LibriConvo-segmented
收藏Hugging Face2025-10-30 更新2025-10-31 收录
下载链接:
https://huggingface.co/datasets/gedeonmate/LibriConvo-segmented
下载链接
链接失效反馈官方服务:
资源简介:
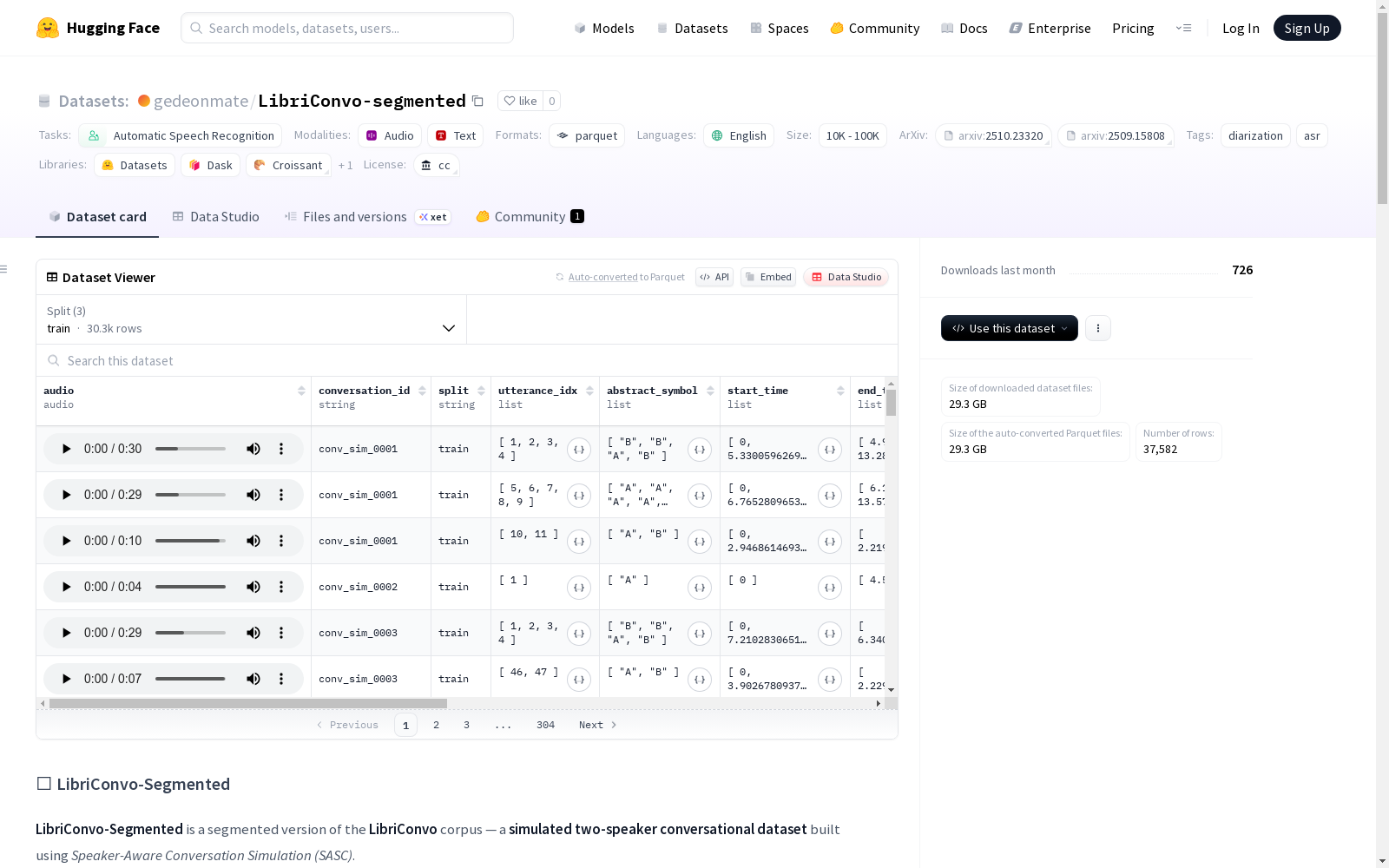
LibriConvo-Segmented是一个基于LibriConvo语料库的分割版本,它是一个使用Speaker-Aware Conversation Simulation (SASC)构建的模拟双讲者对话数据集。该数据集旨在用于训练和评估多讲者语音处理系统,包括讲者分离、自动语音识别(ASR)和重叠语音建模。这个分割版本提供了来自完整LibriConvo对话的≤30秒对话片段,其中40%应用了房间脉冲响应。整个LibriConvo语料库共有240.1小时的对话,涉及1,496个对话和830个不同讲者。这个分割版本提供了更短的、自包含的音频片段,适合用于微调ASR和讲者分离模型。
创建时间:
2025-10-28
原始信息汇总
LibriConvo-Segmented 数据集概述
数据集简介
LibriConvo-Segmented 是 LibriConvo 语料库的分段版本,这是一个使用说话人感知对话模拟方法构建的模拟双说话人对话数据集。该数据集专为多说话人语音处理系统的训练和评估而设计,包括说话人日志、自动语音识别和重叠语音建模。
技术特性
- 音频采样率:16000 Hz
- 音频格式:WAV(单声道)
- 分段长度:≤30秒对话片段
- 房间脉冲响应应用:40%的片段应用了房间脉冲响应
- 分割标准:说话人不重叠
数据规模
| 分割集 | 样本数量 | 数据大小 |
|---|---|---|
| 训练集 | 30,313 | 25,575,970,863.525 字节 |
| 验证集 | 3,595 | 3,028,603,290.34 字节 |
| 测试集 | 3,674 | 3,133,192,896.73 字节 |
| 总计 | 37,582 | 31,737,767,050.595 字节 |
数据特征
- conversation_id:对话标识符
- audio:音频数据
- split:数据集分割
- utterance_idx:对话中的话语索引序列
- abstract_symbol:高层符号话语ID序列
- text:话语文本转录序列
- duration_sec:片段持续时间序列
- start_time:对话内开始时间序列
- end_time:对话内结束时间序列
- abs_start_time:全局开始时间序列
- abs_end_time:全局结束时间序列
- segment_id:局部片段索引
- segment_conversation_id:唯一片段标识符
- rir:是否应用房间脉冲响应
数据集特点
- 基于LibriTTS话语按书籍组织,保持叙事连续性
- 使用CallHome统计数据进行停顿建模
- 应用压缩去除过长静音同时保留轮换动态
- 通过新颖的房间脉冲响应选择程序增强声学真实性
- 产生说话人不重叠的分割以进行稳健评估
相关资源
完整论文:https://arxiv.org/abs/2510.23320
许可证
Creative Commons许可证
搜集汇总
数据集介绍
构建方式
