AlignBench
收藏arXiv2025-11-26 更新2025-11-27 收录
下载链接:
https://dahlian00.github.io/AlignBench/
下载链接
链接失效反馈官方服务:
资源简介:
AlignBench是由欧姆龙SINIC X公司与大阪大学联合构建的细粒度图文对齐基准数据集,旨在评估视觉语言模型的精细语义对齐能力。该数据集包含89,473条标注语句,平均句长17.7词,词汇量达42,000,数据源涵盖六种图像描述模型和两种文生图模型的生成结果。数据集通过两阶段标注流程构建,首先由众包工作者进行句子级正确性标注,再经专家审核确保质量,并额外提供幻觉类型细分标签。该数据集主要应用于评估视觉语言模型在复杂场景下的图文对齐能力,为解决多模态模型幻觉检测和合成数据清洗等关键问题提供基准支撑。
AlignBench is a fine-grained image-text alignment benchmark dataset jointly constructed by Omron SINIC X Corporation and Osaka University, which is designed to evaluate the fine-grained semantic alignment capabilities of vision-language models. This dataset contains 89,473 annotated sentences, with an average sentence length of 17.7 words and a vocabulary size of 42,000. Its data sources cover the generation outputs of six image captioning models and two text-to-image models. The dataset is built through a two-stage annotation workflow: first, crowd workers perform sentence-level correctness annotation, followed by expert reviews to ensure data quality, and additionally provides fine-grained sub-type labels for hallucinations. This dataset is mainly used to evaluate the image-text alignment capabilities of vision-language models in complex scenarios, providing benchmark support for solving key problems such as multimodal model hallucination detection and synthetic data cleaning.
提供机构:
欧姆龙SINIC X公司, 大阪大学
创建时间:
2025-11-26
原始信息汇总
AlignBench 数据集概述
基本信息
- 数据集名称:AlignBench
- 主要功能:评估视觉语言模型在图文对齐方面的能力
- 创建方式:使用先进的图像到文本和文本到图像模型生成带有或不带有细微幻觉的合成图像-标题对
- 标注特征:未对齐的单词用红色高亮显示
核心特点
- 评估重点:细粒度图文对齐能力
- 数据构成:包含详细图像-标题对,每个句子都标注了正确性
- 挑战性:多模态模型产生的细微幻觉难以被最先进的视觉语言模型检测
关键发现
- CLIP系列模型在组合对齐方面表现近乎盲目
- 检测器系统性地对早期句子评分过高
- 模型表现出强烈的自我偏好,偏向自身输出并损害检测性能
数据集统计
- 包含大量带标注的句子,足以进行模型基准测试
