mstz/adult
收藏Hugging Face2023-04-15 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/mstz/adult
下载链接
链接失效反馈官方服务:
资源简介:
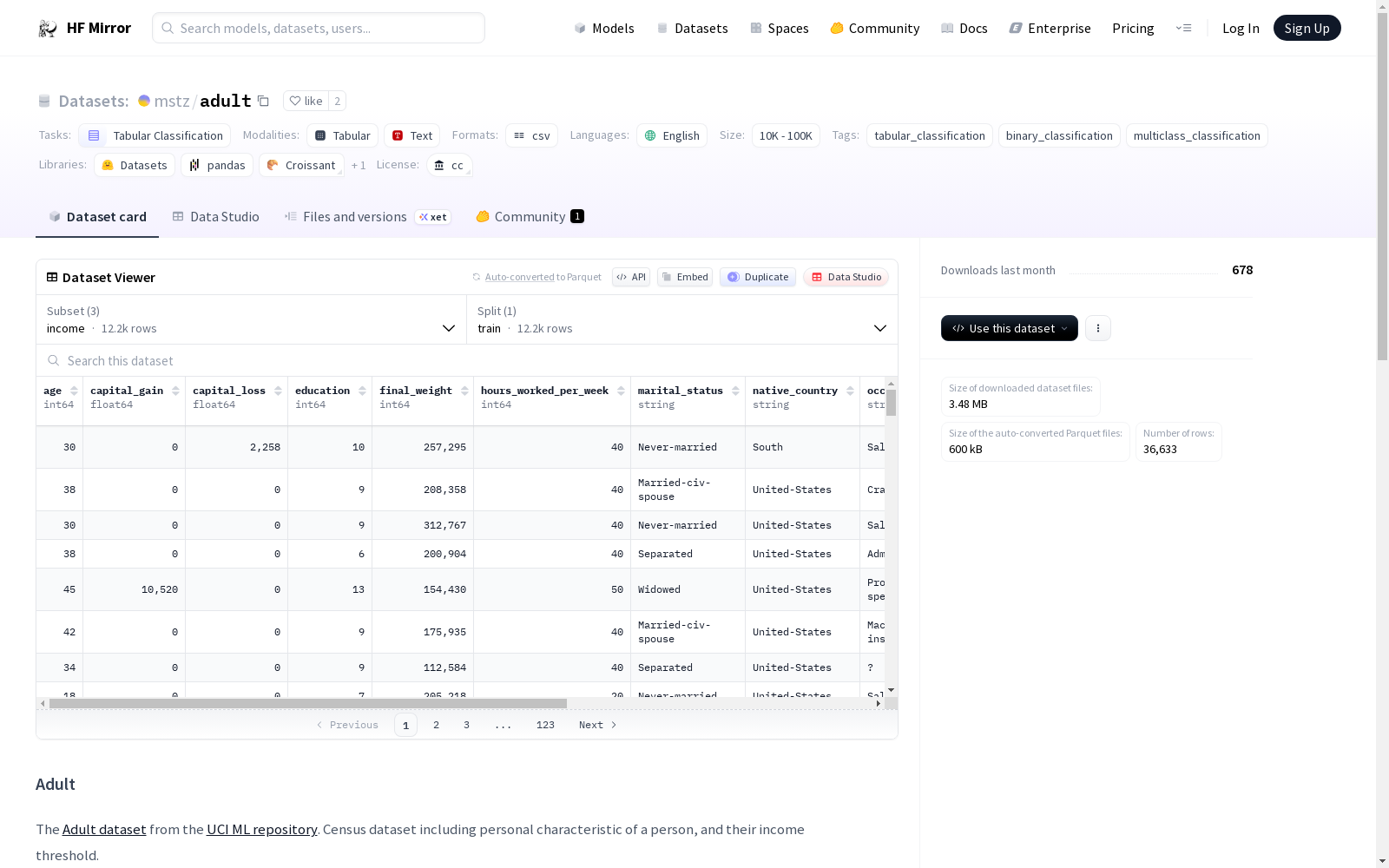
Adult数据集来自UCI机器学习库,包含人口普查数据,记录了个人特征及其收入阈值。数据集支持多种配置和任务,包括二进制分类(收入是否超过阈值)、去除种族特征后的二进制分类以及多类分类(预测种族)。数据集的特征包括年龄、资本收益、资本损失、教育水平、每周工作时间、婚姻状况、原籍国、职业、种族、关系、性别和工作类型等。
Adult数据集来自UCI机器学习库,包含人口普查数据,记录了个人特征及其收入阈值。数据集支持多种配置和任务,包括二进制分类(收入是否超过阈值)、去除种族特征后的二进制分类以及多类分类(预测种族)。数据集的特征包括年龄、资本收益、资本损失、教育水平、每周工作时间、婚姻状况、原籍国、职业、种族、关系、性别和工作类型等。
提供机构:
mstz
原始信息汇总
数据集概述
基本信息
- 名称: Adult
- 语言: 英语
- 标签:
- 成人
- 表格分类
- 二元分类
- 多类分类
- UCI
- 大小类别: 10K<n<100K
- 任务类别: 表格分类
- 配置:
- 编码
- 收入
- 无种族收入
- 种族
- 许可证: cc
数据集描述
- 来源: UCI ML 仓库
- 内容: 包含个人特征及其收入阈值的普查数据集。
配置与任务
| 配置 | 任务 | 描述 |
|---|---|---|
| 编码 | 显示编码特征原始值的编码字典。 | |
| 收入 | 二元分类 | 根据阈值分类个人收入是否超过50k美元。 |
| 无种族收入 | 二元分类 | 类似于“收入”配置,但移除了“种族”特征。 |
| 种族 | 多类分类 | 预测个人的种族。 |
特征
- 目标特征: 根据所选配置变化,始终位于数据集的最后位置。
- 特征列表:
特征 类型 描述 ageint64年龄 capital_gainfloat64个人资本收益 capital_lossfloat64个人资本损失 educationint8教育水平:越高表示教育程度越高 final_weightint64hours_worked_per_weekint64每周工作小时数 marital_statusstring婚姻状况 native_countrystring个人原籍国家 occupationstring个人职业 racestring个人种族 relationshipstringis_malebool性别(男/女) workclassstring个人工作类型 over_thresholdint8收入是否超过50k美元(1表示超过,0表示不超过)
搜集汇总
数据集介绍
构建方式
在人口统计学与机器学习交叉领域,Adult数据集源自加州大学欧文分校机器学习知识库,其构建过程体现了严谨的数据采集与处理原则。该数据集通过整合美国人口普查数据,系统性地收集了个体的社会经济属性与人口特征信息,涵盖年龄、教育程度、职业类别、工作时长等关键变量。数据经过标准化清洗与特征编码处理,形成结构化的表格形式,确保数据质量与一致性,为后续的机器学习任务提供了可靠的基础。
