bne-hemeroteca-ocr-xix
收藏Hugging Face2026-01-08 更新2026-01-09 收录
下载链接:
https://huggingface.co/datasets/ferjorosa/bne-hemeroteca-ocr-xix
下载链接
链接失效反馈官方服务:
资源简介:
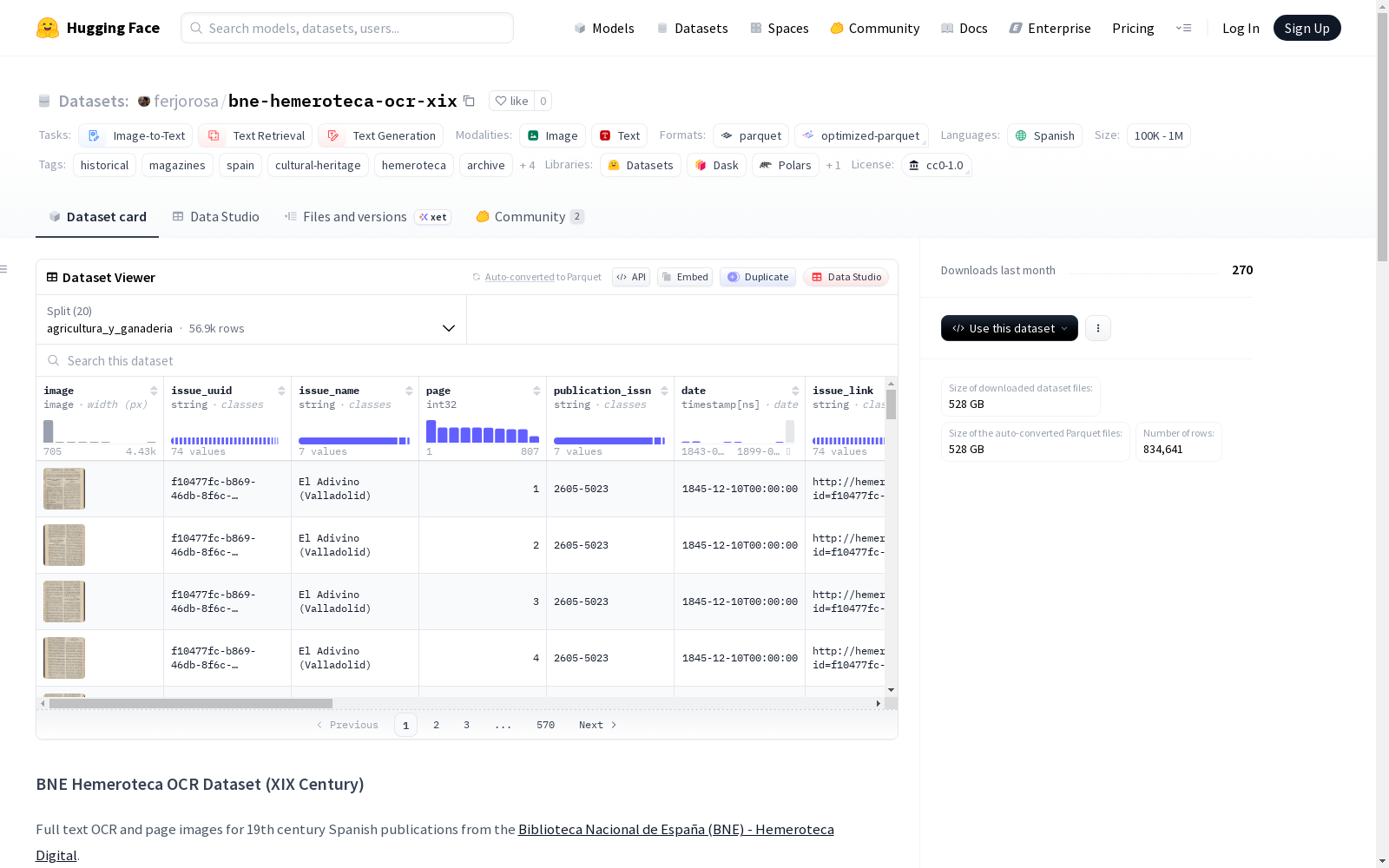
BNE Hemeroteca OCR数据集(19世纪)包含来自西班牙国家图书馆数字报刊库的19世纪西班牙出版物的全文OCR和页面图像。该数据集是从原始BNE Hemeroteca出版物数据集中筛选出的19世纪出版物,排除了多栏布局的报纸。数据集包含25个主题集合,如农业、艺术、科学、文化等。每份出版物通过PDF转换和OCR处理生成图像和文本(Markdown格式)。数据集适用于OCR基准测试和微调、文本检索和RAG系统构建,以及LLM预训练,特别是捕捉19世纪的语言和主题。
创建时间:
2026-01-01
原始信息汇总
BNE Hemeroteca OCR Dataset (XIX Century) 数据集概述
数据集基本信息
- 名称: BNE Hemeroteca OCR Dataset (XIX Century)
- 来源: 西班牙国家图书馆 (Biblioteca Nacional de España, BNE) 的 Hemeroteca Digital
- 语言: 西班牙语 (es)
- 许可协议: CC0 1.0 (公共领域)
- 数据规模: 100K < n < 1M
- 任务类别: 图像到文本、文本检索、文本生成
- 标签: 历史、杂志、西班牙、文化遗产、hemeroteca、档案、bne、ocr、19世纪、预训练
数据集内容与范围
- 核心内容: 包含19世纪西班牙出版物的全文OCR识别结果和页面图像。
- 数据子集: 本数据集是 BNE Hemeroteca publications 的一个子集,经过筛选主要包含19世纪的出版物。
- 时间范围说明: 部分页面可能超出19世纪的时间范围,如需严格时间边界,请使用
date列进行筛选。 - 排除内容: 故意排除了报纸,因为其多栏布局在手动OCR测试中表现不佳。
收录的专题集合
数据集包含以下25个专题集合: Agricultura y ganadería, Almanaques, Arte, Ciencias, Cultura, Deportes, Derecho, Economía, Educación, Ferrocarriles, Fuerzas armadas, Historia, Industria, Literatura, Medicina, Minería, Música, Navegación, Política, Relaciones internacionales, Religión, Revistas de información general, Revistas femeninas, Teatro, Toros。
构建方法
- 数据源: 从 bne-hemeroteca-publications 数据集开始。
- 筛选: 使用
date列筛选出19世纪的出版物,并选择了25个专题集合。 - 处理流程:
