so101_pick_place_vial_v3
收藏Hugging Face2026-04-09 更新2026-04-10 收录
下载链接:
https://huggingface.co/datasets/indojin/so101_pick_place_vial_v3
下载链接
链接失效反馈官方服务:
资源简介:
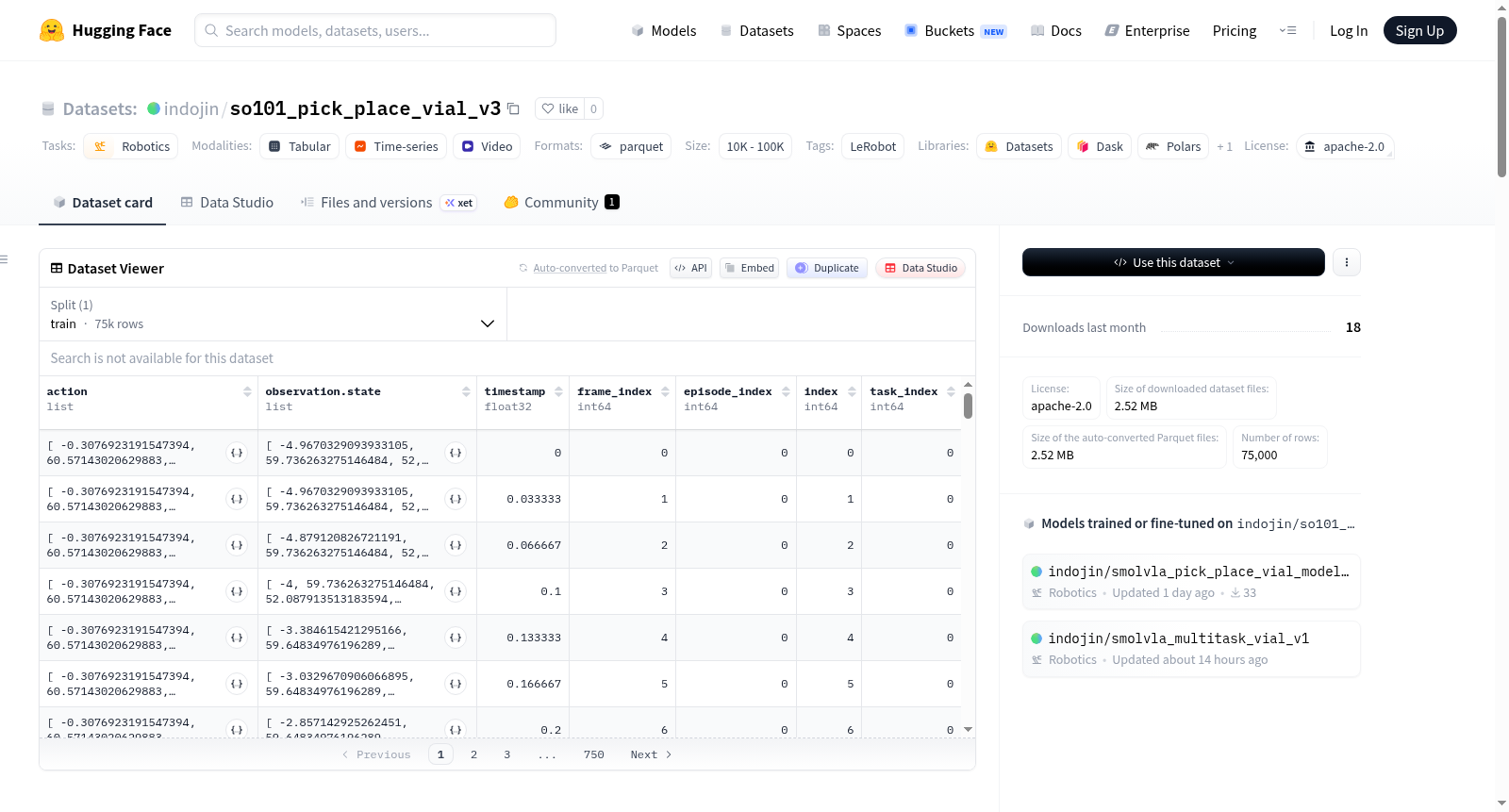
该数据集使用LeRobot创建,专为机器人技术任务设计。数据集遵循Apache 2.0许可协议。数据集结构包含100个完整片段,总计75000帧,涵盖2个不同任务。数据以分块形式存储,每块包含1000帧,数据文件总大小为100MB,视频文件总大小为200MB,视频帧率为30fps。数据集包含多种特征,包括动作(6个浮点型关节位置)、观测状态(6个浮点型关节位置)、前端观测图像(480x640x3的视频帧)、时间戳、帧索引、片段索引、索引和任务索引。数据存储为parquet格式,视频存储为mp4格式。适用于机器人控制、动作预测等任务的研究与开发。
创建时间:
2026-04-08
原始信息汇总
数据集概述
基本信息
- 数据集名称: so101_pick_place_vial_v3
- 创建工具: LeRobot (https://github.com/huggingface/lerobot)
- 许可证: Apache-2.0
- 任务类别: 机器人学
- 标签: LeRobot
数据集结构
- 总任务数: 2
- 总情节数: 100
- 总帧数: 75000
- 帧率: 30 FPS
- 数据块大小: 1000
- 数据文件格式: Parquet
- 数据文件大小: 100 MB
- 视频文件大小: 200 MB
- 数据分割: 训练集 (0:100)
数据文件路径
- 数据路径:
data/chunk-{chunk_index:03d}/file-{file_index:03d}.parquet - 视频路径:
videos/{video_key}/chunk-{chunk_index:03d}/file-{file_index:03d}.mp4
特征描述
动作
- 数据类型: float32
- 形状: [6]
- 名称:
- shoulder_pan.pos
- shoulder_lift.pos
- elbow_flex.pos
- wrist_flex.pos
- wrist_roll.pos
- gripper.pos
观测状态
- 数据类型: float32
- 形状: [6]
- 名称:
- shoulder_pan.pos
- shoulder_lift.pos
- elbow_flex.pos
- wrist_flex.pos
- wrist_roll.pos
- gripper.pos
观测图像(前视)
- 数据类型: video
- 形状: [480, 640, 3]
- 名称: height, width, channels
- 视频信息:
- 高度: 480
- 宽度: 640
- 编解码器: av1
- 像素格式: yuv420p
- 是否为深度图: false
- 帧率: 30
- 通道数: 3
- 包含音频: false
元数据
- 时间戳: float32, 形状 [1]
- 帧索引: int64, 形状 [1]
- 情节索引: int64, 形状 [1]
- 索引: int64, 形状 [1]
- 任务索引: int64, 形状 [1]
其他信息
- 代码库版本: v3.0
- 机器人类型: so_follower
- 主页: [More Information Needed]
- 论文: [More Information Needed]
