WavBench
收藏arXiv2026-02-14 更新2026-02-15 收录
下载链接:
https://naruto-2024.github.io/wavbench.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
WavBench是由浙江大学等机构联合开发的端到端语音对话模型综合评测基准,旨在解决现有评测标准在认知复杂性、口语化表达及副语言特征方面的不足。该数据集包含三个核心子集:Pro子集针对高难度推理任务设计,Basic子集定义口语自然度的新标准,Acoustic子集覆盖10种副语言特征(如年龄、情感、背景音等)。数据通过GPT-4等大语言模型与商用级TTS工具生成,涵盖数学、编程、安全等7大认知领域,适用于评估复杂推理与情感交互场景下的语音模型表现。
WavBench is a comprehensive evaluation benchmark for end-to-end speech dialogue models, jointly developed by Zhejiang University and other institutions. It aims to address the limitations of existing evaluation standards in terms of cognitive complexity, colloquial expressions and paralinguistic features. This dataset includes three core subsets: the Pro subset is tailored for high-difficulty reasoning tasks, the Basic subset establishes a new benchmark for spoken naturalness, and the Acoustic subset covers 10 paralinguistic features such as age, emotion, background audio and so on. The data is generated using large language models (e.g., GPT-4) and commercial-grade text-to-speech (TTS) tools, covering seven cognitive domains including mathematics, programming, cybersecurity and other fields. It is suitable for evaluating the performance of speech models in scenarios involving complex reasoning and emotional interaction.
提供机构:
厦门大学; 浙江大学; 香港中文大学·深圳
创建时间:
2026-02-13
原始信息汇总
WavBench 数据集概述
数据集名称
WavBench
核心目标
评估端到端语音对话模型在真实世界场景中的能力,重点关注音频中心的口语语义和副语言保真度。
基准框架
- Pro 子集:用于挑战具备推理能力的模型,包含复杂和判别性任务。
- Basic 子集:用于基准测试口语适应性,定义了一个以“可听性”为核心的新标准。
- Acoustic 子集:用于评估全面的副语言交互能力。
数据集规模
- 包含 17,577 个项目。
- 总时长 76.5 小时。
评估维度与内容
1. 口语表达
- 认知领域:涵盖创意写作、指令遵循、代码、数学、问答、安全性和逻辑共7个领域。
- 组织层级:分为 Basic 和 Pro 两个层级。
2. 声学交互
- 组成部分:包含显式理解、显式生成和隐式对话。
- 评估的副语言维度(10个):
- 说话者信息:年龄、性别、口音、语言。