在语音处理研究领域,LibriConvo-segmented数据集通过创新的说话人感知对话模拟技术构建而成。该技术基于LibriTTS语料库中的朗读语音,依据书籍内容组织语句以保持叙事连贯性,并参照CallHome通话数据统计模型对话停顿特征。通过压缩处理消除过长静音片段,同时保留自然对话的轮换动态,进一步采用房间脉冲响应筛选程序增强声学真实性,确保说话人空间分布的合理性。最终生成的对话数据被分割为不超过30秒的片段,其中40%的片段应用了房间混响效果,形成适用于多说话人语音处理的标准化语料。
特点
该数据集在语音处理领域展现出多重显著特征。其核心价值在于提供了模拟真实对话的语音片段,每个片段均包含精确的时间标注和文本转录信息。数据集采用说话人分离的划分原则,确保训练集与测试集之间不存在说话人重叠,有效提升模型评估的可靠性。所有音频均以16kHz采样率的单声道WAV格式存储,并配备完整的元数据体系,包括对话标识符、语句索引、抽象符号标记及时间戳信息。这些特征共同构成了支持说话人日志、自动语音识别和重叠语音建模研究的理想数据基础。
使用方法
对于研究人员而言,该数据集可通过HuggingFace数据集库便捷加载。使用标准接口调用load_dataset函数并指定数据集名称,即可获取包含训练集、验证集和测试集的完整数据对象。每个数据样本均以结构化形式呈现,包含解码后的音频数据及对应的元数据字段。这种标准化访问方式使得研究者能够快速开展多说话人语音处理任务的实验,包括但不限于说话人分离性能评估、自动语音识别模型训练以及重叠语音处理算法的验证,为相关领域的研究提供高效的数据支持。
背景与挑战
背景概述
在语音处理领域,多说话人对话系统的开发需要高质量的数据支撑。LibriConvo-segmented数据集由Máté Gedeon与Péter Mihajlik于2025年构建,基于说话人感知对话模拟技术,通过整合LibriTTS朗读语料与CallHome通话统计特征,实现了对自然对话节奏与空间声学环境的精确建模。该数据集包含240.1小时经过分段处理的对话片段,专注于解决多说话人场景下的语音识别与说话人日志分析问题,为语音处理模型提供了兼具叙事连贯性与声学真实性的训练基础。
当前挑战
该数据集致力于应对多说话人语音处理中的核心难题:如何在重叠语音场景中实现精准的说话人分离与语音识别。构建过程中面临双重挑战:一方面需通过房间脉冲响应筛选机制平衡声学仿真度与计算效率,另一方面要维持对话时序自然性,这要求对静音压缩与话轮转换统计数据进行精细化调控。此外,保持说话人无关的数据划分策略也增加了数据构建的复杂性,确保模型评估的泛化能力。
常用场景
经典使用场景
在语音处理研究领域,LibriConvo-segmented数据集凭借其模拟双人对话的独特结构,成为评估多说话人语音系统的经典基准。该数据集通过分段处理生成30秒内的对话片段,其中40%的片段应用了房间脉冲响应技术,为说话人日志和自动语音识别任务提供了高度仿真的训练环境。其自然对话流和上下文连贯性设计,使得研究者能够精准分析重叠语音场景下的声学特征与说话人交互模式。
解决学术问题
该数据集有效解决了多说话人语音处理中的核心学术难题,包括重叠语音的分离与识别、说话人身份的动态追踪以及噪声环境下的语音增强。通过引入基于书籍叙事的对话连贯性设计和统计驱动的停顿建模,显著提升了对话场景中语音识别系统的鲁棒性。其说话人分离的数据划分策略,为模型泛化能力评估建立了严谨的学术标准,推动了对话语音处理的理论突破。
衍生相关工作
基于该数据集衍生的经典研究包括说话人感知对话模拟方法的深度优化,以及端到端多任务学习框架的构建。相关研究通过结合该数据集的时序标注与声学特征,开发出新型的联合语音识别与说话人日志模型。这些工作不仅扩展了对话语音分析的算法边界,更催生了面向长对话场景的增量式处理范式,持续推动着多模态人机交互技术的发展。
以上内容由遇见数据集搜集并总结生成


