据集。为此,我们提出了Movie Posters DataSet (MPDS),旨在为文本到图像生成模型提供专门的海报数据,以革新海报制作。MPDS由373k+图像-文本对和8k+演员图像(涵盖4k+演员)组成,是首个专门为海报设计的图像-文本对数据集。
当前挑战
MPDS在构建过程中面临多个挑战。首先,缺乏专门的海报数据集使得现有模型难以生成符合电影海报美学的高质量图像。其次,手动标注大量海报数据成本高昂且效率低下,为此我们采用了半自动标注策略,结合Blip2进行初步标注,并进行细致的手动修正。此外,海报数据的独特性要求模型能够理解和生成与电影主题紧密相关的视觉内容,这对模型的训练和优化提出了更高的要求。最后,如何确保生成的海报在视觉和文本元素上的一致性和专业性,是MPDS在实际应用中需要解决的关键问题。
常用场景
经典使用场景
在电影产业的推广中,电影海报扮演着不可或缺的角色,其设计直接影响观众的吸引力。MPDS数据集通过提供373k+的图像-文本对和8k+的演员图像,为电影海报的生成提供了丰富的素材。该数据集特别适用于基于扩散模型的文本到图像生成任务,能够显著提升海报设计的效率和创意性。通过结合电影的标题、类型、演员阵容和剧情简介,MPDS能够生成高度个性化和视觉上吸引人的电影海报,从而在电影营销中发挥重要作用。
解决学术问题
MPDS数据集解决了当前文本到图像生成模型在电影海报生成中的不足,主要体现在缺乏专门针对海报设计的训练数据。传统模型在处理海报生成时,往往无法准确理解和再现海报的独特美学和设计元素。MPDS通过提供详细的海报描述和视觉感知提示,帮助模型更好地捕捉和生成符合电影主题和风格的海报,从而推动了个性化电影海报生成技术的发展。
衍生相关工作
基于MPDS数据集,研究者们开发了多种多条件扩散框架,用于电影海报的生成。这些框架通过结合电影剧情提示、视觉感知提示和演员图像,实现了更精细和个性化的海报设计。此外,MPDS还激发了关于视觉语言模型在海报生成中应用的研究,推动了文本到图像生成技术在电影海报领域的深入探索。这些衍生工作不仅提升了海报生成的质量,还为相关领域的研究提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