- 引用: [More Information Needed]
搜集汇总
数据集介绍
构建方式
在机器人操作领域,数据集的构建往往依赖于实际物理系统的交互记录。so101_pick_place_vial_v3数据集借助LeRobot平台,通过so_follower型机器人执行拾取与放置小瓶的任务,系统性地采集了操作数据。整个数据集包含100个完整操作序列,总计75000帧数据,以每秒30帧的速率录制,并以分块形式存储为Parquet格式,确保了数据的高效组织与访问。
特点
该数据集的特点体现在其多模态数据结构的精心设计上。它不仅记录了机器人六个关节的位置状态与动作指令,还同步采集了前视摄像头的高清视频流,分辨率达640x480,为视觉与动作的联合分析提供了丰富素材。数据以分块形式组织,每块包含1000帧,便于流式处理与模型训练,同时支持任务索引与时间戳的精确追溯,为复杂操作策略的学习奠定了坚实基础。
使用方法
使用该数据集时,研究人员可通过LeRobot提供的可视化工具直观浏览数据内容。数据集以Parquet文件格式存储,可直接加载至支持该格式的数据处理框架中。每个数据块包含动作、状态、图像及元数据字段,用户可依据任务索引或帧索引提取特定操作序列,用于机器人模仿学习、强化学习或视觉运动控制等算法的训练与验证,推动机器人自主操作能力的提升。
背景与挑战
背景概述
在机器人操作领域,模仿学习作为一种关键方法,旨在通过示范数据训练智能体执行复杂任务。so101_pick_place_vial_v3数据集由HuggingFace的LeRobot项目创建,专注于拾放小瓶这一精细操作任务。该数据集包含100个完整演示片段,共计75000帧数据,整合了六自由度机械臂的关节状态、前视摄像头视频流及时间戳等多模态信息。其构建依托开源机器人平台,体现了社区驱动的研究范式,为机器人灵巧操作算法的开发与评估提供了标准化基准,推动了数据驱动机器人技术的实用化进程。
当前挑战
该数据集致力于解决机器人拾放操作中的模仿学习挑战,核心在于从多模态演示中提取有效策略,以应对真实世界中的物体抓取、姿态调整及放置精度等复杂问题。构建过程中,数据采集需确保机械臂动作的平滑性与任务成功率,同时处理高维视觉与状态数据的同步对齐,并管理大规模视频文件的存储与高效访问。此外,数据标注的缺失与任务多样性有限,可能限制模型在未见场景中的泛化能力,这些因素共同构成了数据集应用与扩展的主要难点。
常用场景
经典使用场景
在机器人操作领域,so101_pick_place_vial_v3数据集为机械臂抓取与放置任务提供了丰富的多模态数据。该数据集通过记录机械臂关节位置、前端摄像头视觉信息以及时间戳等特征,构建了完整的操作轨迹序列。研究人员可借此训练端到端的模仿学习或强化学习模型,使机器人能够精准执行拾取小瓶并放置到指定位置的动作,从而模拟工业装配或实验室自动化中的精细操作流程。
解决学术问题
该数据集有效应对了机器人模仿学习中数据稀缺与泛化能力不足的挑战。通过提供大量真实世界操作轨迹,它支持研究者探索从视觉感知到动作生成的映射关系,解决了动态环境下机械臂控制策略的样本效率问题。其多模态结构促进了状态表示学习的发展,为跨任务迁移与零样本泛化提供了实证基础,推动了机器人自主操作技术的理论进步。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在机器人模仿学习与视觉运动控制领域。研究者利用其序列化轨迹数据开发了基于Transformer的行为克隆模型,提升了长时程任务的规划稳定性。同时,结合前端视觉特征的工作探索了视觉伺服与深度预测网络的融合,增强了模型在遮挡与光照变化下的鲁棒性。这些进展进一步催生了开源机器人学习框架的生态扩展,促进了社区协作与算法标准化。
以上内容由遇见数据集搜集并总结生成