- 声学特征:音高、语速、音量、情感。
- 背景声音:音频事件、音乐。
- 具体属性:
- 年龄:儿童、青少年、中年、老年。
- 性别:男性、女性。
- 口音:印度、加拿大、英国、新加坡、美国、澳大利亚。
- 语言:中文、英文。
- 音高:低、正常、高。
- 语速:慢、正常、快。
- 音量:低、正常、高。
- 情感:中性、快乐、悲伤、愤怒、惊讶、厌恶、恐惧。
- 音频事件:风声、人群声、雷声、发令枪声、摔门声。
- 音乐:钢琴、吉他、鼓。
3. 交互类型
- 评估显式指令和隐式多轮对话,要求模型在没有直接提示的情况下推断声学线索。
评估模型
评估了五款先进的端到端语音对话模型:
- Qwen3-Omni
- Kimi-Audio
- Mimo-Audio
- Step-Audio-2
- GPT-4o Audio
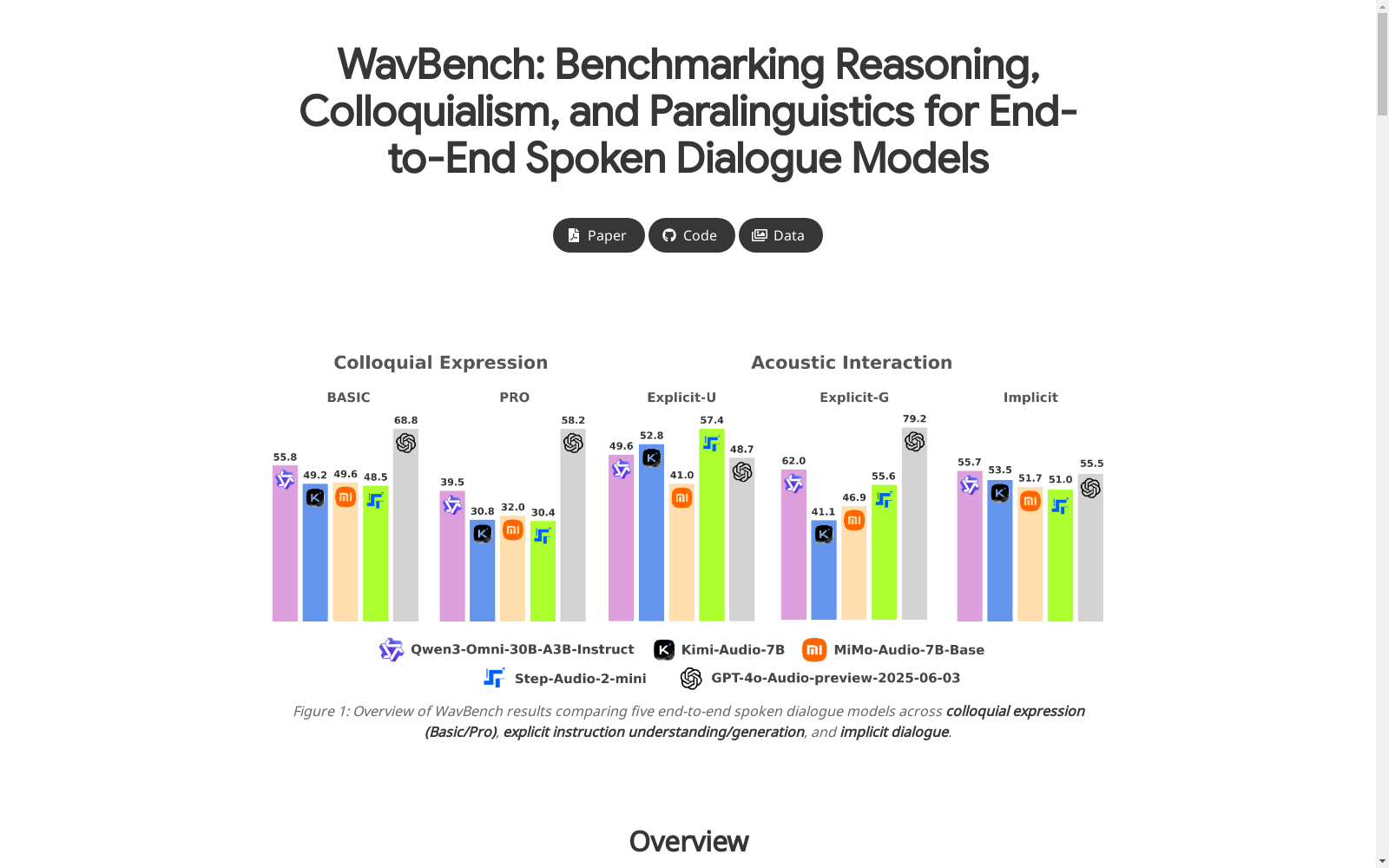
评估结果概览
评估结果分为五个面板:
- 面板A:口语表达能力 - Pro子集
- 面板B:口语表达能力 - Basic子集
- 面板C:声学显式理解
- 面板D:声学显式生成
- 面板E:隐式声学交互能力
引用信息
- 标题:WavBench: Benchmarking Reasoning, Colloquialism, and Paralinguistics for End-to-End Spoken Dialogue Models
- 作者:Yangzhuo Li, Shengpeng Ji, Yifu Chen, Tianle Liang, Haorong Ying, Yule Wang, Junbo Li, Jun Fang, Zhou Zhao
- 年份:2026
- arXiv ID:2602.12135
- arXiv 链接:https://arxiv.org/abs/2602.12135
搜集汇总
数据集介绍
构建方式
在语音对话模型日益融入复杂推理能力的背景下,WavBench的构建旨在填补现有评估在真实场景对话能力上的空白。该数据集通过系统化的多阶段流程构建:首先,从15个开源数据集中聚合高质量样本,涵盖代码、创意写作、逻辑推理等七个认知领域,并依据任务复杂度划分为基础子集和专业子集。随后,利用大型语言模型对文本查询进行口语化改写,将静态文本转化为基于场景的口语询问,并将数学符号、代码块等非语言元素转换为自然语言描述,确保其可听性与可理解性。接着,通过人工专家验证确保语义保真度与语音适应性,过滤逻辑错误或格式不兼容的样本。最后,采用IndexTTS2等高质量语音合成工具生成音频数据,并基于Whisper转录与词错误率筛选,确保音频保真度与清晰度,从而形成一个全面覆盖语义表达与声学交互的基准测试集。
特点
WavBench的突出特点在于其三重评估框架的构建,全面涵盖认知复杂性、口语表达与副语言保真度。在语义层面,数据集划分为专业子集与基础子集:专业子集专注于高认知负荷场景,如多步数学推理与复杂编码逻辑,旨在严格测试模型简化复杂逻辑并以口语化方式传递的能力;基础子集则定义口语表达标准,强调词汇适当性、语言自然性与交互亲和力,区分真实口语交互与机械文本生成。在声学层面,数据集覆盖十个副语言维度,包括说话人信息、声学特征与背景声音,并通过显式指令与隐式对话两种设置进行评估。显式指令要求模型根据明确提示理解或生成特定声学属性,而隐式对话则需模型从上下文推断并生成风格匹配的响应,从而模拟真实世界对话的复杂性。这种多层次、细粒度的设计使WavBench能够全面评估端到端语音对话模型在真实场景中的综合能力。
使用方法
WavBench的使用旨在系统评估端到端语音对话模型在真实对话场景中的性能。评估任务依据三重框架展开:在专业子集中,模型需处理高难度认知任务,不仅要求事实准确性,还需通过口语化优化简化复杂逻辑,确保听觉可理解性并降低认知负荷;在基础子集中,模型需在常规交互中体现口语表达的“可听性”,通过自然词汇、灵活句法与互动引导,区分真实口语交互与文本生成。在声学交互集中,评估分为显式指令与隐式对话:显式指令下,模型需准确识别输入语音中的副语言风格或根据明确指令生成风格匹配的语音响应;隐式对话则统一评估理解与生成能力,要求模型从对话上下文中推断隐含的副语言信息,并生成内容正确且风格一致的语音回应。评估采用分层评分机制,利用Gemini等先进模型对回答的语义正确性与表达自然性进行量化评分,从而提供模型在复杂推理、口语表达与副语言保真度交叉领域的全面性能洞察。