- 从BNE下载对应刊物的PDF文件。
- 将页面转换为图像。
- 使用 allenai/olmOCR-2-7B-1025-FP8 模型处理图像,以Markdown格式提取文本。
主要用途
- OCR基准测试与微调: 将现有OCR输出作为基线,通过审阅和修正样本来生成训练数据,以改进针对西班牙语历史文档的OCR模型。
- 文本检索与RAG: 由于原始PDF是扫描图像,本数据集实现了全文搜索。可用于构建检索增强生成 (RAG) 系统,以查询西班牙历史新闻。
- 大语言模型预训练: 使用生成的文本进行通用预训练,或构建专门在19世纪文本上训练的“时间胶囊”语言模型,以捕捉该时代的语言、主题和世界观。
数据字段说明
页面数据字段
| 字段名 | 描述 |
|---|---|
image |
页面图像 |
text |
完整的OCR文本 (Markdown格式) |
issue_uuid |
刊物的唯一标识符 |
issue_name |
刊物的名称/标题 |
page |
页码 |
publication_issn |
出版物的ISSN号 |
date |
出版日期 |
issue_link |
指向BNE网站上原始刊物的链接 |
model_id |
使用的OCR模型 (allenai/olmOCR-2-7B-1025-FP8) |
OCR元数据字段
| 字段名 | 描述 |
|---|---|
primary_language |
在页面上检测到的主要语言 |
is_table |
页面是否包含表格 |
is_diagram |
页面是否包含图表 |
is_rotation_valid |
页面旋转是否有效 |
rotation_correction |
应用的旋转校正度数 |
total_input_tokens |
输入标记数 |
total_output_tokens |
输出标记数 |
引用信息
bibtex @dataset{bne_hemeroteca_ocr_xix, title={BNE Hemeroteca OCR Dataset (XIX Century)}, author={Fernando Rodriguez}, year={2025}, url={https://huggingface.co/datasets/ferjorosa/bne-hemeroteca-ocr-xix}, note={Processed with olmOCR from Hemeroteca Digital (BNE) archives} }
搜集汇总
数据集介绍
构建方式
在数字人文领域,历史文献的数字化与文本化是连接过去与现在的桥梁。本数据集以西班牙国家图书馆的十九世纪出版物为基础,从原始出版物数据集中筛选出该时期的文献,并排除了因版面复杂而识别效果不佳的报纸类目。随后,研究团队下载了选定刊物的PDF文件,将其页面转换为图像,并运用先进的OCR模型进行文本提取,最终生成了包含图像与对应文本的结构化数据。
特点
该数据集覆盖了十九世纪西班牙社会的多元主题,囊括农业、艺术、科学、文化等二十五个专题收藏,展现了该时期丰富的思想与知识脉络。每一条记录不仅包含原始页面图像,还提供了经过OCR处理的文本内容,并附有详细的元数据,如出版日期、语言特征及版面结构信息,为深入的历史语言分析提供了多维度的研究素材。
