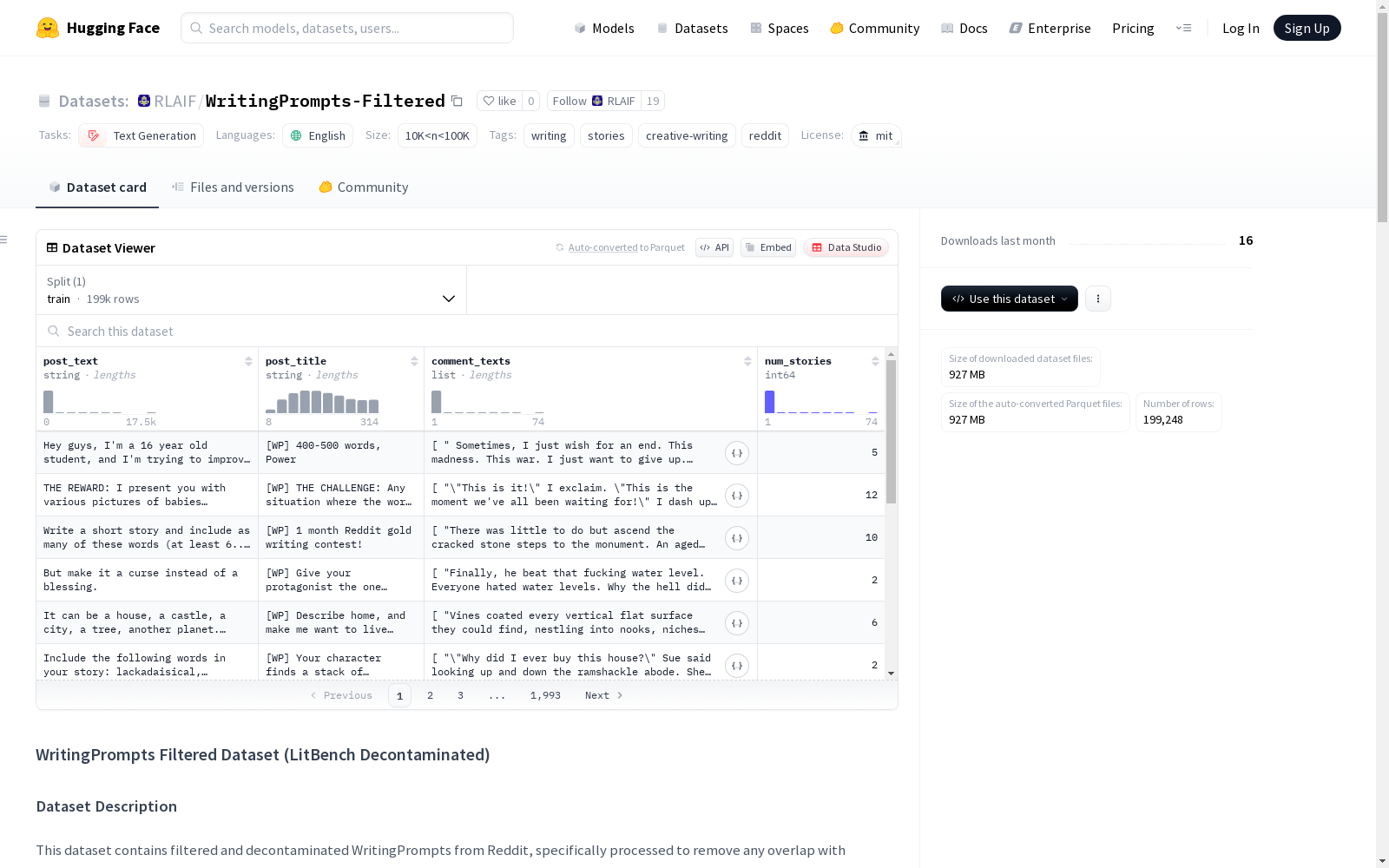
WritingPrompts-Filtered
收藏Hugging Face2025-09-13 更新2025-09-14 收录
下载链接:
https://huggingface.co/datasets/RLAIF/WritingPrompts-Filtered
下载链接
链接失效反馈官方服务:
资源简介:
这个数据集包含了从Reddit上过滤和去污染的WritingPrompts,专门处理以移除与LitBench测试集的重叠内容,确保了用于语言模型训练的数据清洁且无测试集污染。
提供机构:
RLAIF
创建时间:
2025-09-13
原始信息汇总
WritingPrompts Filtered Dataset (LitBench Decontaminated) 数据集概述
数据集描述
- 包含来自Reddit的过滤和去污染WritingPrompts数据
- 专门处理以移除与LitBench测试集的重叠
- 确保语言模型获得无测试集污染的干净训练数据
处理统计
- 生成日期:2025-09-12
- 原始数据集:265,174条条目
- 去污染后:199,248条条目
- 移除污染条目:63,159条
- 保留率:75.14%
污染分析
- 总污染条目:63,159条
- 仅标题污染:12,123条
- 仅文本污染:49,671条
- 双字段污染:1,365条
故事质量过滤
- 处理评论总数:644,817条
- 保留有效故事:524,110条
- 过滤非故事:120,707条
数据集结构
每条条目包含:
post_text:原始写作提示文本post_title:提示标题(通常包含[WP]标签)comment_texts:对提示的故事回复列表num_stories:此提示的有效故事数量
去污染方法
使用多种污染检测方法处理:
- 精确匹配:与LitBench提示直接字符串比较
- 子字符串匹配:检测LitBench提示是否出现在WritingPrompts中
- 反向包含:检查WritingPrompts文本是否包含LitBench提示
源数据集
- 原始来源:https://huggingface.co/datasets/euclaise/WritingPrompts_preferences
- 污染参考:https://huggingface.co/datasets/SAA-Lab/LitBench-Train
用途
python from datasets import load_dataset
dataset = load_dataset("RLAIF/WritingPrompts-Filtered") example = dataset[train][0] prompt_title = example[post_title] prompt_text = example[post_text] stories = example[comment_texts]
预期用途
- 训练创意写作模型
- 微调故事生成语言模型
- 叙事结构和创意写作研究
- RLAIF(来自AI反馈的强化学习)实验
局限性
- 故事来自Reddit,可能包含非正式语言
- 质量参差不齐,因为是社区贡献的故事
- 部分故事可能引用Reddit特定文化或梗
- 去污染仅针对LitBench,未考虑其他测试集
处理代码
处理代码位于:https://github.com/RLAIF/synthLabs
引用
bibtex @dataset{writingprompts_filtered_2024, title={WritingPrompts Filtered Dataset (LitBench Decontaminated)}, author={RLAIF Team}, year={2024}, publisher={Hugging Face}, url={https://huggingface.co/datasets/RLAIF/WritingPrompts-Filtered} }
许可证
- 数据集根据MIT许可证发布
