MM-Instruct
收藏Hugging Face2024-06-27 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/jjjjh/MM-Instruct
下载链接
链接失效反馈官方服务:
资源简介:
MM-Instruct是一个大规模的视觉指令-回答对数据集,旨在提升大型多模态模型(LMMs)的指令遵循能力。数据集包含多种类型的指令,如创意写作、总结和图像分析,以帮助LMMs更好地理解和响应复杂的用户请求。数据集通过自动化流程生成,包括指令生成、图像匹配、回答生成和数据过滤,确保数据质量。数据集包含234k指令-回答对,分为训练集和测试集。
MM-Instruct is a large-scale visual instruction-response pair dataset designed to enhance the instruction-following capabilities of large multimodal models (LMMs). This dataset covers a wide range of instruction types, including creative writing, summarization, and image analysis, to help LMMs better understand and respond to complex user queries. The dataset is generated through an automated pipeline comprising instruction generation, image matching, response generation, and data filtering to ensure data quality. It contains 234,000 instruction-response pairs, which are split into training and test sets.
创建时间:
2024-06-27
原始信息汇总
数据集概述
MM-Instruct 是一个大规模、多样化和高质量的视觉指令-答案对数据集,旨在增强大型多模态模型(LMMs)在实际应用中的指令遵循能力。该数据集超越了简单的问题回答或图像描述,包含了广泛的指令类型,如创意写作、总结和图像分析,推动LMMs更好地理解和响应复杂的用户请求。
动机
现有的视觉指令数据集通常专注于有限的指令类型,如问答,这阻碍了能够处理现实世界指令多样性的大型多模态模型的发展。MM-Instruct通过提供丰富多样的指令-答案对,促进了具有增强指令遵循能力的LMMs的开发,以应用于实际场景。
数据收集过程
MM-Instruct 是通过一个自动化流程生成的,利用了现有的LLMs:
- 指令生成:从有限的种子指令开始,ChatGPT根据详细的图像描述和现有图像描述数据集中的上下文示例生成多样化的指令。
- 图像匹配:这些指令与使用预训练的CLIP模型匹配的相关图像配对。
- 答案生成:一个强大的LLM为指令-图像对生成答案,使用详细的图像描述以确保一致性。
- 数据过滤:启发式方法过滤掉低质量或不相关的实例,以确保数据集质量。
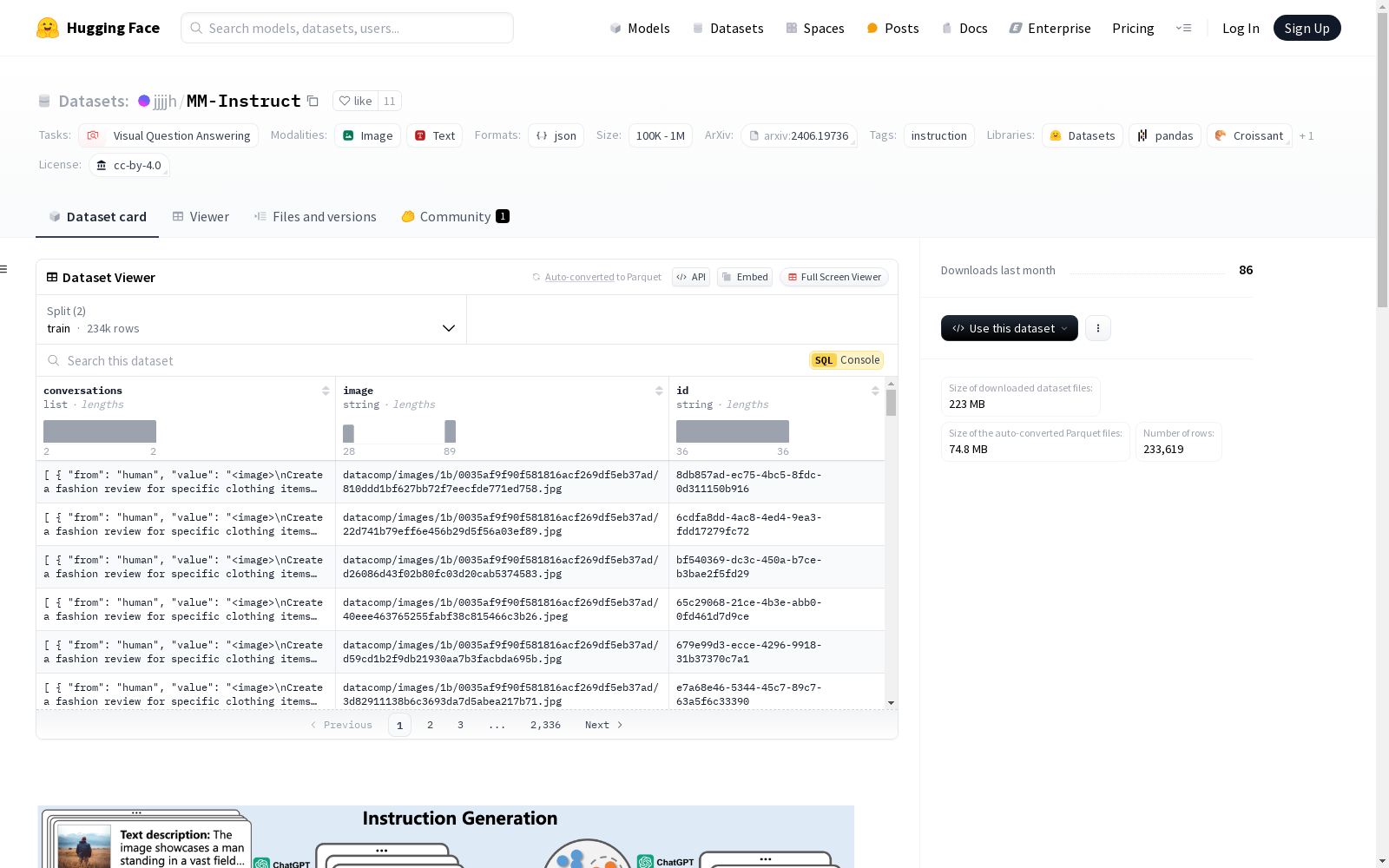
数据集结构
MM-Instruct 包含234k个指令-答案对,涵盖293种不同的指令。每个数据点包括:
- 图像:视觉输入。
- 指令:与图像相关的任务或请求。
- 答案:对指令的响应。
数据集详情
- train.json:234k个训练示例
- test.json:99个测试示例
- images.zip:99个测试图像
搜集汇总
数据集介绍
构建方式
