Prompted Artist Identification Benchmark
收藏arXiv2025-07-25 更新2025-07-26 收录
下载链接:
https://graceduansu.github.io/IdentifyingPromptedArtists
下载链接
链接失效反馈官方服务:
资源简介:
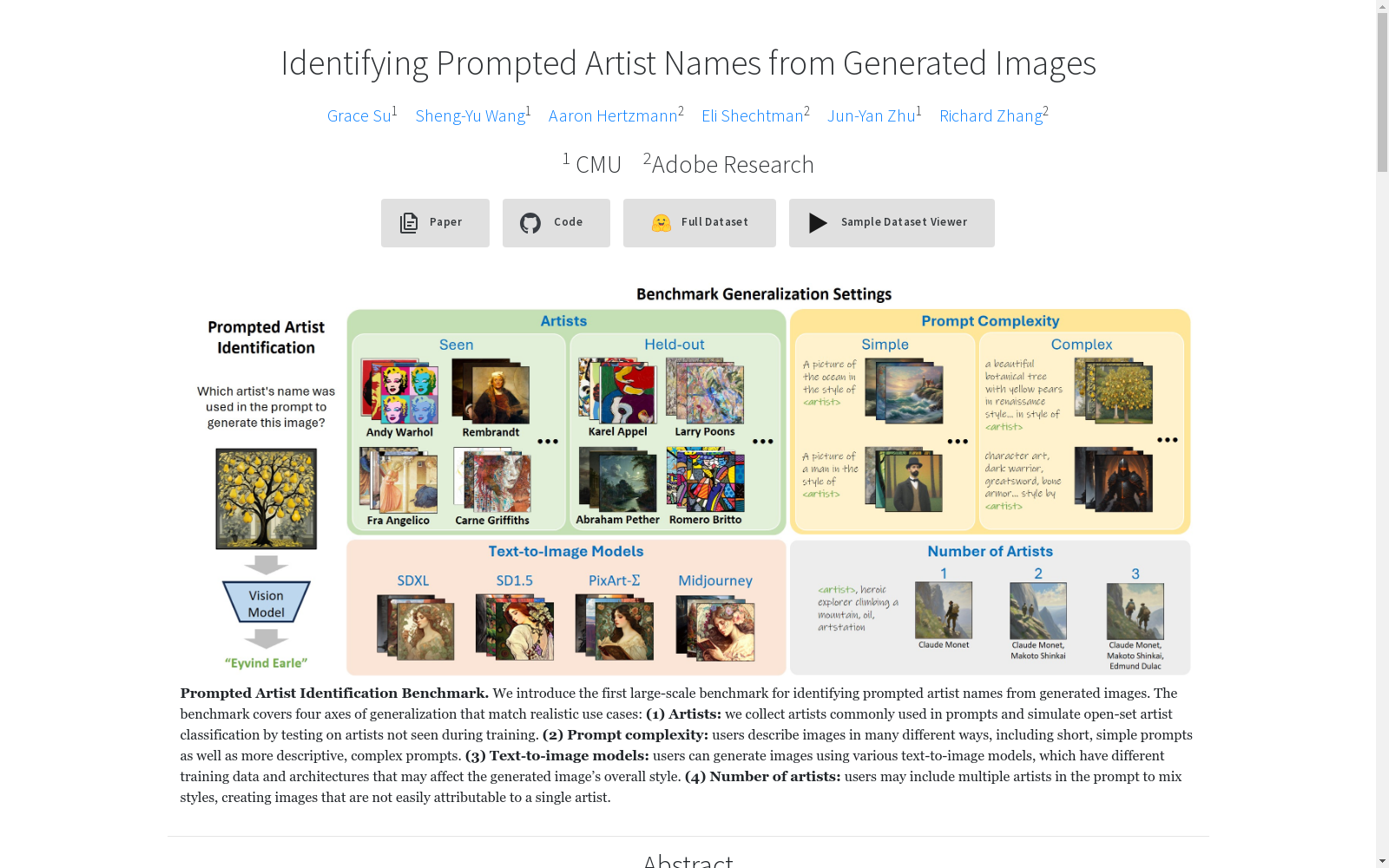
Prompted Artist Identification Benchmark 是一个包含 1,950,000 张图像的数据集,用于评估从生成的图像中识别出提示中使用的艺术家名称的方法。数据集涵盖了 110 位艺术家,并涵盖了四种泛化设置:保留艺术家、增加提示复杂性、多艺术家提示和不同的文本到图像模型。
The Prompted Artist Identification Benchmark is a dataset containing 1,950,000 images, intended to evaluate methods for identifying the artist names used in prompts from generated images. The dataset covers 110 artists and includes four generalization settings: artist holdout, increased prompt complexity, multi-artist prompts, and different text-to-image models.