- 原始Reddit内容遵循Reddit服务条款
搜集汇总
数据集介绍
构建方式
在创意写作研究领域,数据质量对模型训练至关重要。该数据集源自Reddit平台的WritingPrompts子论坛,通过多阶段处理流程构建:首先从原始265,174条条目中采用精确匹配、子串匹配和反向包含检测三重去污染机制,清除与LitBench测试集重叠的63,159条样本;随后对644,817条故事回复进行质量过滤,剔除120,707条非故事内容,最终保留199,248条高质量提示及其524,110个有效故事回复。
使用方法
针对创意写作模型的开发需求,研究者可通过HuggingFace数据集库直接加载该资源。典型应用流程包括:使用load_dataset函数调用数据集后,访问每条数据的post_title和post_text字段获取创作提示,通过comment_texts字段提取关联故事集合。该设计特别适用于故事生成模型的微调训练、叙事结构研究以及基于强化学习的AI反馈实验,使用时需注意故事文本可能包含的非正式表达与文化特定元素。
背景与挑战
背景概述
WritingPrompts-Filtered数据集由RLAIF团队于2024年基于Reddit平台的创意写作社区内容构建,专注于解决自然语言生成领域的创造性文本生成问题。该数据集源自euclaise/WritingPrompts_preferences原始数据,经过严格去污染处理,专门针对LitBench测试集进行数据净化,确保模型训练过程中避免测试数据泄露。作为创意写作与叙事结构研究的重要资源,该数据集为语言模型的精细调优提供了高质量训练素材,显著推动了创造性人工智能在叙事生成领域的发展。
当前挑战
该数据集核心挑战在于解决创造性故事生成中的叙事连贯性与风格多样性难题,同时需克服Reddit社区文本固有的非规范表达问题。在构建过程中面临多重技术挑战:需通过精确匹配、子串匹配和反向包含检测等多重去污染方法消除与LitBench测试集的重叠内容;从原始644,817条评论中筛选出524,110篇有效故事,处理高达120,707篇非故事文本的过滤工作;还需保持社区创作的语言特色同时确保数据质量,这对数据清洗算法提出了极高要求。
常用场景
经典使用场景
在创意写作研究领域,WritingPrompts-Filtered数据集为语言模型提供了高质量的叙事生成训练素材。该数据集通过精心筛选的19.9万条Reddit写作提示及其对应故事回复,构建了丰富的叙事结构模板,研究者可基于这些模板训练模型学习故事起承转合的逻辑框架。模型通过分析提示与故事的对应关系,能够掌握如何根据特定主题展开连贯叙事,这种能力对于生成具有逻辑性和创造性的长文本至关重要。
解决学术问题
该数据集有效解决了叙事生成中的测试集污染问题,通过严格的去污染处理移除了6.3万条与LitBench测试集重叠的样本,确保了模型评估的公正性。在学术研究中,这种干净的数据集使得研究者能够准确衡量模型真实的创作能力,避免了数据泄露导致的性能虚高。同时,数据集提供的12万条非故事文本过滤记录,为研究社区文本质量评估标准建立了重要参考基准。
实际应用
在实际应用层面,该数据集支撑了智能写作助手系统的开发,这些系统能够根据用户提供的简短提示生成完整的故事草稿。教育机构利用此类系统开展创意写作教学,帮助学生突破创作瓶颈。出版行业则借助基于该数据集训练的模型进行内容创意发掘,从海量提示中筛选具有商业价值的叙事题材。这些应用显著提升了内容创作的效率和质量,推动了人机协作创作模式的发展。
数据集最近研究
最新研究方向
在创意写作与叙事生成领域,WritingPrompts-Filtered数据集因其严格的去污染处理而成为模型训练的新基准。该数据集通过剔除与LitBench测试集的重叠内容,有效避免了数据泄露问题,为基于强化学习的人类反馈(RLAIF)研究提供了高质量的故事生成语料。当前前沿研究聚焦于利用该数据集探索多模态叙事结构建模、长文本连贯性保持以及角色情感一致性等挑战,这些方向不仅推动了生成模型在创造性任务中的表现,也为人工智能辅助文学创作提供了新的可能性。
以上内容由遇见数据集搜集并总结生成


