tip-of-my-tongue-known-item-search-triplets
收藏Hugging Face2024-11-14 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/webis/tip-of-my-tongue-known-item-search-triplets
下载链接
链接失效反馈官方服务:
资源简介:
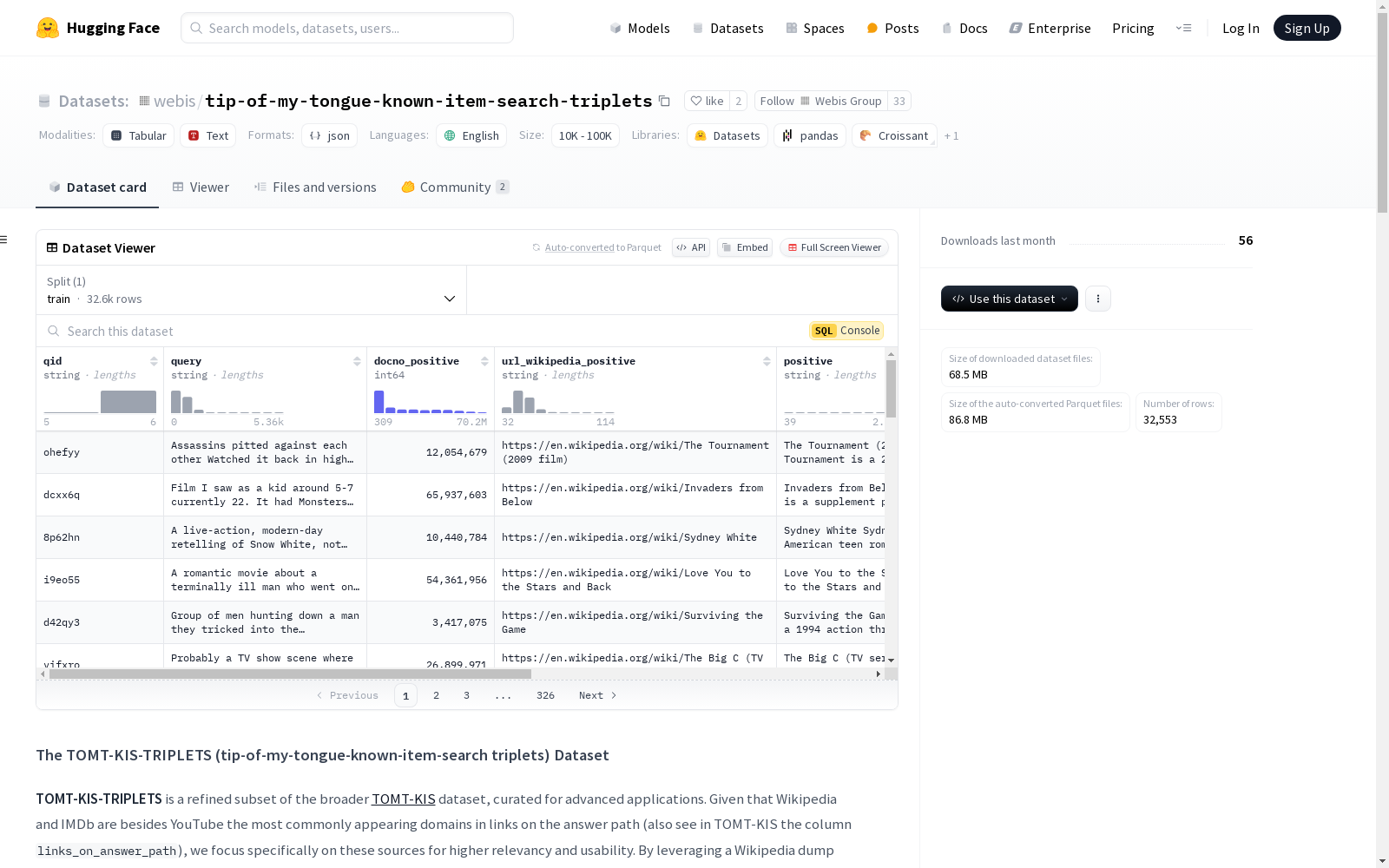
TOMT-KIS-TRIPLETS数据集是TOMT-KIS数据集的精炼子集,专注于包含指向Wikipedia或IMDb链接的问题。该数据集旨在用于监督学习任务,提供与相关Wikipedia文章的直接链接。数据集包含查询ID、查询文本、正负文档的文档ID、Wikipedia URL以及Wikipedia文章的内容等字段。数据集经过处理以确保相关性和一致性,根据TREC-ToT 2024标准过滤掉有偏见的条目。
提供机构:
Webis Group
创建时间:
2024-11-05
搜集汇总
数据集介绍
构建方式
TOMT-KIS-TRIPLETS数据集是从更广泛的TOMT-KIS数据集中精心筛选出的子集,专注于Wikipedia和IMDb这两个高相关性和实用性的数据源。通过利用Wikipedia的数据转储和SPARQL Wikipedia查询服务,该数据集构建了一个包含直接链接到相关Wikipedia文章的标注数据集,特别适用于监督学习任务。数据集的构建过程包括从Reddit问题中提取URL,筛选出Wikipedia或IMDb链接,并通过SPARQL服务获取相应的wikidata_url,最终形成一个包含32,553个Reddit问题的数据集。
特点
TOMT-KIS-TRIPLETS数据集的特点在于其高度结构化的数据格式和丰富的标注信息。每个数据实例包含查询ID、完整的Reddit问题、正面和负面文档的Wikipedia链接及其内容,以及相关的类别标签。数据集特别注重数据的无偏性,通过过滤与TREC-ToT 2024相关的条目,确保了训练数据的纯净性。此外,数据集还提供了详细的文档ID和URL信息,便于用户进行进一步的分析和模型训练。
使用方法
TOMT-KIS-TRIPLETS数据集的使用方法简便且灵活。用户可以通过`datasets`库直接下载完整数据集,并通过简单的代码操作访问数据集中的各个字段和实例。例如,用户可以使用`load_dataset`函数加载数据集,并通过索引访问特定行或列的数据。此外,数据集支持迭代操作,用户可以遍历整个数据集以进行批量处理。数据集的结构为JSONL格式,便于与其他工具和框架集成,进一步扩展其应用范围。