使用方法
研究者可利用该数据集进行OCR技术的评估与优化,通过校正现有文本生成训练数据,以提升历史文档的识别精度。同时,提取的文本能够支持全文检索与增强生成系统的构建,实现对历史文献的智能查询。此外,这些文本也可作为语言模型的预训练材料,助力构建专注于十九世纪语言风格与知识体系的专用模型。
背景与挑战
背景概述
在数字人文与文化遗产保护领域,历史文献的数字化与文本化是连接过去与未来的关键桥梁。BNE Hemeroteca OCR数据集由Fernando Rodriguez于2025年构建,依托西班牙国家图书馆的Hemeroteca Digital数字馆藏,专注于19世纪西班牙出版物的光学字符识别任务。该数据集涵盖了农业、艺术、科学、文学等25个主题的期刊与杂志,旨在通过先进的OCR技术将扫描图像转化为结构化文本,为历史语言研究、社会文化分析以及大型语言模型的预训练提供高质量的语料基础。其创建不仅促进了西班牙历史文献的开放访问,也为跨学科研究提供了重要的数据支撑,推动了数字档案学与计算语言学在历史文本处理中的融合。
当前挑战
该数据集致力于解决历史文档OCR领域的核心挑战,即如何准确识别19世纪西班牙出版物中因年代久远而产生的字体变异、版面退化及印刷质量不均问题。构建过程中,研究人员面临多重困难:首先,原始文档的多栏布局(如报纸)导致自动OCR效果不佳,迫使数据集排除了报纸类出版物,限制了覆盖范围;其次,历史文献的日期标注可能存在偏差,需通过日期字段进行严格过滤以确保时间一致性;此外,尽管使用了先进的olmOCR模型,但页面中的表格、图表及旋转校正仍需额外元数据标注,增加了处理复杂度。这些挑战凸显了历史文档数字化在技术适配与数据质量控制方面的精细要求。
常用场景
经典使用场景
在历史文献数字化与文化遗产保护领域,BNE Hemeroteca OCR数据集为十九世纪西班牙期刊提供了高质量的图像与文本对应资源。其经典使用场景集中于光学字符识别模型的基准测试与微调,研究者利用数据集中的页面图像与现有OCR输出作为基线,通过人工校正生成精确的标注数据,进而训练针对历史西班牙语文档的专用OCR系统,以应对古老印刷体、版面退化等识别挑战。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作。一方面,研究者利用其训练时序语言模型,构建专注于十九世纪语料的时间胶囊模型,以捕捉该时期的语言特征与世界观念。另一方面,它在信息检索领域的应用催生了针对历史文献的检索增强生成系统设计。此外,数据集常作为基准,用于评估跨时代、多语言OCR模型的泛化性能,推动了文档分析技术在历史档案处理中的进步。
数据集最近研究
最新研究方向
在数字人文与文化遗产计算领域,历史文献的数字化与智能处理正成为前沿热点。BNE Hemeroteca OCR数据集聚焦19世纪西班牙语出版物,其最新研究主要围绕多模态大模型在历史文档分析中的应用展开。学者们利用该数据集训练专用OCR模型,以提升对复杂版式、古旧字体的识别精度,同时结合检索增强生成技术构建历史知识问答系统,实现对西班牙文化变迁的深度挖掘。这些工作不仅推动了跨时代语言模型的预训练,也为社会史、媒介研究提供了量化分析基础,彰显了人工智能在保存与激活历史记忆方面的关键作用。
以上内容由遇见数据集搜集并总结生成