- 排除了标签未知的句子
- 错误分布特征:
- 所有标题生成器在第一个位置出错较少
- 大多数错误发生在属性和文本类别中
性能表现
- GPT-5在所有模型中表现最佳
- Llama-4是最佳开源模型
- 模型规模增大可提升性能
- 不同视觉语言模型对文本到图像模型的鲁棒性存在差异
相关资源
- 论文地址:https://arxiv.org/abs/2511.20515
- 数据集地址:https://dahlian00.github.io/AlignBench/
搜集汇总
数据集介绍
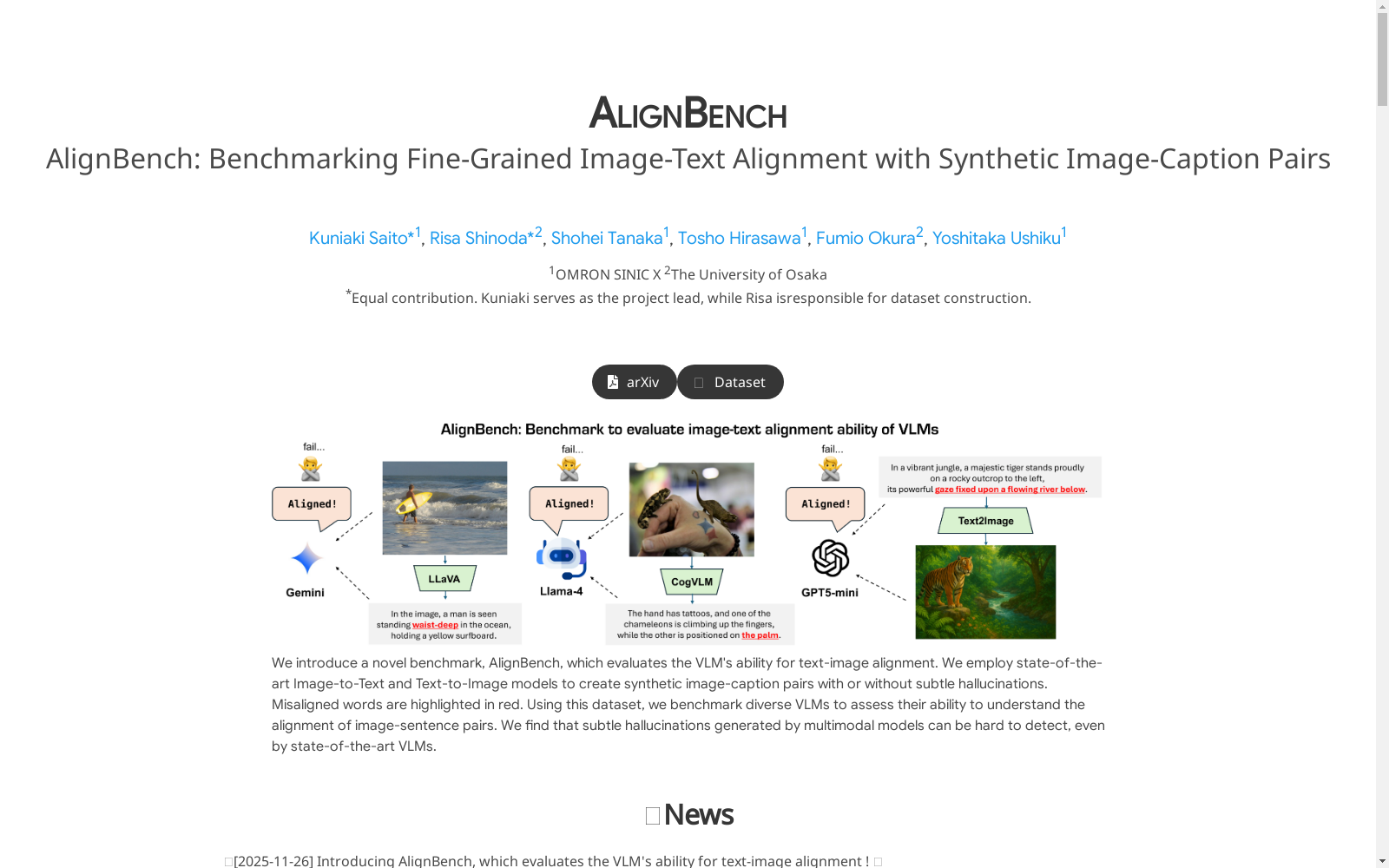
构建方式
在视觉与语言交叉研究领域,构建能够精确评估图文对齐能力的基准数据集至关重要。AlignBench通过整合六种先进图像描述模型与两种文本生成图像模型,系统性地构建了包含约8.9万条标注语句的大规模数据集。其构建过程首先基于CC12M和COCO 2017数据集筛选2000张跨领域图像,通过多样化指令模板生成多句描述,并采用两阶段标注流程:先由众包工作者进行句子级语义对齐标注,再通过多数投票与专家审核确保标注质量,最终形成包含正确、错误及未知标签的三元标注体系。
特点
该数据集的核心特征体现在其细粒度评估能力与广泛覆盖性上。相较于传统基于规则扰动或简短描述的基准,AlignBench囊括了由前沿模型生成的复杂自然语句,平均句长达到17.7词,词汇量覆盖4.2万独特词条,为评估模型对细微幻觉的识别能力提供了丰富场景。特别值得注意的是,数据集中标注了八类幻觉类型(如属性错误、方向偏差等),并揭示出描述模型在语句中后段更易产生幻觉的分布规律,为深入分析模型弱点提供了结构化视角。
使用方法
作为图文对齐能力的评估基准,AlignBench支持以句子级二元分类任务形式进行模型测评。研究者可将图像-语句对输入待评估的视觉语言模型,通过特定提示模板获取模型对图文一致性的置信度评分(0-100分),进而计算各描述模型输出子集的AUROC指标以实现阈值无关的效能评估。该基准还支持幻觉片段定位任务,通过解析模型输出的错误标记范围与人工标注的对比,深入探究模型对细节错误的定位能力,为开发更精准的图文对齐模型提供多维验证框架。
背景与挑战
背景概述
AlignBench由OMRON SINIC X Corporation与大阪大学于2025年联合推出,旨在解决视觉语言模型在细粒度图文对齐评估中的局限性。传统基准依赖规则化扰动或简短描述,难以捕捉复杂语义偏差。该数据集通过整合先进图文生成模型合成的带注释图像-标题对,为评估模型对齐能力提供了新范式,推动了多模态推理研究的发展。
当前挑战
在领域问题层面,AlignBench需应对模型对细微幻觉的检测挑战,例如属性误判、方向描述错误等难以察觉的语义偏差。构建过程中,合成数据的质量保障成为核心难题,需通过多轮人工标注与共识机制消除主观性影响,同时平衡不同生成模型的输出多样性以确保评估全面性。
常用场景
经典使用场景
在视觉语言模型评估领域,AlignBench作为精细图像-文本对齐基准,其经典应用场景聚焦于检测多模态模型生成的描述中存在的细微幻觉现象。通过整合先进图像描述器和文生图模型输出的合成图像-字幕对,该数据集构建了包含空间关系、物体属性等八类语义错误的评估体系,为衡量模型在复杂自然语言场景下的对齐能力提供了标准化测试平台。
解决学术问题
该数据集有效解决了传统基准在细粒度对齐评估中的局限性,突破了规则化扰动和短文本描述的约束。其通过大规模人工标注的句子级语义对齐标签,为研究社区提供了量化模型幻觉检测能力的新范式,显著推进了对CLIP架构局限性、位置偏差效应及模型自偏好现象等核心学术问题的探索深度。
衍生相关工作
该数据集催生了系列创新研究,包括基于链式思维的幻觉定位方法、多模型集成检测框架,以及针对位置偏差的矫正算法。其构建理念更启发了ZINA细粒度幻觉检测数据集的设计,推动形成了以VLM为核心的新型评估范式,为InternVL2等开源模型的迭代优化提供了关键训练数据。
以上内容由遇见数据集搜集并总结生成