特点
Adult数据集以其多维度的特征设计展现出显著的研究价值,涵盖了从数值型到类别型的多样化变量,包括年龄、资本收益、教育水平、婚姻状况等。数据集特别设计了三种配置模式,分别对应不同的分类任务:收入阈值二分类、剔除种族特征的收入分类以及种族多分类,这种灵活性使得研究者能够针对特定问题调整分析焦点。目标变量始终置于数据末尾,便于模型训练与评估,体现了数据集在实验设计上的巧妙构思。
使用方法
在机器学习实践应用中,Adult数据集可通过HuggingFace的datasets库便捷加载,研究者只需指定相应配置即可获取所需数据子集。例如,调用load_dataset函数并选择'income'配置,即可获得用于收入阈值预测的二分类数据集。数据以表格形式呈现,可直接用于特征工程与模型训练,支持逻辑回归、决策树等多种分类算法。这种标准化的接口设计极大简化了研究流程,促进了数据在公平性分析、社会经济预测等领域的广泛应用。
背景与挑战
背景概述
Adult数据集源于加州大学欧文分校机器学习知识库,自1996年发布以来,已成为社会学与机器学习交叉研究的重要基准。该数据集由美国人口普查局数据衍生,核心研究问题聚焦于通过个体社会经济特征预测其年收入是否超过五万美元阈值,为收入不平等、劳动力市场分析及算法公平性研究提供了实证基础。其多维度的个人属性,如年龄、教育程度、职业类别等,使得该数据集在经济学、公共政策及机器学习领域持续发挥影响力,推动了分类算法与可解释性模型的发展。
当前挑战
Adult数据集所解决的领域问题在于收入预测的二元分类,其挑战体现在社会经济特征的复杂交互与潜在偏见。数据构建过程中,原始普查数据的匿名化处理可能导致信息损失,而类别不平衡与缺失值问题增加了模型训练的难度。更严峻的挑战源于数据中隐含的社会偏见,如种族、性别等敏感属性与收入的相关性,可能加剧算法歧视,促使研究者必须在模型性能与公平性之间寻求平衡。此外,数据的时间局限性使得其难以反映动态变化的社会经济结构,限制了模型的泛化能力。
常用场景
经典使用场景
在机器学习与数据科学领域,Adult数据集作为经典的二分类任务基准,常被用于评估分类算法的性能。该数据集通过个人特征如年龄、教育水平、职业等,预测个体年收入是否超过5万美元阈值。这一场景在学术研究中广泛用于比较逻辑回归、决策树、支持向量机等传统模型的准确性与鲁棒性,为算法优化提供了标准化的测试平台。
衍生相关工作
基于Adult数据集,学术界衍生了一系列经典研究工作。例如,研究者在公平机器学习领域开发了如Adversarial Debiasing等算法,以减少模型对敏感特征的依赖。此外,该数据集也被用于集成学习方法的评估,如随机森林和梯度提升机,推动了分类技术的进步。这些工作不仅丰富了机器学习理论,还为后续的数据集构建和算法设计提供了重要参考。
数据集最近研究
最新研究方向
在人口统计学与机器学习交叉领域,Adult数据集作为经典基准,持续推动着公平性算法与可解释性模型的前沿探索。当前研究聚焦于消除数据中的历史偏见,通过开发去偏置技术,确保收入预测模型在不同种族群体间保持公正性。同时,结合因果推断方法,学者们深入剖析教育水平、职业类型与收入阈值之间的复杂关联,旨在构建更具透明度的决策系统。这些进展不仅回应了社会对算法伦理的关切,也为政策制定提供了数据驱动的科学依据,彰显了负责任人工智能的深远影响。
以上内容由遇见数据集搜集并总结生成