提供机构:
卡内基梅隆大学, Adobe Research
创建时间:
2025-07-25
原始信息汇总
Identifying Prompted Artist Names from Generated Images 数据集概述
数据集基本信息
- 创建者: Grace Su, Sheng-Yu Wang, Aaron Hertzmann, Eli Shechtman, Jun-Yan Zhu, Richard Zhang
- 机构: 1 CMU, 2 Adobe Research
- 数据集规模: 1.95M 图像
- 覆盖艺术家数量: 110 位(100 位训练集可见艺术家 + 10 位保留测试艺术家)
- 生成模型: SDXL, SD1.5, PixArt-Σ, Midjourney
- 提示词类型: 1000 条复杂提示词 + 500 条简单提示词
核心研究目标
构建首个大规模基准测试,用于从生成图像中识别提示词中调用的艺术家名称,涵盖四个现实使用场景的泛化维度:
- 艺术家泛化:测试未在训练中出现的艺术家
- 提示词复杂度:从简单描述到复杂描述的提示词
- 文本到图像模型:不同架构和训练数据的生成模型
- 艺术家数量:单个或多个艺术家混合风格的提示
数据集结构
- 单艺术家提示图像:通过固定内容提示词(行)插入不同艺术家名称(列)生成
- 多艺术家提示图像:包含2-3个艺术家混合提示的SDXL生成图像
- 测试划分:
- 可见艺术家使用独立测试提示词集
- 保留艺术家额外划分参考图像集用于推理
关键发现
- 风格显著性:艺术家风格视觉表现度随提示词复杂度增加而降低
- 多艺术家挑战:每增加一个艺术家,图像变化幅度递减,识别难度显著增加
- 模型表现:
- 原型网络和监督分类器在可见艺术家和复杂提示词上表现最佳
- 风格描述符对风格鲜明艺术家迁移效果更好
- 多艺术家提示场景所有方法性能均未饱和
基准测试结果
- 单艺术家分类准确率:在100-way(可见艺术家)和10-way(保留艺术家)分类任务中评估
- 多艺术家评价指标:采用mAP@10排名指标评估2-3艺术家混合提示图像
- 跨模型泛化:测试SDXL/SD1.5/PixArt/Midjourney生成图像的识别一致性
相关资源
- 论文: arXiv:2507.18633 (2025)
- 代码/数据: 提供完整数据集和样本数据集查看器
- 引用格式: bibtex @article{su2025identifying, author = {Su, Grace and Wang, Sheng-Yu and Hertzmann, Aaron and Shechtman, Eli and Zhu, Jun-Yan and Zhang, Richard}, title = {Identifying Prompted Artist Names from Generated Images}, journal = {arXiv preprint arXiv:2507.18633}, year = {2025} }
应用价值
为文本到图像模型的负责任监管提供公开测试平台,推动生成内容溯源技术发展
搜集汇总
数据集介绍
构建方式
Prompted Artist Identification Benchmark数据集通过系统化的方法构建,涵盖了110位艺术家的195万张生成图像。数据集的构建过程包括四个关键维度:艺术家选择、提示复杂度、文本到图像模型多样性以及多艺术家提示。艺术家名单从Lexica.art网站高频使用的400位艺术家中筛选并去重,最终保留110位,其中100位用于训练,10位作为保留测试集。提示分为简单提示(如“海洋风格的<艺术家>画作”)和复杂提示(来自真实用户提交的JourneyDB数据集),并确保测试提示与训练提示不重叠。图像生成使用了四种主流文本到图像模型(SDXL、SD1.5、PixArt-Σ和Midjourney),每种模型生成图像时均采用多种子以确保多样性。