MM-Instruct数据集的构建过程采用了自动化流水线技术,充分利用了现有的大型语言模型(LLMs)。首先,通过ChatGPT从有限的种子指令中生成多样化的指令,并结合现有图像描述数据集中的详细图像描述和上下文示例进行引导。接着,使用预训练的CLIP模型将这些指令与相关图像进行匹配。随后,利用强大的LLM生成与指令-图像对相对应的答案,并通过详细的图像描述确保答案与图像的匹配度。最后,通过启发式方法过滤掉低质量或不相关的实例,以确保数据集的高质量。
特点
MM-Instruct数据集以其多样性和高质量著称,涵盖了23.4万条指令-答案对,涉及293种不同的指令类型。这些指令不仅包括传统的问答任务,还涵盖了创意写作、摘要生成和图像分析等多种复杂任务,旨在推动大型多模态模型(LMMs)在实际应用中的指令跟随能力。数据集中的每个数据点均包含图像、指令和答案三个部分,确保了数据的完整性和实用性。
使用方法
MM-Instruct数据集的使用方法主要围绕训练和测试大型多模态模型展开。用户可以通过加载train.json文件获取23.4万条训练样本,用于模型的训练和微调。测试集则包含99条测试样本,用户可以通过test.json文件加载这些样本,并使用images.zip中的图像进行模型性能的评估。此外,数据集还提供了详细的图像来源信息,用户可以根据需要进一步探索或扩展数据集。
背景与挑战
背景概述
MM-Instruct数据集由Jihao New等研究人员于2024年创建,旨在提升大型多模态模型(LMMs)在真实场景中的指令遵循能力。该数据集通过引入多样化的指令类型,如创意写作、摘要生成和图像分析,超越了传统的视觉问答和图像描述任务。其核心研究问题在于如何通过丰富的指令-答案对,推动LMMs更好地理解和响应用户的复杂需求。MM-Instruct的发布为多模态模型的研究提供了重要的数据支持,显著提升了模型在实际应用中的表现。
当前挑战
MM-Instruct数据集在构建过程中面临多重挑战。首先,生成多样化的指令需要克服现有数据集中指令类型单一的问题,确保指令涵盖广泛的真实场景需求。其次,图像与指令的匹配过程依赖于预训练的CLIP模型,如何确保匹配的准确性和相关性成为关键难题。此外,答案生成的质量控制也至关重要,需通过启发式过滤机制剔除低质量或无关的数据,以保证数据集的高质量。这些挑战共同推动了多模态模型在复杂指令理解和执行能力上的进步。
常用场景
经典使用场景
MM-Instruct数据集在视觉问答和指令跟随任务中展现了其独特的价值。通过提供多样化的视觉指令-答案对,该数据集被广泛应用于训练和评估大型多模态模型(LMMs),使其能够更好地理解和执行复杂的用户指令。这些指令不仅限于简单的问答,还包括创意写作、图像分析和总结等任务,极大地扩展了模型的应用范围。
衍生相关工作
MM-Instruct数据集的发布催生了一系列相关研究工作,特别是在多模态模型指令跟随能力的提升方面。基于该数据集,研究者们开发了多种新型模型架构和训练方法,进一步推动了多模态模型在复杂任务中的应用。此外,该数据集还为视觉问答、图像生成和文本生成等领域的交叉研究提供了新的视角和实验平台。
数据集最近研究
最新研究方向
在视觉指令跟随领域,MM-Instruct数据集的推出标志着多模态模型(LMMs)研究的一个重要里程碑。该数据集通过引入多样化的指令类型,如创意写作、摘要生成和图像分析,显著扩展了现有视觉指令数据集的边界。这种创新不仅推动了模型在复杂指令理解与响应能力上的提升,还为实际应用场景中的多模态交互提供了更为丰富的训练资源。当前的研究热点集中在如何利用MM-Instruct进一步提升LMMs的泛化能力和指令跟随的精确性,特别是在处理开放域和跨模态任务时。这一方向的研究有望为智能助手、教育技术以及内容创作等领域带来革命性的影响。
以上内容由遇见数据集搜集并总结生成