背景与挑战
背景概述
随着端到端语音对话模型的快速发展,传统评估标准已难以全面衡量其在真实场景下的综合能力。WavBench由厦门大学、浙江大学等机构的研究团队于2026年提出,旨在填补现有基准在认知复杂性、口语化表达及副语言特征评估方面的空白。该数据集构建了一个包含专业推理、基础口语及声学交互的三元评估框架,通过涵盖数学、逻辑、代码等七个认知领域及年龄、情感、口音等十个副语言维度,系统性地挑战模型的现实对话能力。WavBench的推出为语音对话系统从简单交互向智能代理演进提供了关键的评估工具,推动了该领域向更自然、更具认知深度的方向发展。
当前挑战
WavBench致力于解决端到端语音对话模型在真实世界场景下面临的核心挑战:如何同时实现复杂推理、自然口语化表达及精细副语言理解与生成。具体而言,在领域问题层面,模型需在高认知负载任务中保持逻辑严谨性,同时将复杂推理转化为听觉友好的口语解释,并确保副语言特征与语义内容的高度一致。在构建过程中,挑战主要集中于数据生成与验证:需将书面文本及符号逻辑转化为可口语化的自然语言描述,避免机械背诵;同时需合成高保真且多样化的语音数据,精确控制年龄、情感、口音等副语言属性,并确保多轮对话中声学风格的时序一致性。此外,评估体系需设计兼顾内容正确性、表达自然度及声学匹配度的多维度量标准。
常用场景
经典使用场景
在端到端语音对话模型的研究领域,WavBench作为一项综合性基准测试,其经典使用场景聚焦于评估模型在真实世界对话中的多维度能力。该数据集通过构建包含基础子集、专业子集和声学子集的三元框架,系统性地考察模型在口语化表达、复杂推理以及副语言特征理解与生成方面的表现。研究者通常利用WavBench对新兴的语音对话系统进行横向对比,例如在专业子集中测试模型处理多步骤数学推理或复杂编码逻辑时,能否以自然的口语方式简化并传达复杂逻辑,从而衡量模型在高压认知负荷下的表现。
衍生相关工作
WavBench的提出催生并衔接了一系列围绕语音对话模型评估的经典研究工作。其三元评估框架启发后续研究更细致地探索推理能力与口语表达的融合,例如针对专业子集中高难度任务的模型优化策略。同时,它对副语言深度评估的强调,促进了像VStyle这样专注于语音风格适应任务的研究,以及MMSU这类融合语言学理论的大规模语音理解基准的发展。这些衍生工作共同推动了评估标准从单一的语义正确性,向涵盖认知、表达与声学多维度的综合体系演进,构成了当前语音对话模型评估领域的重要脉络。
数据集最近研究
最新研究方向
随着端到端语音对话模型的快速发展,WavBench作为首个全面评估模型在真实场景下综合对话能力的基准,正引领该领域的前沿研究方向。其核心聚焦于解决传统评估中忽视的三大关键维度:复杂推理能力、口语化表达及副语言信息处理。在推理层面,研究重点转向如何让模型在高认知负荷任务中,将多步逻辑推理转化为自然、易懂的口语解释,以降低听觉认知负担。口语化表达方面,研究致力于超越文本生成的准确性,探索如何通过词汇适切性、句法自然度及互动亲和力来构建‘可听性’标准。副语言研究则深入模型对情感、口音、语调等非文本信息的理解与生成能力,特别是在隐含对话中维持副语言一致性的挑战。这些方向共同推动语音助手从功能型工具向具备情感智能与认知深度的对话伙伴演进,为构建更鲁棒、人性化的语音交互系统提供了关键评估框架与进化路径。
相关研究论文
- 1WavBench: Benchmarking Reasoning, Colloquialism, and Paralinguistics for End-to-End Spoken Dialogue Models厦门大学; 浙江大学; 香港中文大学·深圳 · 2026年
以上内容由遇见数据集搜集并总结生成