特点
该数据集的核心特点在于其多维度的泛化能力设计。首先,通过保留部分艺术家作为测试集,模拟了开放集分类场景,要求模型能够识别未见过的艺术家风格。其次,提示复杂度的变化(从简洁描述到详细内容)有效捕捉了艺术家风格在生成图像中的显着性差异。此外,不同文本到图像模型的加入揭示了模型架构对风格表达的影响,而多艺术家提示则挑战了模型对混合风格的解析能力。数据集的规模(195万张图像)和多样性(涵盖110位艺术家、多种提示类型和生成模型)使其成为评估生成图像中艺术家风格识别的权威基准。
使用方法
该数据集的使用方法聚焦于多维度评估模型的泛化能力。研究者可通过四种主要场景进行测试:1)对训练中未见过的艺术家进行分类(开放集识别);2)分析模型在不同复杂度提示下的表现;3)跨文本到图像模型的风格一致性分析;4)多艺术家提示的混合风格解析。评估时可采用检索式方法(如对比风格描述符CSD)或分类方法(如原型网络)。数据集特别适合研究生成图像的风格归属问题,包括但不限于监督分类、少样本学习、风格相似性度量等任务。所有图像均标注了原始生成提示和艺术家信息,支持端到端的训练与评估流程。
背景与挑战
背景概述
Prompted Artist Identification Benchmark数据集由卡内基梅隆大学与Adobe研究院的研究团队于2025年创建,旨在解决生成式AI时代的关键问题:通过生成图像反推其文本提示中引用的艺术家名称。该数据集包含195万张图像,覆盖110位艺术家,构建了首个面向艺术风格溯源的标准化评估体系。其创新性体现在四个维度的泛化测试:未见艺术家识别、不同复杂度提示词、多模型生成差异以及混合艺术家风格解析,为AI生成内容的版权溯源与责任归属提供了重要研究基础。
当前挑战
该数据集面临双重挑战:在领域问题层面,需解决生成图像与真实艺术作品间的风格表征差异,特别是当提示词包含多个艺术家或复杂描述时风格特征的稀释效应;在构建层面,需克服不同文本到图像模型(如SDXL、Midjourney)对相同艺术家的差异化呈现,以及平衡公共领域与非公共领域艺术家的版权伦理问题。此外,模型对未见艺术家的泛化能力、复杂提示导致的风格弱化现象,以及多艺术家提示的混合风格解析,构成了当前技术突破的核心难点。
常用场景
经典使用场景
Prompted Artist Identification Benchmark数据集在生成图像中识别被提示的艺术家名称的任务中具有经典应用场景。该数据集通过构建大规模标注图像集,覆盖了110位艺术家和四种不同的泛化设置,包括未见艺术家、复杂提示、多艺术家提示以及不同文本到图像模型。这使得该数据集成为评估视觉方法在识别生成图像中艺术家名称能力的理想基准。
解决学术问题
该数据集解决了生成图像中艺术家风格识别的关键学术问题,特别是在开放集艺术家分类、复杂提示下的风格识别以及多艺术家风格混合的挑战。通过提供多样化的生成图像和真实艺术家参考图像,该数据集为研究生成模型如何表达和传递艺术风格提供了重要资源,推动了生成内容负责任审核的研究。
衍生相关工作
该数据集衍生了多项经典工作,包括基于特征相似性的方法、对比风格描述符、数据归因方法以及监督分类器和少样本原型网络。这些工作不仅在艺术家风格识别任务中取得了显著进展,还为生成模型的风格表达和理解提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


