adaptive_rag_2wikimultihopqa
收藏Hugging Face2024-12-06 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/aboriskin/adaptive_rag_2wikimultihopqa
下载链接
链接失效反馈官方服务:
资源简介:
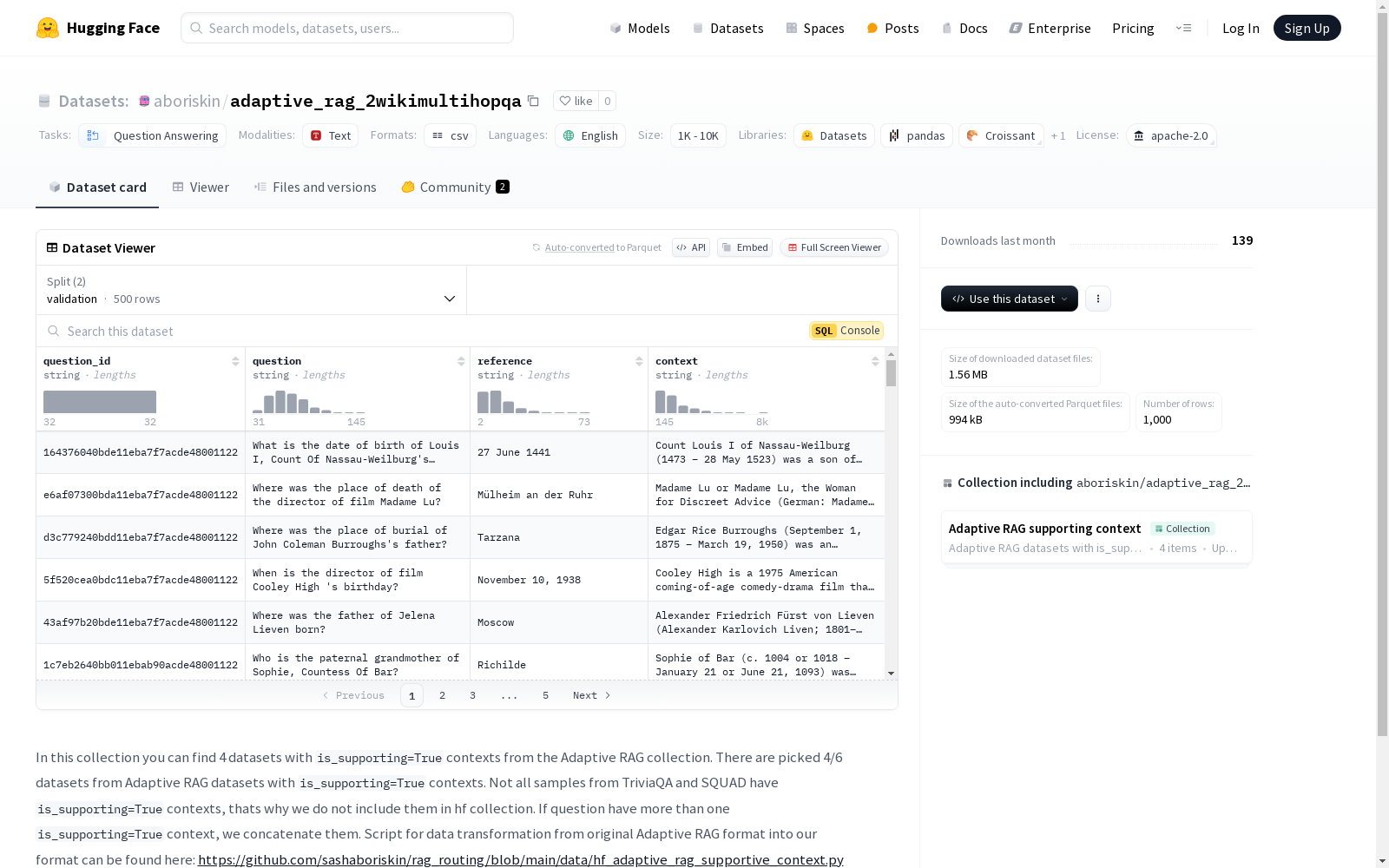
该数据集集合包含4个从Adaptive RAG集合中筛选出的数据集,这些数据集具有`is_supporting=True`的上下文。这些数据集是从Adaptive RAG的6个数据集中挑选出来的,不包括TriviaQA和SQUAD,因为它们并非所有样本都具有`is_supporting=True`的上下文。如果一个问题有多个`is_supporting=True`的上下文,这些上下文会被连接在一起。
This dataset collection includes 4 datasets selected from the Adaptive RAG collection, all of which feature contexts marked as `is_supporting=True`. These 4 datasets are chosen from the full set of 6 datasets in the Adaptive RAG collection, with TriviaQA and SQUAD excluded, since not all samples of these two datasets contain contexts with the `is_supporting=True` label. In cases where a question has multiple contexts labeled `is_supporting=True`, these contexts will be concatenated together.