背景与挑战
背景概述
TOMT-KIS-TRIPLETS数据集是TOMT-KIS数据集的精炼子集,专注于已知项目搜索任务,旨在提升相关领域的应用效果。该数据集由Maik Fröbe、Eric Oliver Schmidt和Matthias Hagen等研究人员于2023年创建,主要基于Wikipedia和IMDb的数据源,利用SPARQL Wikipedia查询服务构建。其核心研究问题在于如何通过监督学习任务,提供直接链接到相关Wikipedia文章的标注数据,从而优化已知项目搜索的性能预测。该数据集在信息检索和自然语言处理领域具有重要影响力,特别是在已知项目搜索和查询性能预测任务中,为相关研究提供了高质量的数据支持。
当前挑战
TOMT-KIS-TRIPLETS数据集在构建过程中面临多重挑战。首先,从Reddit问题中提取并筛选出包含Wikipedia或IMDb链接的答案,需要复杂的URL提取和规范化处理,以确保数据的准确性和一致性。其次,利用SPARQL服务将IMDb URL映射到Wikipedia条目,增加了数据处理的复杂性。此外,为了避免训练数据中的偏差,数据集需要排除与TREC-ToT 2024评估集重叠的条目,这一过程涉及大量的数据匹配和过滤操作。这些挑战不仅考验了数据处理的技术能力,也对数据集的构建效率和最终质量提出了高要求。
常用场景
经典使用场景
TOMT-KIS-TRIPLETS数据集在信息检索和自然语言处理领域中具有广泛的应用,尤其是在已知项目搜索(Known-Item Search)任务中表现出色。该数据集通过提供从Reddit平台提取的问题及其对应的Wikipedia文章链接,为研究者提供了一个理想的实验平台。通过这种方式,研究者可以训练和评估模型在复杂查询场景下的表现,尤其是在用户记忆模糊或信息不完整的情况下,如何准确找到目标信息。
实际应用
在实际应用中,TOMT-KIS-TRIPLETS数据集可以广泛应用于搜索引擎优化、智能问答系统以及个性化推荐系统等领域。通过利用该数据集,开发者可以训练出更加智能的搜索引擎,帮助用户在信息模糊或记忆不完整的情况下快速找到所需内容。此外,该数据集还可以用于构建智能问答系统,提升系统在复杂查询场景下的响应速度和准确性,为用户提供更加精准的信息服务。
衍生相关工作
TOMT-KIS-TRIPLETS数据集自发布以来,已经衍生出多项经典研究工作。例如,基于该数据集的查询性能预测模型在QPP++ 2023会议上得到了广泛关注,相关研究不仅提升了模型在已知项目搜索任务中的表现,还为信息检索领域的其他任务提供了新的思路。此外,该数据集还被用于跨领域知识融合和多模态信息检索的研究,推动了相关技术的进一步发展。
以上内容由遇见数据集搜集并总结生成