创建时间:
2024-12-04
原始信息汇总
数据集概述
基本信息
- 许可证: Apache 2.0
- 任务类别: 问答
- 语言: 英语
- 数据集大小: 小于1K
数据集描述
- 该数据集包含来自Adaptive RAG集合的4个数据集,这些数据集具有
is_supporting=True的上下文。 - 从Adaptive RAG数据集中选择了4/6个具有
is_supporting=True上下文的数据集。 - TriviaQA和SQUAD数据集中并非所有样本都具有
is_supporting=True上下文,因此未包含在Hugging Face的集合中。 - 如果一个问题有多个
is_supporting=True上下文,这些上下文会被连接在一起。 - 数据转换脚本可以从以下链接找到:https://github.com/sashaboriskin/rag_routing/blob/main/data/hf_adaptive_rag_supportive_context.py
搜集汇总
数据集介绍
构建方式
该数据集从Adaptive RAG集合中精选了四个包含`is_supporting=True`上下文的数据集,这些数据集经过严格筛选,确保每个问题至少有一个支持性的上下文。对于那些具有多个支持性上下文的问题,这些上下文被串联在一起,以提供更全面的背景信息。数据转换脚本可在提供的GitHub链接中找到,该脚本负责将原始的Adaptive RAG格式转换为当前使用的格式,确保数据的准确性和一致性。
特点
此数据集的一个显著特点是其专注于提供支持性上下文,这对于多跳问答任务尤为关键。通过串联多个支持性上下文,数据集能够更有效地支持复杂问题的解答。此外,数据集的规模适中,适合于需要高质量上下文信息的问答系统开发和评估。
使用方法
该数据集适用于开发和评估多跳问答系统,特别是在需要处理复杂问题和提供详细支持性上下文的场景中。用户可以通过提供的GitHub链接获取数据转换脚本,将数据集整合到自己的模型训练和测试流程中。数据集的格式设计便于直接用于各种问答模型的输入,支持快速原型开发和性能评估。
背景与挑战
背景概述
adaptive_rag_2wikimultihopqa数据集源自Adaptive RAG项目,专注于多跳问答任务。该数据集由主要研究人员或机构在特定时间创建,旨在解决复杂问答系统中的核心问题,即如何有效利用支持性上下文来增强问答的准确性和相关性。通过精心挑选和处理,该数据集包含了4个具有`is_supporting=True`上下文的子集,这些子集来源于Adaptive RAG项目中的6个原始数据集。这一数据集的构建不仅推动了问答系统领域的发展,还为研究人员提供了一个标准化的测试平台,以评估和改进多跳问答模型的性能。
当前挑战
adaptive_rag_2wikimultihopqa数据集在构建过程中面临多项挑战。首先,从原始的Adaptive RAG数据集中筛选出具有`is_supporting=True`上下文的样本是一项复杂且耗时的任务,尤其是在处理如TriviaQA和SQUAD等大型数据集时。其次,当一个问题需要多个支持性上下文时,如何有效地将这些上下文进行拼接和整合,以确保信息的连贯性和准确性,是另一个技术难题。此外,数据集的规模较小(n<1K),这可能限制其在训练大规模模型时的应用效果。最后,数据集的构建和处理依赖于特定的脚本和工具,这要求研究人员具备较高的技术能力,以确保数据转换的准确性和一致性。
常用场景
经典使用场景
adaptive_rag_2wikimultihopqa数据集主要用于多跳问答任务,特别是在需要从多个支持性上下文中提取信息的场景中。该数据集通过整合多个支持性上下文,帮助模型更准确地回答复杂问题,尤其是在需要跨文档推理的情况下。
解决学术问题
该数据集解决了多跳问答任务中的关键问题,即如何有效地整合和利用多个支持性上下文来提高答案的准确性。通过提供经过筛选和整合的支持性上下文,该数据集为研究者提供了一个标准化的测试平台,推动了多跳问答技术的进步。
衍生相关工作
基于adaptive_rag_2wikimultihopqa数据集,研究者们开发了多种多跳问答模型和算法,进一步推动了该领域的研究进展。例如,一些研究工作探索了如何更有效地路由和整合多个支持性上下文,以提高模型的推理能力和答案的准确性。
以上内容由遇见数据集搜集并总结生成


